完整教程:Android 宣布 Runtime 编译速度史诗级提升:在编译时间上优化了 18%
近期,Android 官方宣布了 Android Runtime 在编译时间上完成了 18% 的显著优化,同时不牺牲编译代码的质量,也没有增加峰值内存使用,换句话说,这属于是一个“速度提升 + 零损失”的优化成果。
实际上该调整作为 2025 年的关键 KPI ,目前已经建立了分阶段 rollout:部分优化已经在 2025 年 6 月的 Android 发布中上线,其余会在年底发布中完成,所有运行 Android 12 及以上版本的用户都可以借助 mainline 更新得到这些改进。
“mainline 更新”( Project Mainline / Google Play System Updates) 是一种模块化更新机制,它支持 Google 通过 Google Play 直接更新 Android 系统的核心组件(如Android Runtime、媒体框架、安全模块等),这个更新不需要用户等待 OTA 。
而这次优化更加具体的说就是:
编译时间减少了 18%
对编译器最终输出质量没有负面影响
没有出现内存回归(就是提升过程中不增加内存占用峰值)
并且,这些改进对于 JIT 和 AOT(预先编译) 都有用,当然这里提到的 Android Runtime(ART)“编译速度”不是你在本地用 Gradle 构建 APK 的速度,而是「设备端 ART 对 app 字节码进行 AOT / JIT 编译的速度」,一般而言针对ART 内部的“编译器执行速度”会有:
- JIT 编译速度
- AOT / dex2oat 编译速度
- 编译器各个 IR / 优化 pass 的执行时间
例如在 ART 里有很多 pass(比如 GVN、某些数据流分析),每次都会遍历 IR,即使当前方法根本不满足优化条件也会完整跑一遍逻辑,这种行为带来的开销并没有产生收益:
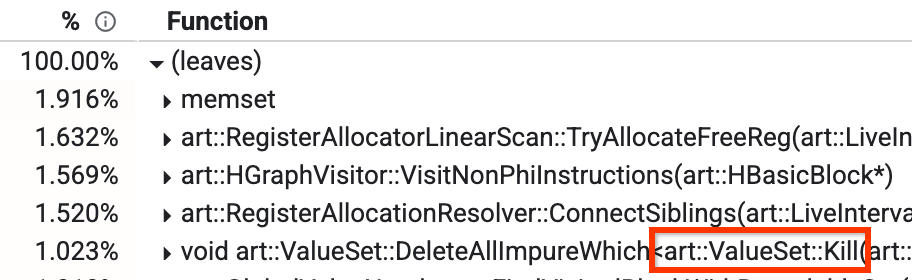
官方提到,在之前有一个名为全局值编号 (GVN) 的阶段,这个过程里它有一个名为
Kill的方法,这个方法会根据过滤器删除一些节点,由于它需要遍历所有节点并逐个检查,因此非常耗时,而事实上无论当时有多少节点存活,其实都能预先知道检查结果为 false ,那么在这种情况下完全可以跳过遍历,从而将性能消耗从 1.023% 降低到约 0.3%,并将 GVN 的运行时间缩短约 15%。
其他的一些案例,包括有:
FindReferenceInfoOf 的查找优化
LoadStoreAnalysis 阶段的方法 FindReferenceInfoOf 原本使用线性搜索 O(n) 在向量中查找,而现在将数据结构改为以指令 ID 为索引,实现 O(1) 查找,并预分配向量以避免 resize , 从而在该阶段加速 34 - 66%,总编译时间提升 0.5-1.8%,虽然增加了一个计数字段,但峰值内存没有增加。
结构调整
代码库中使用了一个自定义的 HashSet,多年前是为了处理极少数的大型集合而优化的,但现在的用法变成了创建大量小型的、短生命周期的集合,所以本地调整实现以适应“小而短”的用法,减少创建和销毁开销,从而让编译时间提升 1.3-2%,且内存使用量反而下降了 0.5-1%。
还有通过将数据结构以引用方式传递给 lambda 表达式,避免了数据结构的复制,从而将编译时间缩短了约 0.5% 到 1% ,这一点在最初的代码审查中被忽略了,并在代码库中保留了多年:

内联 (Inlining) 检查
编译器为了性能会内联函数,原本的流程是先计算大量数据,最后再做“最终检查”(如指令数、寄存器需求)决定是否内联,而现在将这些检查从“计算后”移到了“计算前”作为启发式规则(Heuristics),避免了大量无效计算,仅指令数检查一项的移动就带来了约 2% 的提升。
事实上官方在进行这些调整时也遇到了不少问题,基于即使你发现某个区域占用了大量编译时间,并且投入了创建时间尝试改进,有时也找不到解决方案,当你修改了 A 问题后,自然而然就带了 B 问题,比如:
- 内存回归:在优化“输出写入”阶段时,团队通过缓存计算值来加速(原本预计提升 1.3-2.8%),但自动化测试时发现,额外的缓存数据结构导致了内存使用量的显著增加
- 历史遗留负担 :许多低效代码是因为历史原因遗留下来的(比如上述的
HashSet),或者是因为代码审查疏忽(将对象按值传递而不是按引用传递) - 复杂度的权衡:某些优化方案可能过于复杂,或者会增加代码维护难度
针对这些问题,官方进行了一系列的调整尝试:
- 重构解决内存回归:针对“输出写入”阶段的内存障碍,本次直接重构了该阶段的逻辑,这里设计了一种新方案,移除了两个冗余数据结构中的一个,这不仅应对了内存回退问题,还进一步提升了 0.5-1.8% 的速度

- 使用 pprof 进行深度分析 :利用
pprof工具生成 Flame Graph和 Bottom-up 视图,精准定位那些“隐形”的开销(如频繁的Kill方法或意外的对象拷贝)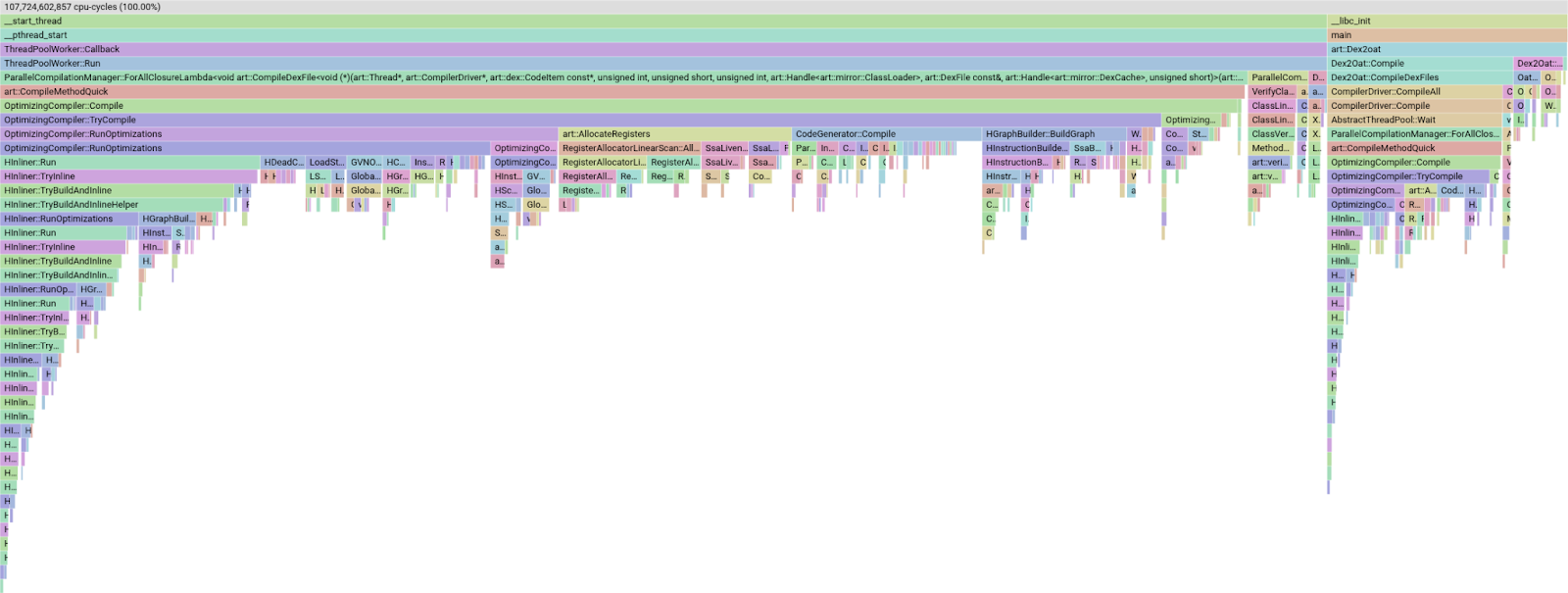
- “快速迭代”策略:为了节省编写时间,先用原型(Prototype)在典型应用(First-party apps, Android OS)上快速验证想法,确认收益后再进行完整的工程搭建和测试
- 利用全新 C++ 特性 :比如使用
BitVectorView替代可变长的BitVector,并利用模板化实现让Union()操作在 64 位平台上一次处理两倍的位数
除此之外还有:
- Add bookkeeping将编译时间缩短约 0.6-1.6%
- Lazily compute data来避免循环计算
- Refactor our code跳过不会用到的预计算工作
- Avoid some dependent load chains如果可以从其他地方轻松获取 allocator
- 避免在寄存器分配中频繁地对寄存器类型(核心/浮点)进行分支
- 确保某些数组在编译时已初始化,不要依赖 clang 来达成这项工作
- 优化一些循环,使用范围循环,因为 clang 可以更好地优化范围循环,避免因循环副作用而重新加载容器的内部指针,避免在循环中通过内联的
InputAt(.)为每个输入调用虚函数HInstruction::GetInputRecords() - 利用编译器优化,避免在访问者模式中使用 Accept() 函数
最后
最后,看不懂不要紧,只需要知道它很牛逼,并且还能让 Android 12 以后的机器变得更快,在用户端体现出来就是:
- app 启动更快
- 冷启动更少卡顿
- 低端机更友好
- 安装 / 更新变快
一份优秀的编译器工程的案例研究。就是同时也展示了教科书级别的优化策略,不仅要看速度,更要看内存、稳定性、可维护性等综合指标,所以官方这份报告不仅仅是手艺公告,更
参考链接
https://android-developers.googleblog.com/2025/12/18-faster-compiles-0-compromises.html