引言:当大模型学会“察言观色”
不知道你有没有这样的经历:让AI写一段文案,它技术细节满分,但读起来冰冷生硬;想让它模仿你的写作风格,结果却总是差那么点意思。这背后其实是一个关键问题——大模型知道“是什么”,却不一定知道“怎样更好” 。
传统的监督微调,就像让学生背课本,能学会知识,但不懂灵活运用。而强化学习,尤其是今天要聊的PPO(近端策略优化)算法,则是让AI在“实践”中学习:通过不断的试错和反馈,学会什么样的回答更受人类喜欢,什么样的风格更符合你的期待。
从ChatGPT的对话流畅度,到Midjourney的画面审美,背后都有PPO的身影。它已经成为对齐大模型与人类偏好不可或缺的技术。今天,我们就来彻底搞懂它——即使你没有强化学习背景,也能跟着这篇文章,理解PPO为何强大,并亲手尝试“调教”属于你自己的模型。
一、PPO:为什么是它?——温和的“AI教练”哲学
一个比喻:好老师 vs 坏老师
想象两位老师:
- 老师A:学生进步一点就大加赞扬,退步一点就严厉斥责。学生情绪大起大落,最终可能厌学。
- 老师B:每次只要求学生比之前进步一小步,稳步鼓励,避免极端。
PPO就是老师B。它的核心设计理念非常人性化:在更新模型策略时,每一步的改动都不要太大,要温和、稳定地推进。
从TRPO到PPO:一次关键的“简化”
在PPO之前,主流算法是TRPO(信赖域策略优化)。它虽然稳定,但数学复杂、计算繁琐,好比每次调整都要解一道高数题,实操门槛很高。
2017年,OpenAI提出了PPO。它用了一个巧妙的“剪切”技巧,取代了TRPO复杂的约束计算,在保持训练稳定的前提下,让实现难度和计算成本大幅下降。正是这种“稳而不笨”的特性,让PPO迅速成为工业界和学术界的主流选择,也成为大模型RLHF(基于人类反馈的强化学习)微调阶段的基石。
二、深入浅出:PPO核心原理四步拆解
我们来把手弄脏,看看PPO到底是怎么工作的。别担心,我们不用公式轰炸,而是用概念和比喻把它讲清楚。
1. 新旧策略对比:AI的“昨天”和“今天”
PPO训练时会维护两个策略:
- 旧策略:可以理解为模型“昨天”的行为模式。
- 新策略:我们希望模型“今天”学习到的、更好的行为模式。
关键在于,我们通过对比新旧策略在同一个行为上的概率差异,来评估新策略的好坏,而不是让新策略完全从头摸索。这大大提升了学习效率。
2. “剪切”的艺术:给更新幅度加上安全阀
这是PPO最精妙的一环。为了避免新策略相对旧策略“突变”(步子迈太大扯着蛋),PPO引入了一个剪切区间,通常是 [0.8, 1.2]。
- 如果新策略对某个好行为的采纳概率激增(比如超过旧策略的1.2倍),我们只按1.2倍算。
- 如果对某个好行为的采纳概率锐减(比如低于旧策略的0.8倍),我们也只按0.8倍算。
这样,无论计算结果如何,策略的更新都被限制在一个安全的范围内,确保了训练的平稳。
3. 优势函数:判断“好不好”的标尺
光知道某个行为在新旧策略中的概率变化还不够,我们还得知道这个行为本身好不好。这就是“优势函数”的作用。
- 它衡量的是:在特定情境下,做出某个具体动作,比采用平均策略能多赚多少“奖励” 。
- 可以理解为,它不仅看动作有没有得分,更看这个得分是运气好(环境简单),还是真的决策高明。
在实际操作中,我们常使用GAE(广义优势估计) 来更聪明地计算这个优势值,它能更好地平衡短期收益和长期回报。
4. PPO流程全景图
结合以上概念,一个典型的PPO训练循环是这样的:
- 交互采样:让当前策略的模型去生成一些文本(或执行动作),并获得反馈(奖励分数)。
- 优势评估:基于收集到的数据,计算每个动作的优势值(到底多有效)。
- 策略更新:使用剪切后的目标函数,根据优势值来更新模型参数。改得好的地方保留,但改动的幅度被严格限制。
- 循环迭代:重复上述过程,让模型像爬缓坡一样,一步步逼近最优行为。
整个过程,就像一个耐心的教练,看着学员的训练录像(采样),指出哪些动作真正带来了得分提升(优势评估),然后针对性地、一点点地纠正他的动作细节(剪切更新)。
三、动手实践:三步走通你的第一个PPO微调
理论说得再多,不如动手一试。我们以一个“让AI生成更友好对话”的场景为例,拆解操作步骤。
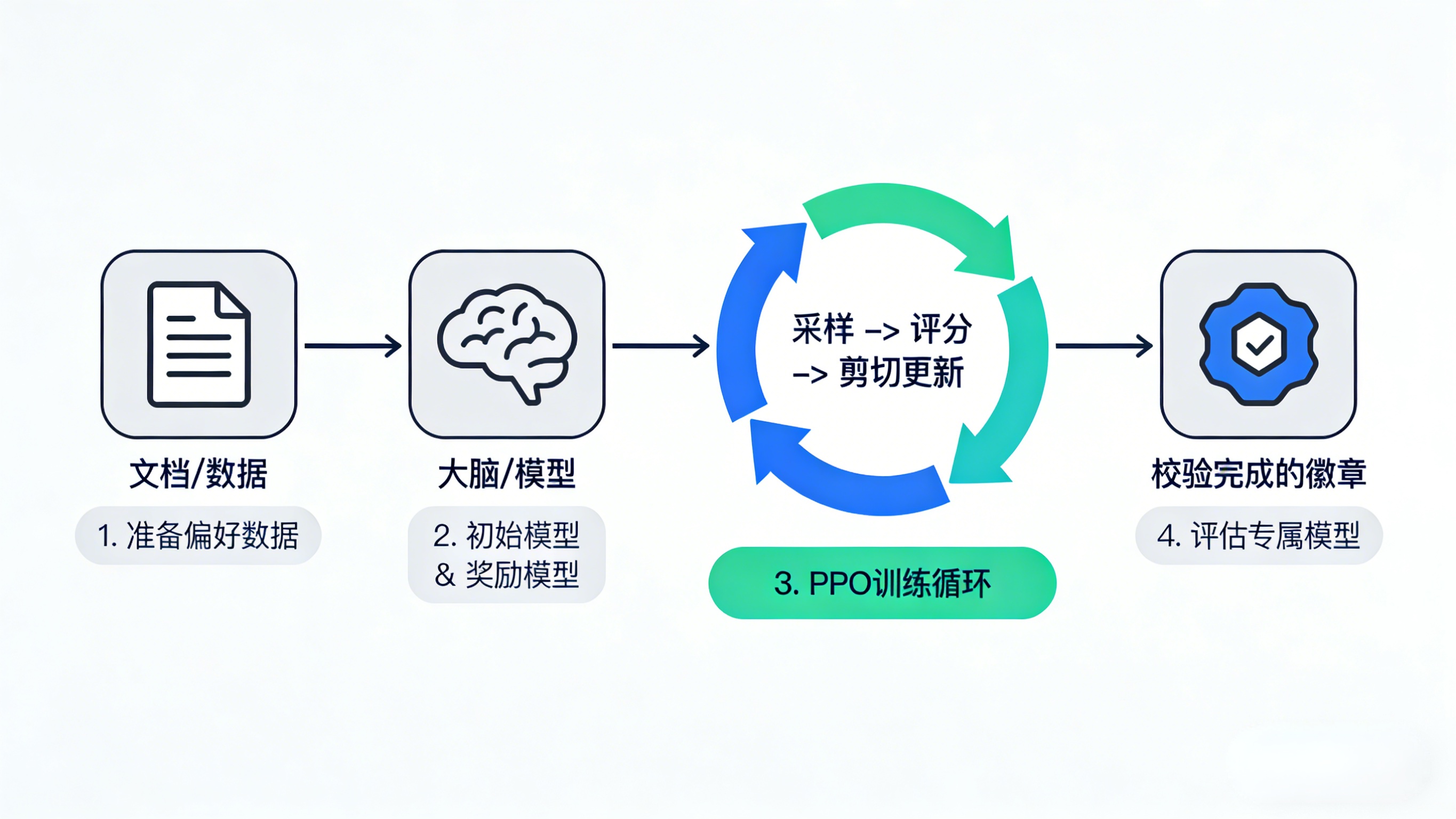
第一步:准备数据与环境
- 数据:准备一个“偏好数据对”数据集。例如,对于同一个问题,提供一组“较好”的回答和一组“较差”的回答。这是训练奖励模型的基石。
- 基础模型:选择一个经过监督微调(SFT)的基座模型。PPO需要一个已经具备基本能力的“学生”,而不是从零开始的“婴儿”。
- 奖励模型:你可以使用公开的奖励模型,或者用自己的偏好数据训练一个小型奖励模型,用于给生成的文本打分。
第二步:配置与启动PPO训练
这是传统上最需要代码知识的环节,但核心参数只有几个:
- 学习率:策略更新的“步速”,建议从小值开始(如1e-6)。
- 剪切阈值(epsilon) :通常设置在0.1到0.2之间,是控制“温和度”的关键。
- KL散度系数:一个额外的惩罚项,防止新策略跑得离初始策略太远,丢失原有能力。
- 训练轮数与批次大小:根据你的计算资源和数据量调整。
第三步:监控与调整
训练不是一劳永逸,需要实时“看护”:
- 监控奖励曲线:总奖励应呈上升趋势,但需注意不要过快上升,可能是奖励模型被“钻空子”。
- 监控KL散度:确保其在可控范围内缓慢增长,避免模型“遗忘”。
- 人工抽查:定期抽样查看模型生成的内容,这是最直观的检验。
看到这里你可能发现,实操中涉及大量环境配置、代码调试和资源管理。如果你想跳过这些繁琐步骤,直接专注于数据和效果,可以尝试 LLaMA-Factory Online 这类平台。它将上述所有步骤集成在一个Web界面中。你只需要上传数据、选择模型、配置训练任务(平台会提供推荐的参数配置),点击开始即可。平台会自动处理分布式训练、资源调度和实验跟踪,让你无需代码基础也能体验到从数据到专属模型的完整创造过程,在实践中深刻理解如何让模型“更像你想要的样子”。
四、效果评估:你的模型真的变“聪明”了吗?
训练完成,如何验收成果?别只看损失函数,要从多维度评估:
-
定量评估:
- 奖励分提升:在独立的测试集上,微调后模型的平均奖励分应有显著提升。
- 胜率对比:将新旧模型的回答匿名打乱,让人类或更强的AI裁判进行偏好选择,计算新模型的胜率。
-
定性评估(更为关键) :
- 风格对齐:它是否学会了你想让它模仿的风格(如更简洁、更幽默)?
- 有害内容减少:在敏感问题上,回答是否更加安全、无害?
- 创造力检验:在一些开放性问题中,它的回答是否在符合要求的前提下,依然保持多样性和趣味性?
-
能力保留检查:
- 在未经过偏好训练的通用任务(如数学计算、常识问答)上测试,确保PPO没有损害模型的原有核心能力。这是评估微调是否“跑偏”的重要标准。
五、总结与展望
让我们回到最初的三个问题,现在你应该有了清晰的答案:
- PPO为什么成为主流? 因为它用“剪切”这一巧妙设计,在训练稳定性和实现简易性之间找到了黄金平衡点,让强化学习变得更容易应用于大模型这类复杂系统。
- PPO的核心是什么? 其核心是扮演一个温和而坚定的教练,通过限制策略更新的最大步幅(剪切),并利用优势函数精准评估行为价值,实现稳定高效的策略提升。
- 如何有效应用PPO? 关键在于高质量的反馈信号(奖励模型)、谨慎的参数配置以及全过程的细致监控。它是一个需要耐心调试的过程,而非一键魔法。
展望未来
PPO目前虽占据主导,但技术仍在快速演进。DPO等直接偏好优化算法,试图绕过奖励模型和复杂的PPO循环;而Q-Learning系列算法也在不断进化。未来的趋势是更高效、更稳定、对反馈数据质量依赖更低的微调方法。
技术的本质是延伸人的能力。大模型微调技术,尤其是PPO,将塑造AI的“个性”和“价值观”的能力,交到了更多人的手中。它不再仅仅是巨头的游戏,而正在成为每个开发者、甚至每个有想法的团队都能使用的工具。
掌握它,你就能不止于使用AI,而是开始设计和创造符合你心中所想的AI。这个过程充满挑战,但当你看到模型生成的文字第一次精准命中你的期待时,那种成就感,无与伦比。
现在,是时候开始你的第一次微调之旅了。