简介:数据同步技术(此处指CDC)发展迅速,目前主流的同步技术是使用Confluen-platform,他基于Kafaka开发,包含你能想到的任何组件。
核心是kafka connect,kafka connect 通过两种类型的连接器工作:
- 源连接器——摄取整个数据库并将表更新流式传输到 Kafka 主题。源连接器还可以从您的所有应用程序服务器收集指标并将其存储在 Kafka 主题中,从而使数据可用于低延迟的流处理。
- 接收器连接器——将来自 Kafka 主题的数据传送到二级索引(如 Elasticsearch)或批处理系统(如 Hadoop)以进行离线分析。
原文:
- “Kafka Connect includes two types of connectors:
- Source connector – Ingests entire databases and streams table updates to Kafka topics. A source connector can also collect metrics from all your application servers and store these in Kafka topics, making the data available for stream processing with low latency.
- Sink connector – Delivers data from Kafka topics into secondary indexes such as Elasticsearch, or batch systems such as Hadoop for offline analysis.”
比如著名的Source Connector有:Debezium connector for MySQL,著名的Sink Connector有Elasticsearch Service Sink Connector
基于以上组件,可以实现MySQL高效实时同步数据到Elasticsearch。
目前有两种使用方式:
第一种:直接使用kafka,kafka connect,手动安装connector plugins(连接器插件)
【本文就是基于第一种方式安装】
第二种:安装confluent platform,然后使用confluent hub安装
软件版本信息
Debezium:1.9.4.Final
MySQL:5.7.x.
Elasticsearch:7.15.1
confluentinc-kafka-connect-elasticsearch:13.1.0
1、下载zip包,手动安装(即不使用confluent platform安装cdc)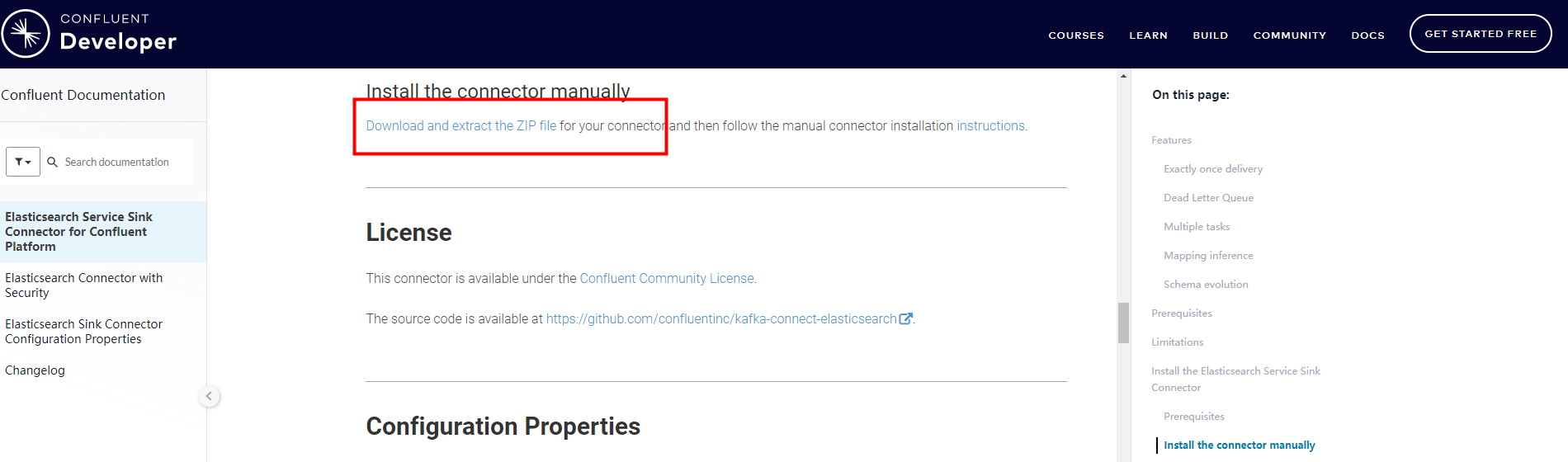
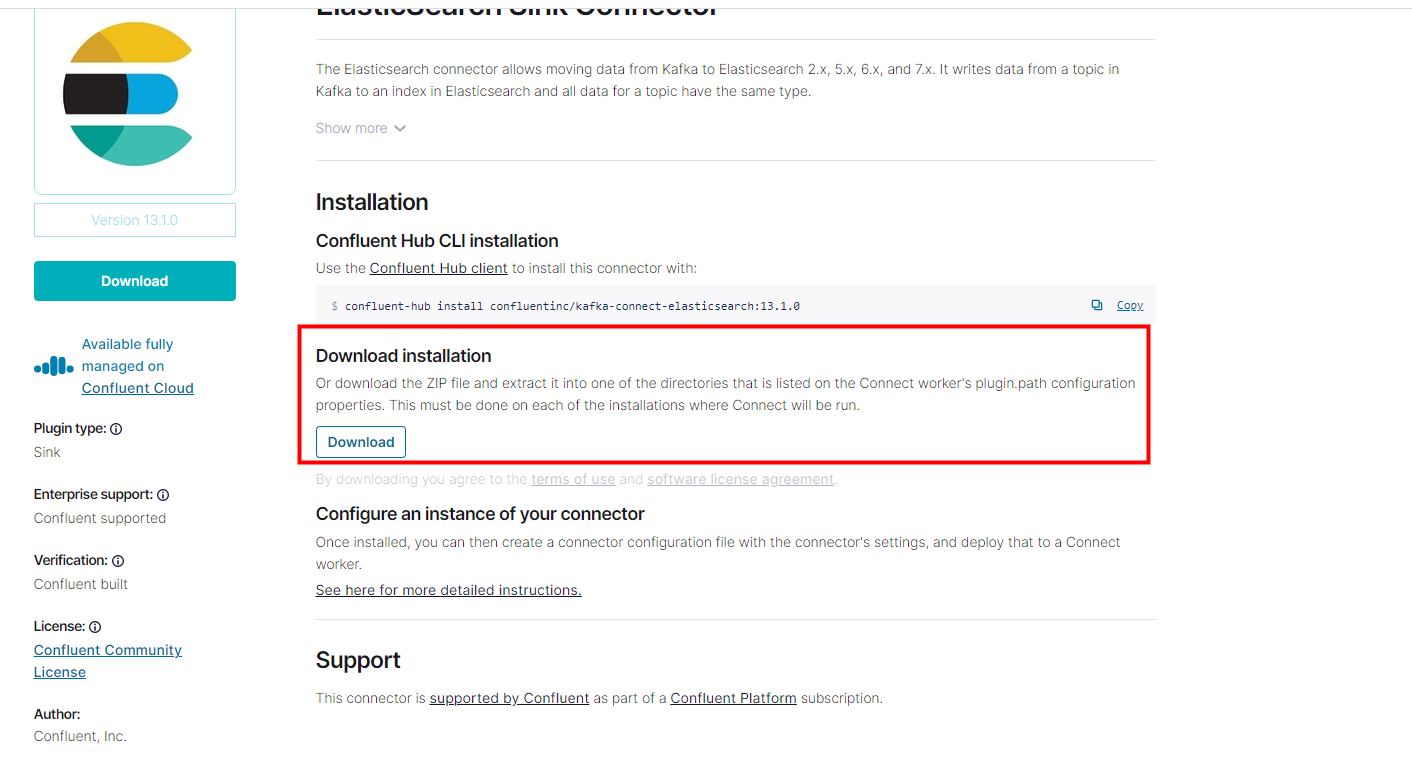
--将下载的zip包上传到 /usr/local/kafka/kafka_2.13-3.2.0/libs/confluent 目录下,解压--
修改connect-distributed.properties配置文件的plugin.path如下:
plugin.path=/usr/local/kafka/kafka_2.13-3.2.0/libs,/usr/local/kafka/kafka_2.13-3.2.0/libs/debezium/debezium-connector-mysql,/usr/local/kafka/kafka_2.13-3.2.0/libs/confluent/confluentinc-kafka-connect-elasticsearch-13.1.0
2、编写配置文件:
创建文件elasticsearch-sink.json,内容为:
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "goods.goods.t_sku",
"key.ignore": "false",
"connection.url": "http://127.0.0.1:9200",
"name": "elasticsearch-sink",
"transforms": "unwrap,key",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "true",
"transforms.unwrap.delete.handling.mode": "drop",
"transforms.key.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.key.field": "id",
"transforms.changetopic.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.changetopic.regex": "(.*)",
"transforms.changetopic.replacement": "$1"
}
}
参考官方文档
"transforms.unwrap.drop.tombstones": "true",
"transforms.unwrap.delete.handling.mode": "drop",
这么配置到sink中就可以实现mysql删除数据,然后ealsticsearch中也删除改数据。
看了官方文档,暂时没有理解配置的说明。
3、重启kafka-connect
重启kafka-connect的步骤:
ps- aux | grep 8083 或者 ps- aux | grep ConnectDistributed 或者 jps 找到ConnectDistributed对应的pid kill pid 不要使用kill -9 pid 然后重新执行: ./bin/connect-distributed.sh -daemon config/connect-distributed.properties 查看结果: netstat -nltp | grep 8083 查看加载的插件: curl http://localhost:8083/connector-plugins 查看连接器: curl http://localhost:8083/connectors 加入source连接器: curl -d @"connect-mysql-source.json" -H"Content-Type: application/json" -X POST http://localhost:8083/connectors 加入sink连接器: curl -d @"elasticsearch-sink.json" -H"Content-Type: application/json" -X POST http://localhost:8083/connectors 再次查看连接器 curl http://localhost:8083/connectors以上就可以重启连接器,并查看kafka connect 是否工作正常 如果,连接器已存在,需要删除重新加入,则是如下命令删除:
curl -X DELETE http://localhost:8083/connectors/elasticsearch-sink
重新加入sink连接器:
curl -d @"elasticsearch-sink.json" -H"Content-Type: application/json" -X POST http://localhost:8083/connectors
4,查看elasticsearch已经生成了索引名称为goods.goods.t_sku的索引,并同步成功了数据。
5、在mysql的goods.t_sku表中增加一条数据,同时观察索引goods.t_sku中也会增加一条数据。成功!
===========需要注意的点=======
一、transforms
(1)RegexRouter :可以灵活对kafka的topic进行区分管理
(2)ExtractNewRecordState :如果没有,输入数据会包含:before、after记录修改前对比信息以及元数据信息(source,op,ts_ms等)。这些信息在后续数据写入Elasticsearch是不需要的。(注意结合自己业务场景)。
(3)ExtractField :实现id和elasticsearch的_id一致,配合 "key.ignore": "false"一起使用,必须配置false,否则es生成的_id不是mysql表的id,这样是不能实现更新和删除的
二、ES的Mapping设置
1、自定义mapping,直接在同步之前创建好
2、动态映射mapping,可参考这篇文章
比如本例子中:mysql约定所有时间类型字段后缀以_time结尾,然后使用dynamic_templates指定es的时间mapping为date类型
PUT /goods.goods.t_sku {"mappings": {"date_detection": false,"dynamic_templates": [{"dates": {"match": ".*_time","match_pattern": "regex","mapping": {"type": "date"}}}]} }
给索引设置alias,使用起来了更灵活、便捷
POST _aliases {"actions": [{"add": {"index": "goods.goods.t_sku","alias": "goods.goods.t_sku_alias"}}] }
参考一:kafka connect
参考二:debezium
参考三:Elasticsearch Service Sink
==部署了这个cdc从mysql同步数据到elasticsearch的应用后,2核4G的虚拟机已经到极限了!==