
全文摘要
Qwen2.5系列模型经过预训练和后处理两个阶段的改进,在高质量预训练数据集的基础上,通过多阶段强化学习等技术进行后处理,提高了人类偏好、长文本生成、结构数据分析和指令遵循等方面的能力。该系列模型提供了多种配置,包括基于基础模型和指令微调的模型,参数量从0.5B到72B不等,并且还提供了量化版本的指令微调模型。此外,该系列模型在各种基准测试中表现出色,超越了许多开源和专有模型,并具有良好的成本效益。Qwen2.5模型还被用于训练专门化的模型,如数学、编码器和多模态模型等。
论文地址:https://arxiv.org/pdf/2412.15115
github: https://github.com/QwenLM/Qwen3/tree/v2.5
huggingface: https://huggingface.co/Qwen
modelscope: https://modelscope.cn/organization/qwen

论文方法
方法描述
本文提出了基于Transformer架构的语言模型Qwen2.5系列,包括密集模型和MoE模型。密集模型采用了Grouped Query Attention(GQA)、SwiGLU激活函数、Rotary Positional Embeddings(RoPE)以及QKV bias等技术来提高模型性能。MoE模型则使用了专门的MoE层替换标准的feed-forward网络层,并通过fine-grained expert segmentation和shared experts routing等策略提高了模型能力。
方法改进
在预训练阶段,作者采用了更加高质量的数据集和数据混合策略,包括更好的控制令牌和数学代码数据集,以及更好的合成数据。同时,他们还引入了长上下文预训练,将初始预训练阶段的上下文长度扩展到4,096个标记,最终扩展到32,768个标记。
在post-training阶段,作者进行了两个关键的改进:一是增加了监督式微调数据覆盖范围,包括长期序列生成、数学问题解决、编程、指令遵循、结构理解、逻辑推理、跨语言转移和稳健系统指令等方面;二是采用了两阶段强化学习,分为离线RL和在线RL,以进一步提升模型的性能。
解决的问题
该研究主要解决了自然语言处理中的几个关键问题,如长期序列生成、数学问题解决、编程、指令遵循、结构理解、逻辑推理、跨语言转移和稳健系统指令等。此外,作者还针对模型的效率和可解释性进行了优化,例如通过长上下文预训练和多阶段强化学习等方式来提高模型的能力和效率。这些改进使得Qwen2.5系列模型能够更好地适应各种自然语言处理任务,并具有更高的准确性和鲁棒性。
论文实验
本文主要介绍了大规模预训练语言模型的评价方法和结果。作者通过一系列的实验来比较不同规模的预训练模型在各种任务上的表现,并对其进行了详细的分析和总结。
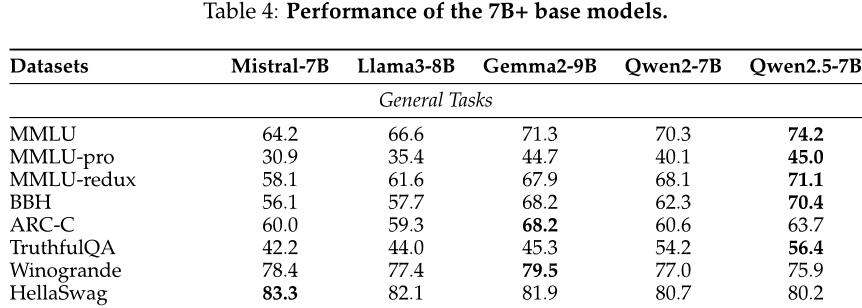
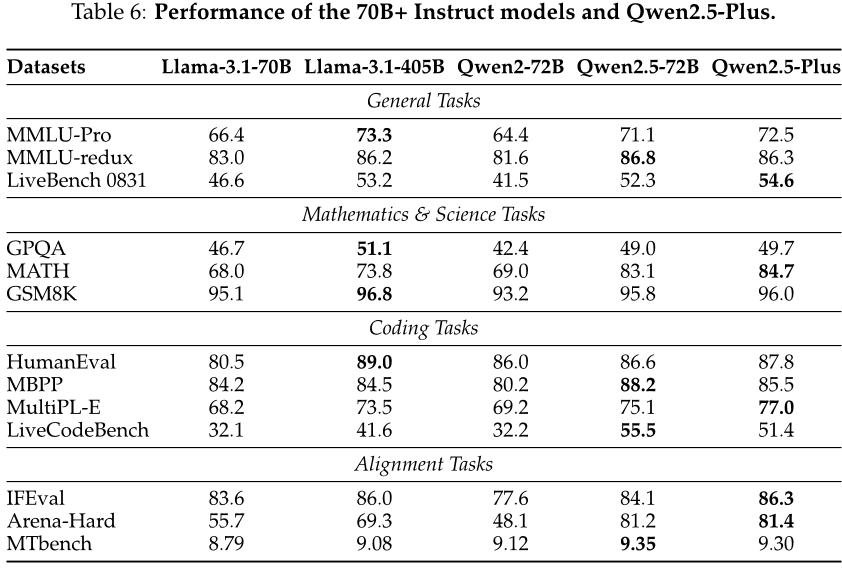
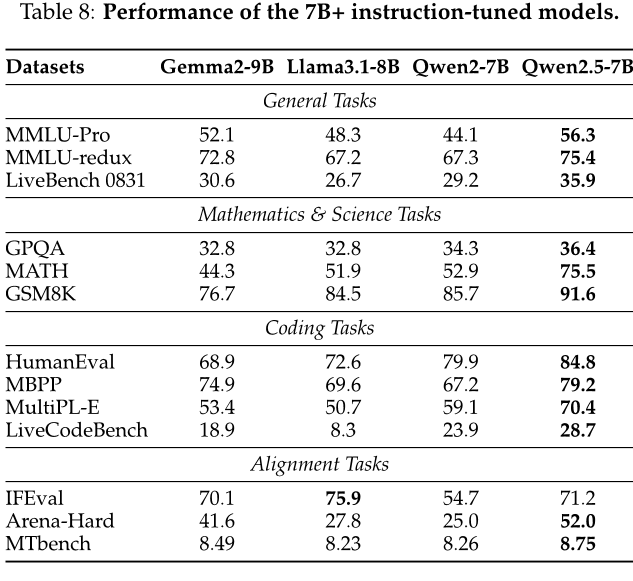
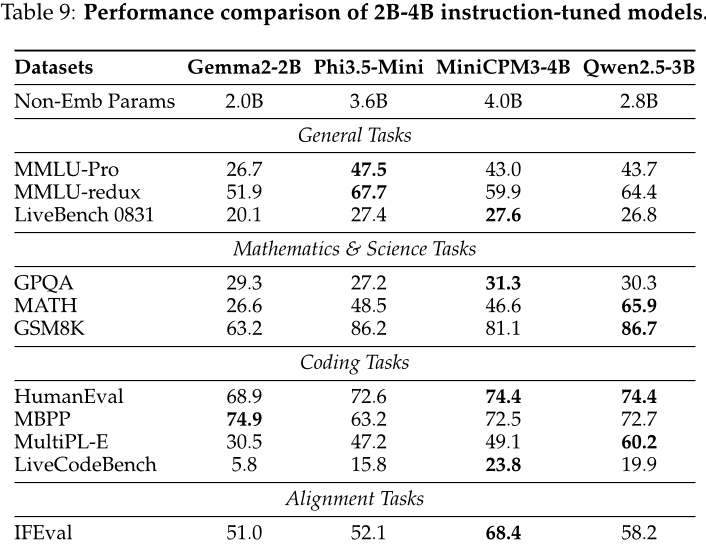
首先,作者对大规模预训练语言模型进行了基础能力的测试,包括自然语言理解、编程、数学、科学知识、推理等方面。他们使用了多个公开数据集来评估这些模型的表现,并将它们与其他领先的开源重量级指令引导模型进行了比较。结果显示,作者提出的Qwen2.5系列模型在各个基准上都表现出色,特别是在小规模模型方面具有很强的优势。
其次,作者还对大规模预训练语言模型的长上下文处理能力进行了测试。他们使用了三个不同的基准来评估模型在这个方面的表现,并将其与其他现有的开源和专有的长上下文模型进行了比较。结果显示,作者提出的Qwen2.5系列模型在这方面也表现出色,尤其是在超长上下文的情况下。
最后,作者还对大规模预训练语言模型的奖励模型进行了评估。他们使用了多个不同的基准来评估模型在这个方面的表现,并将其与其他现有的奖励模型进行了比较。结果显示,目前还没有一种有效的奖励模型评估方法,因此需要进一步研究这个问题。
总的来说,本文提供了一个全面的大规模预训练语言模型评估框架,并对其中的一些关键问题进行了深入的研究和探讨。这对于改进和优化大规模预训练语言模型具有重要的指导意义。

论文总结
文章优点
- 提出了Qwen2.5模型,是目前最先进的大型语言模型之一。
- 在预训练阶段采用了大规模文本数据,并在多个任务上进行了微调,取得了优异的表现。
- 通过各种技术手段(如超参数调整、后处理等)进一步提高了模型性能。
- 模型具有高度可扩展性和灵活性,能够适应不同的应用场景。
方法创新点
- 引入了多模式融合技术和监督强化学习方法,使得模型能够在更广泛的领域中表现出色。
- 利用了大规模文本数据进行预训练,并使用小规模数据进行微调,降低了计算成本和时间开销。
- 运用了多种技术手段来提高模型性能,包括优化算法、超参数调整、后处理等。
未来展望
- 将继续研究如何提高模型的泛化能力和稳定性,以应对更加复杂的场景。
- 将探索如何将模型应用于更多的实际问题中,例如自然语言推理、机器翻译等领域。
- 将尝试开发新的技术手段,以便更好地利用大规模数据集和硬件资源,从而实现更高的性能提升。