数小时视频,关键仅几秒:AI如何像侦探一样找到答案?LongVT:先定位再核验,精准不瞎猜
01论文概述
这篇文章由MiroMind AI 与 南洋理工大学核心领衔(通讯作者:Shijian Lu、Xingxuan Li),联合香港科技大学(广州)、清华大学以及 LMMs-Lab 团队共同完成。

论文名称:LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling
👉论文链接
👉项目地址
👉Github地址
👉大模型实验室Lab4AI
长视频推理与以往的视频问答任务存在本质上的不同挑战: 大语言多模态模型(LMMs) 必须在长达数小时的视频内容中,定位其中稀疏、细粒度且具有因果决定性的片段。
但目前的大语言多模态模型大多是基于粗粒度、片段级的数据训练的。
这种不匹配导致当下的大语言多模态模型缺乏必要的监督,无法学习时间假设的形成、验证或修正的方式。
除此之外,现有的大多数视频理解基准数据集仅提供选择题形式的问答任务,这类任务无需真正的时间定位即可完成,并且容易受到数据集信息泄露或捷径利用的影响。
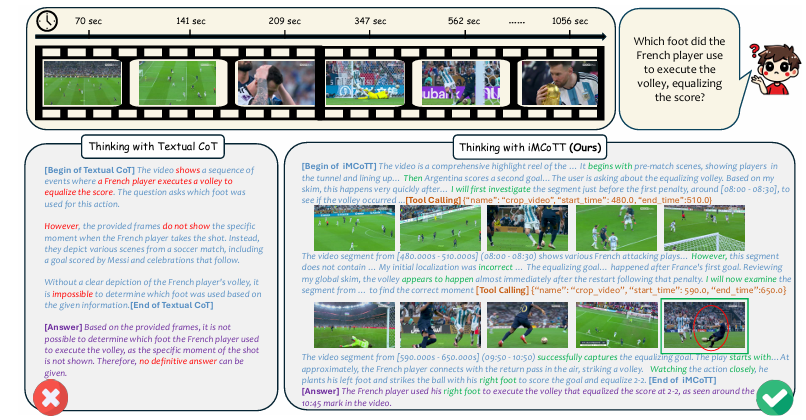
受人类先对长视频进行全局概览、再针对相关片段查看细节的理解方式启发,作者提出LongVT。
LongVT 的核心目标是让模型学会像人一样工作:不确定就回去查证据,并把查证过程放入训练目标与奖励信号。
针对长视频推理任务缺乏细粒度问答(QA)数据的问题,作者还整理并将会发布一个名为 VideoSIAH 的数据集套件。它一方面可以作为训练数据集,捕捉“大海捞针式”视频片段问答所需的推理动态。
另一方面也包含一个细粒度的评估基准 VideoSIAH-Eval,该基准通过人在环路的验证方式,用于长视频开放式问答的评估。
02核心贡献
(1) LongVT:面向 “长视频协同推理” 的端到端智能体框架
作者提出了一种全新的范式,它将多模态工具增强思维链(CoT)与针对长达数小时视频的按需片段检查进行原生交错结合,从而使大语言多模态模型(LMMs)可以实现更高效、更可靠的长视频推理。
(2) VideoSIAH:面向证据稀疏型长视频推理的细粒度数据集套件
作者构建了一个可扩展的数据生成流程,可产出多样且高质量的问答(QA)数据与工具集成推理轨迹;同时搭建了一个专门的基准数据集,针对 “大海捞针式” 视频片段推理场景设计。
(3) LongVT-7B-RFT:当前最优基线模型
通过大量的定量对比、针对数据方案、训练策略与设计选择的系统性消融实验,以及对训练动态的深入分析,作者构建并开源了一个具备“长视频协同推理” 能力的高性能基线模型。
03核心技术
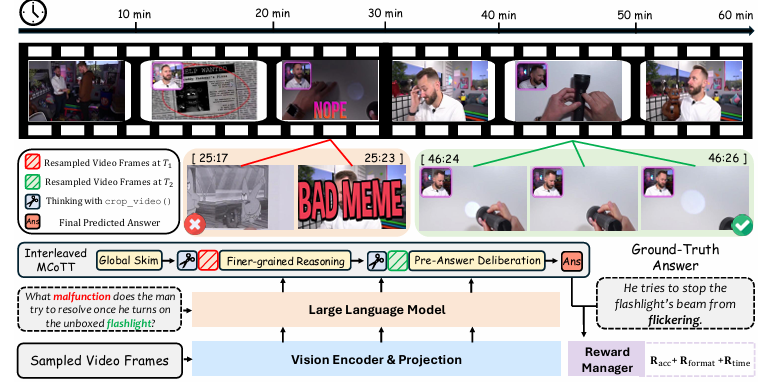
(1)iMCoTT推理范式
LongVT 模仿人类“浏览-聚焦-验证”的思考流程:
模型先对采样帧进行全局粗浏览形成粗定位假设,再调用原生工具聚焦关键片段,获取细粒度视觉证据;如果证据不足,则修正初始假设,迭代推理直至输出答案。
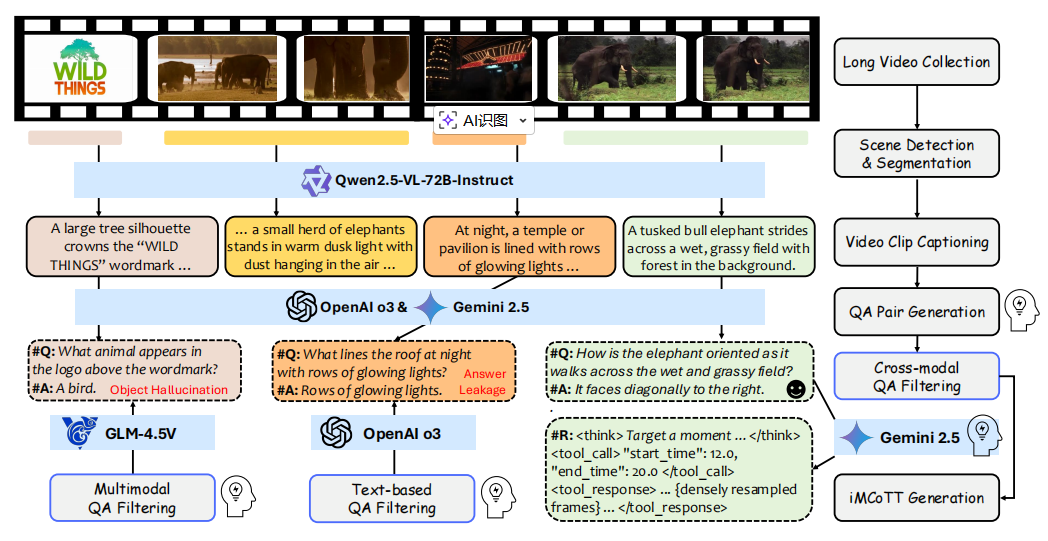
(2)VideoSIAH数据集构建
为支撑“先定位再核验”的工具增强推理,论文构建了 VideoSIAH 数据套件,覆盖 SFT(含非工具与工具增强)+ RL/RFT 的完整训练链路。包括以下3类:
- SFT数据:24.7K个工具增强的监督微调样本(通过半自动管道生成,结合场景检测、片段化、QA生成与人工过滤);
- RL数据:1.6K个强化学习样本(用于学习主动工具调用策略);
- RFT数据:15.4K个强化微调样本(蒸馏高奖励轨迹,稳定推理行为)
(3)三阶段训练策略
LongVT是一个端到端的智能体框架,该框架借助三阶段训练策略,结合来自 VideoSIAH 的大规模高质量工具增强数据,激发大语言多模态模型(LMMs)的 “与长视频一同思考” 的能力。
- 冷启动监督微调Cold-start SFT:先教会模型“该怎么选时间窗、怎么调用工具、怎么用工具返回证据写答案”;
- 自主强化学习Agentic RL(GRPO):在强化学习阶段引入时间定位奖励,让策略学会“何时检索、检索多长、如何融合证据”,突破纯监督的性能上限;
- 自主强化微调Agentic RFT:把高奖励轨迹“蒸馏回监督数据”,进一步稳定并获得额外增益。
04研究结果
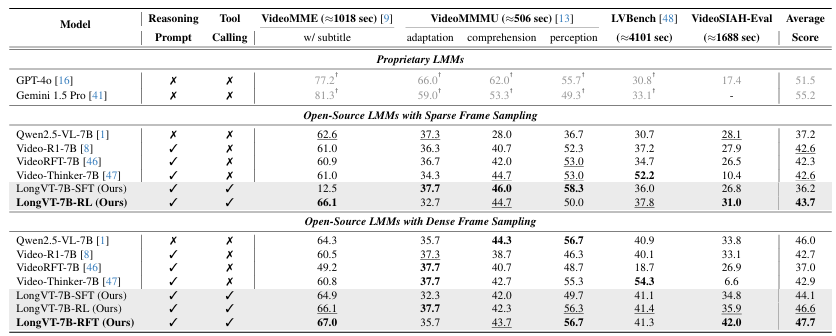
(1)主要实验
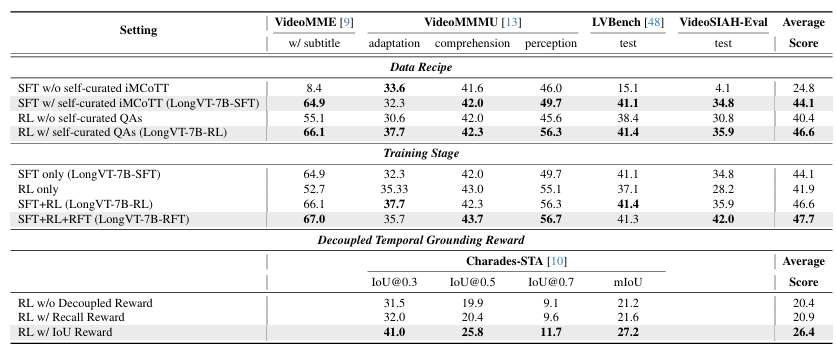
如Table 2所示,LongVT 在 VideoMME、VideoMMMU、LVBench 与 VideoSIAH-Eval 四个基准上均实现一致提升。
在更具挑战的VideoSIAH-Eval 上,LongVT-7B-RFT 达到 42.0分,较次优开源基线提升约 6 分,体现其在“证据稀疏”的长视频场景中具备更强的时序定位与证据复核能力。
从整体平均分看,LongVT 最优 checkpoint 为 47.7,与 GPT-4o 的 51.5 相差约 3.8 分(≈4 分),说明开源模型正在快速逼近闭源上限。
(2)消融实验
从SFT-only(44.1分)到 SFT+RL(46.6分),再到 SFT+RL+RFT(47.7分),平均分随训练阶段逐步上升,说明 RL 与后续 RFT 在 SFT 冷启动能力之上继续带来可累计的增益。
消融表明提升并非 “堆数据/堆轮次” 带来的偶然收益:
一方面,细粒度工具轨迹与自构造QA对性能至关重要(数据配方消融);
另一方面,显式引入时间对齐信号(IoU 形式的时序奖励)才能稳定学到“围绕时间证据进行检索—复核—作答”的行为(奖励设计消融)。
LongVT通过“工具调用+多阶段训练”的创新,让LMMs具备“思考长视频”的能力,为视频理解领域提供了新范式。其数据集、方法与实验结果为后续研究奠定了基础,同时暴露的局限也为未来方向指明路径。
🔍本文由AI深度解读,转载请联系授权。关注“大模型实验室Lab4AI”,第一时间获取前沿AI技术解析!