关于图的算法——kruskal算法,prime算法,和Dijkstra算法
对于这三个算法按照作用分又可以分成两种:
kruskal算法和prime算法是用来计算整张图的最小生成树的总权值最小
而Dijkstra算法是用来计算单原点到其他节点的最短路径的
我们先来介绍kruskal算法和prime算法
kruskal算法
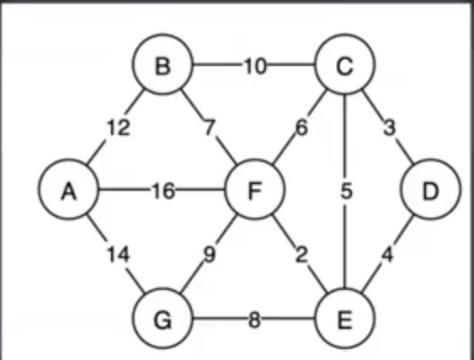
算法逻辑:
这里kruskal算法就是对边做操作,这里的操作对象是边
这里对图的约束只有:符合最小生成树的原理
在这整个图中找出最短的那一条边,然后激活他,再找下一条最短的边,激活他,如果这条边激活会导致成环的话就条过直到激活n-1条边
(n指节点数)。
代码实现:
这里我们用邻接矩阵来做为代码存储图的结构,用边集数组来存储每一条边
边集数组的定义如下:
typedef struct edgeset {
int begin;//表示这条边的起始节点的下标
int end; //表示这条边的结束节点的下标
int weight;// 表示条边的权值
}edgeset;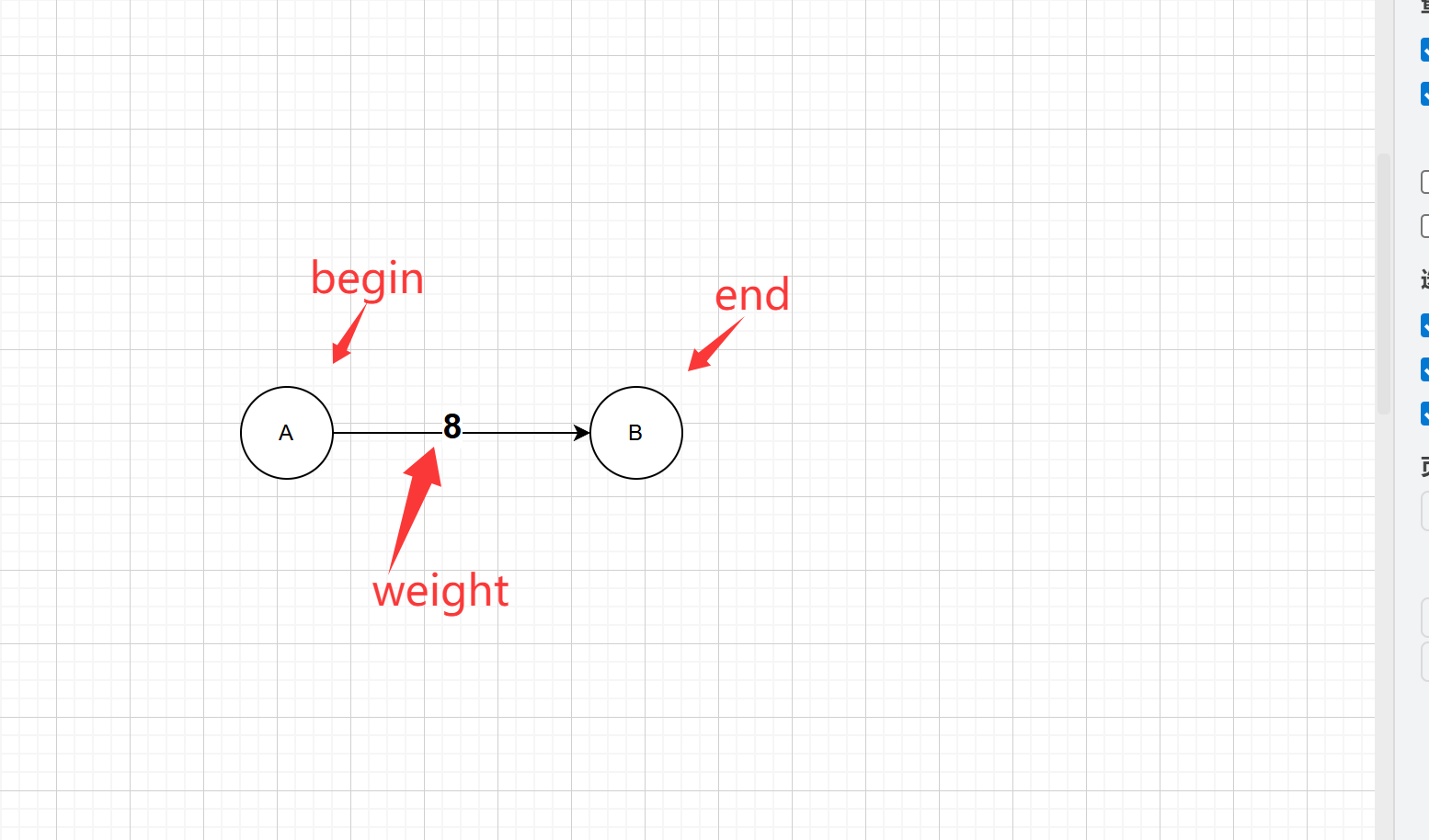
邻接矩阵的定义可以看我之前的博客
因为计算机不像人一样可以一眼就看出那个边最小,所以在开始这个算法之前要先存储这些边并对这些边进行排序,所以我们要引入两个函数
initEdgeSet和sortEdgeSet
void initEdgeSet(const mgraph* graph, edgeset* edges)
{
int k = 0;
for(int i=0;iedgenum;i++){
for (int j = i + 1; j < graph->edgenum; j++) {
if (graph->edge[i][j] > 0) {
edges[k].begin = i;
edges[k].end = j;
edges[k].weight = graph->edge[i][j];
k++;
}
}
}
} 这个就是把邻接矩阵的边的内容赋值给边集数组。
void sortEdgeSet(edgeset* edges, int num)
{
edgeset tmp;
for (int i = 0; i < num; ++i) {
for (int j = i + 1; j < num; ++j) {
if (edges[j].weight < edges[i].weight) {
memcpy(&tmp, &edges[i], sizeof(edgeset));
memcpy(&edges[i], &edges[j], sizeof(edgeset));
memcpy(&edges[j], &tmp, sizeof(edgeset));
}
}
}
}这个就是模拟人眼找最小,先给边集数组排序了
kruskal算法本体分析,其中要包含一个并查集的算法用来确定两条边的是否会成环。
思路分析: 1.先定义一个并查集,并且是用qiuck union 的算法,并且初始化这个并查集 2.其中是要找根的,所以里面还要内置一个findroot的函数 3.kruskal算法的思路:从之前已经排好顺序的边集数组中从小到大的分析。 分析包括:首先这条边加上以后不会导致边成环,不会构成环(这里就是要用到qiuck,union的并查集) 不会变成环的原因,一开始他们都只是自己是自己的根,然后连上了就会有一个共同的根,就比如: B C F 之间已经连上了,在链BF的话,首先找B的根就是他自己,然后找F的根, 发现还是B ,这样就避免了成环了 并查集就是find和union的作用,这里取他find的作用,就是看是否是在一个组中 如果已经到了n-1条边就其他的就可以直接break掉 总结,kruskal算法就是利用了贪心的性质,加上禁止成环的限制,使得总权重最小 */
其中的内置函数其实是用来辅助并查集的
static int findroot(int* uset, int a) {
while (uset[a] != a) {
a = uset[a];
}
return a;
}int KruskalMGraph(const edgeset* edges, int num, int node_num, edgeset* result)
{
//模拟一个并查集的qiuck union
int* uset= malloc(sizeof(int) * node_num);
int count = 0;
int sum = 0;
if (uset == NULL) {
printf("malloc failed\n");
return -1;
}int a, b;
int roota, rootb;
//这里并查集的作用对象是顶点
for (int i = 0; i < node_num; i++) {
uset[i] = i;
}
for (int i = 0; i < num; i++) {
if (count == node_num-1) {
break;
}
a = edges[i].begin;
b = edges[i].end;
roota = findroot(uset, a);
rootb = findroot(uset, b);
if (roota != rootb) {
result[count].begin = a;
result[count].end = b;
result[count].weight = edges[i].weight;
sum += edges[i].weight;
count++;
uset[roota] = rootb;
}
}
free(uset);
return sum;
}prime算法
prime算法就是与kruskal算法不同的点就是观察的角度不一样, prime算法观察的角度是顶点,但是kruskal算法看的是边
对于prime算法,他并不需要其他辅助函数,所以只有一个主函数
算法逻辑:
/*先文字描述一下思路:
*1.先解释一下参数的作用
* graph 通用的存储边的结构,就是邻接矩阵
* starV就是开始的节点
* result数组就是用来存放符合条件的边的
*2.先创建这个表格的雏形
* 光有上面的参数还是不够还要有
* cost数组 用来存储从已知节点来观察的话可看到的边的权值
* sum用来返回这个总权值的
* mark数组用来表示这个节点是否已经被激活了
* visited数组用来表示上一个激活到这个点的,最后可以用来表示路径
* 3.初始化
* 对cost数组初始化为INF和visited数组的初始化其中-1表示上面没人访问,
* 其他的数组分别对应下标
* 4.操作:对A那一行做操作,先更新cost数组,如果有变化就更新visited数组,
* 然后再更新A的那一行
* 5.大循环,后面的行都遵循在这一行中找到最小值,然后激活这个节点,
* 然后以这个节点作为观察点,如果发现有比以前到同一个点更小的边就
* 更新cost数组和visited数组
* 6.释放空间
*/代码实现:
int PrimMGraph(const mgraph* graph, int startV, edgeset* result)
{
int* visited = malloc(sizeof(int) * graph->nodenum);
int* cost = malloc(sizeof(int) * graph->nodenum);
int* mark = malloc(sizeof(int) * graph->nodenum);
int sum;
int n = graph->nodenum;
/*其实这里不用初始化,下面的cost[i]=graph->edge[starV][i]就是已经初始化了
,因为这个其实不是表格,而只是一个只有一行的数组而已*/
/*for (int i = 0; i < n; i++) {
cost[i] = INF;
visited[i] = -1;
}*/
for (int i = 0; i < n; i++) {
cost[i] = graph->edge[startV][i];
if (cost[i] < INF) {
visited[i] = startV;
}
else {
visited[i] = -1;
}
mark[i] = 0;
}
mark[startV] = 1;
sum += cost[startV];
int mini = INF;
/*这里k是记录上一行中最小的,也是记录mark的下标的,
还是记录下一行是以什么为参照的*/
int k = 0;
for (int i = 0; i < n; i++) {
mini = INF;
k = 0;
/*这个循环是找出最小值的*/
for (int j = 0; j < n; j++) {
if (mark[i] == 0 && cost[i] < mini) {
mini = cost[i];
k = j;
}
}
//sum在前面为什么不加上以为刚开始初始化的时候都只是一个顶点而已
// ,而不是一条边
result[i].begin = visited[k];
result[i].end = k;
result[i].weight = mini;
sum += mini;
mark[k] = 1;
/*这个循环才是更新cost数组和visited数组的*/
for (int j = 0; j < n; j++) {
if (graph->edge[k][j] < cost[j]) {
cost[j] = graph->edge[k][j];
visited[j] = k;
}
}
}
free(visited);
free(cost);
free(mark);
return sum;
}
Dijkstra 算法
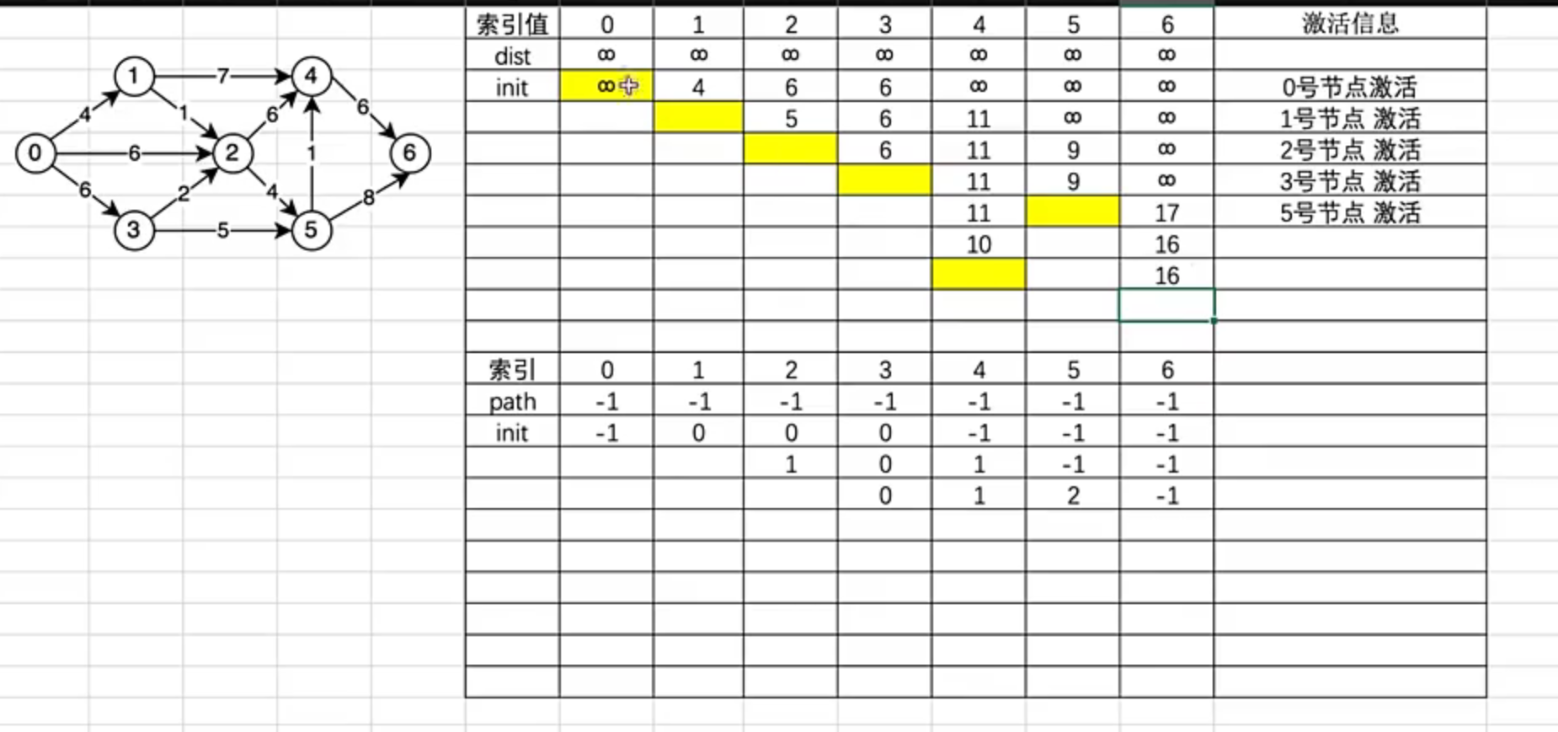
算法逻辑:
这个是看单原点到其他节点的最短路径为题,考虑节点与节点之间的关系。思路描述:比如这里原点是0节点。和他最短的是1 那一个所以1节点激活。这样看的视角就多了,通过1到2 的距离就变短了,那么就更新2的dist数组,同时更新path数组 以此类推
代码思路分析:
// 节点的访问记录,确定是否激活
/* 分别用0 1 2 3 4 5来表示到达的节点的下标
star 是一开始确定原始的原点是在哪里,dist数组是用来记录这个点经过原点到这个点的路径,
path数组是用来记录上一个确定的节点到此节点的
*/
/*
整体思路:1. 首先确定初始化内容,就是对0节点到其他节点的dist数组里面的内容的填数
(按照有更新就激活对应节点的path对应的上一个路径节点)
2. 解决初始节点的初始化更新
3. 按照一行一行的步骤,更行每个节点的数值
4. 在这里一整个大循环就是对于每一行的操作
5. 其中的两个小循环分别
(1)在对于上一个已经填完dist数组之后,对比找出路径最小的节点
并激活这个节点
(2)对于下一个已经激活节点后,完善dist表格,如果有更新,就更新path数组
没有的话维持上一个的值(就是不改)
*/
/*虽然在填表的时候,dist数组是以表格是形式出现的,
但是写成数组覆盖的方式就极大的节省了申请的空间了*/代码实现:
void DijkstraMGraph(const mgraph* graph, int start, int dist[], int path[])
{
int* mark;
//分配空间给mark数组
mark = malloc(sizeof(int) * graph->nodenum);
for (int i = 0; i < graph->nodenum; i++) {
dist[i] = graph->edge[start][i];
if (dist[i] < INF) {
path[i] = start;
}
else {
path[i] = -1;
}
}
path[start] = -1;
dist[start] = INF;
mark[start] = 1;
int mini = INF;
int tempindex=0;
for (int i = 0; i < graph->nodenum; i++) {
mini = INF;
for (int j = 0; j < graph->nodenum; j++) {
if (dist[j] < mini && mark[j] != 1) {
mini = dist[j];
tempindex = j;
}
}
mark[tempindex] = 1;
for (int j = 0; j < graph->nodenum; j++) {
//dist[j]就是已经是到上一个点最小的了,
if (mark[j] != 1&&graph->edge[tempindex][j]+dist[tempindex]<dist[j]) {
dist[j] = graph->edge[tempindex][j] + dist[tempindex];
path[j] = tempindex;
}
}
}
free(mark);
}
void showShortPath(const int path[], int num, int pos) {
/*
做一个模拟栈的弹栈和入栈的操作
*/
int* stack = malloc(sizeof(int) * num);
if (stack == NULL) {
return;
}
int top = -1;
while (path[pos] != -1) {
top++;
stack[top] = path[pos];
pos = path[pos];
}
while (top != -1) {
top--;
printf("%d", stack[top]);
}
free(stack);
}