数据预处理(data preprocessing)
在将数据输入到神经网络前, 我们希望先进行一些预处理,使其更适合高效训练。
标准化
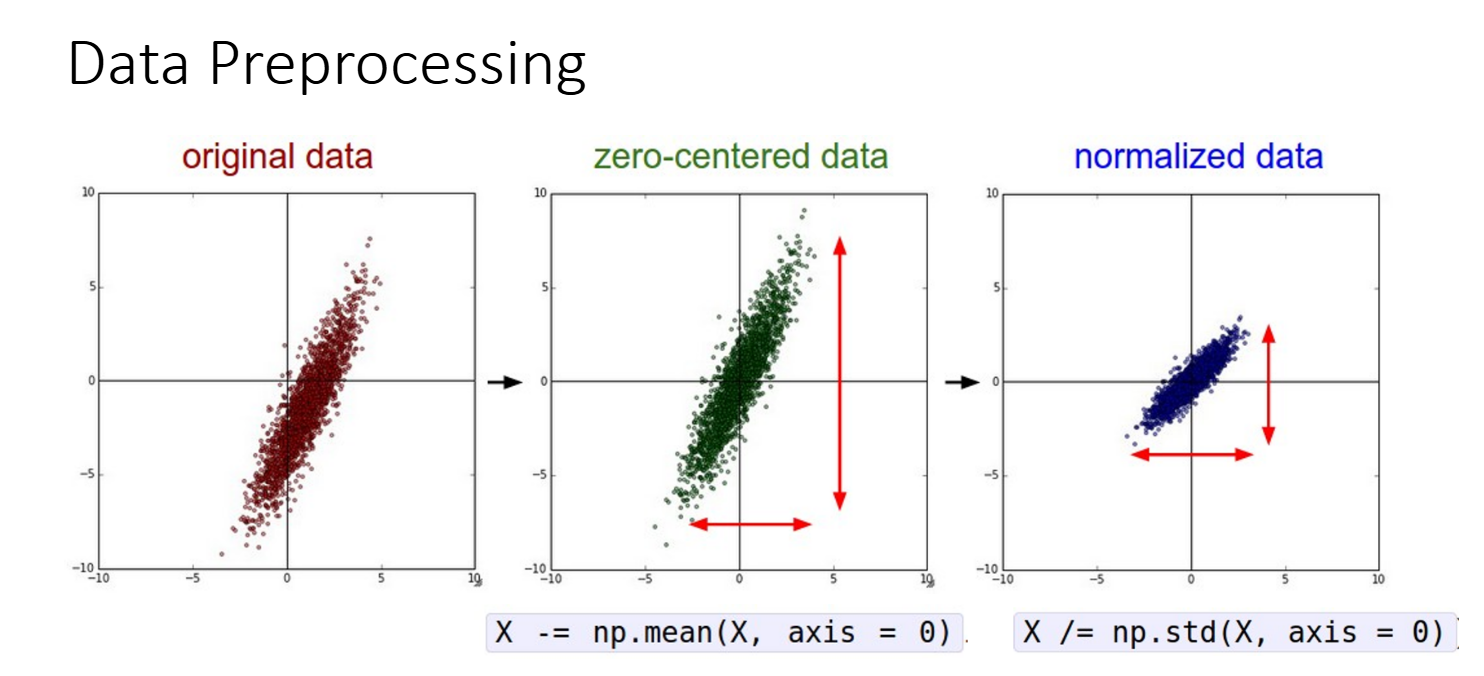
简单的数据预处理就是让数据以 0 为中心(zero-centered)或标准化。
下面这张图片中,坐标轴为数据的两个特征(如RGB图像的两个颜色通道),每个点代表一个样本。原始数据可能会很分散,且里中心较远,我们需要将它们减去均值并除以标准差。这样做可以使数据有正有负,不至于全是正的或者负的。
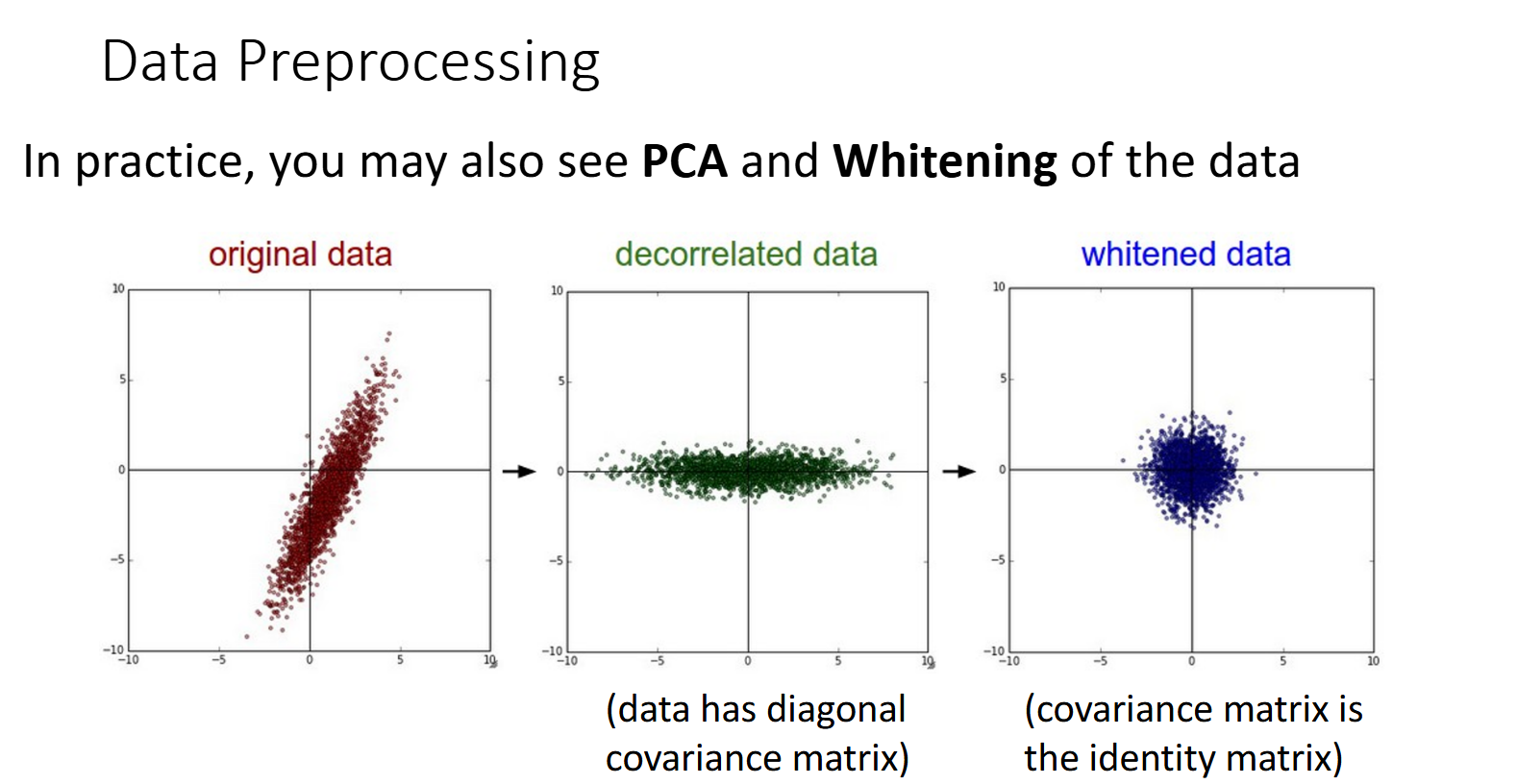
去相关(decorrelation)和白化(whitening)
非图像数据多使用去相关和白化。
去相关:计算整个训练集的协方差矩阵,然后使用该矩阵的特征值分解来旋转数据,使得不同特征之间不再相关。
白化(也叫球化):在去相关的基础上,进一步修正。
数学层面理解参考这篇文章
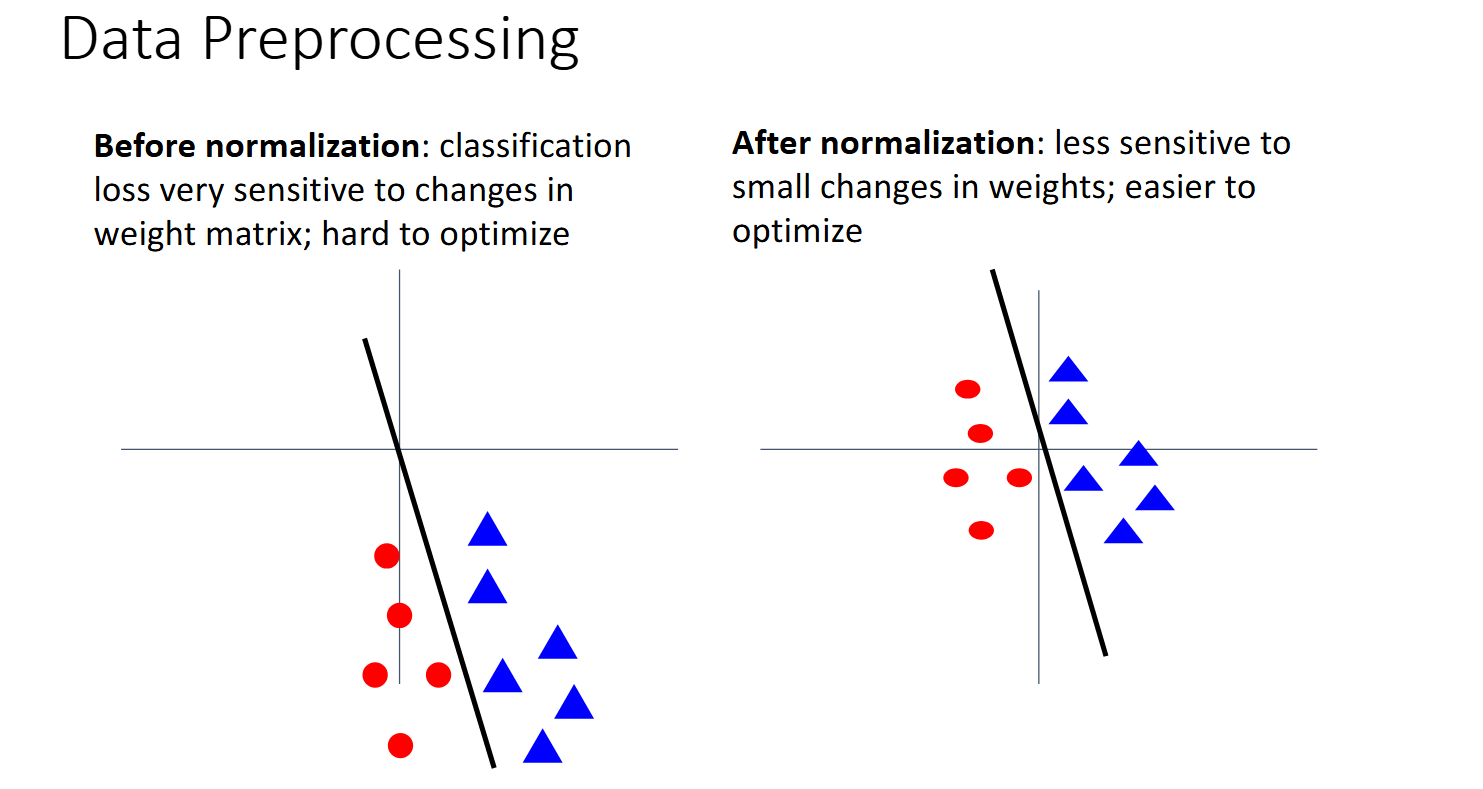
为什么要预处理数据
- 减轻对权重的敏感程度
- 使权重矩阵易于被优化
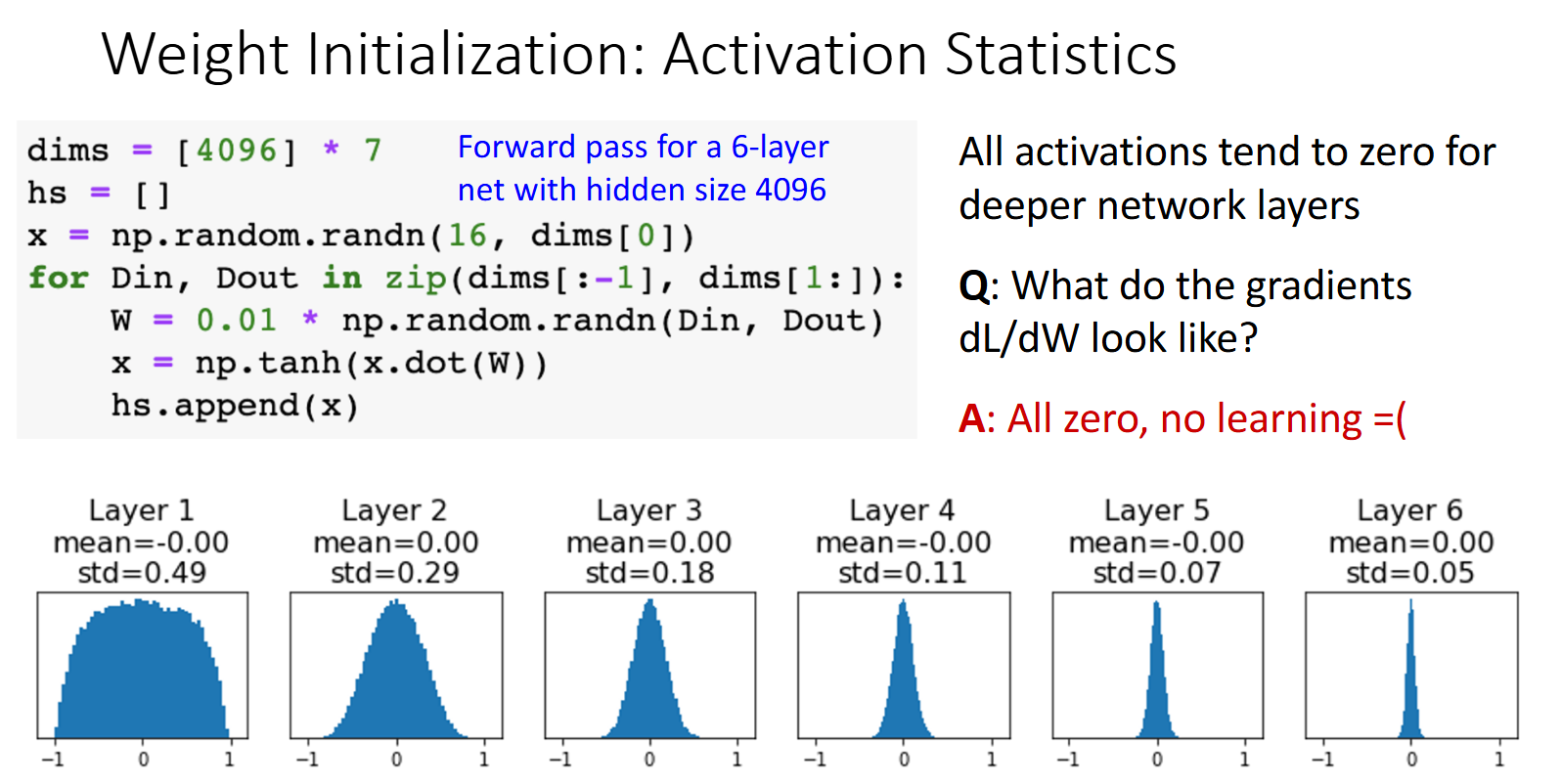
权重初始化(weight initialization)
在训练神经网络时,权重的初始化对最终的训练效果有很大影响。好的初始化方法可以加快收敛速度,避免梯度消失或爆炸问题。
零初始化
$W = 0, b = 0$如何?很糟糕。如果我们用的激活函数是ReLU, 那么输出就全是 $0$ 了,梯度也为 $0$,神经网络的训练会完全停滞。把初始权重全部设置为 $0$ 或某个常数会导致缺少某种对称性破缺(symmetry breaking),使神经网络失去了“提取不同特征”的能力。
高斯分布的小随机数初始化
w=alpha*np.random.randn(Din, Dout)
这种策略对于浅层网络比较有效,但对于深层网络来说,随着层数的增加,信号会逐渐变小或变大,导致梯度消失或爆炸。

Xavier初始化(Glorot初始化)
W = np.random.randn(Din, Dout) / np.sqrt(Din)
将标准差设置为层输入维度的平方根之一。
核心思想是让每一层的输出方差等于输入方差。
Gemini给出的类比:
想象你在玩传话游戏(深层神经网络):
- 如果声音太小(权重初始化过小):传了几个人后,声音就听不见了(信号趋近于 0,梯度消失)。
- 如果声音太大(权重初始化过大):传了几个人后,声音震耳欲聋甚至失真(信号趋近于无穷大或饱和,梯度爆炸)。
推导
假设某一层的输入 $x$ 和权重 $W$ 独立同分布,且均值为 $0$,方差分别为 $\mathrm{Var}(x)$ 和 $\mathrm{Var}(W)$。该层的输出 $y$ 为:
$$y = W x$$
输出的方差为:
$$\mathrm{Var}(y) = \mathrm{Var}(W x) = \mathrm{Var}(W) \cdot \mathrm{Var}(x) \cdot n$$
其中 $n$ 是输入的维度。为了保持方差不变,我们希望 $\mathrm{Var}(y) = \mathrm{Var}(x)$,因此需要满足:
$$\mathrm{Var}(W) \cdot n = 1 \implies \mathrm{Var}(W) = \frac{1}{n}$$

这样做很适合tanh激活函数。
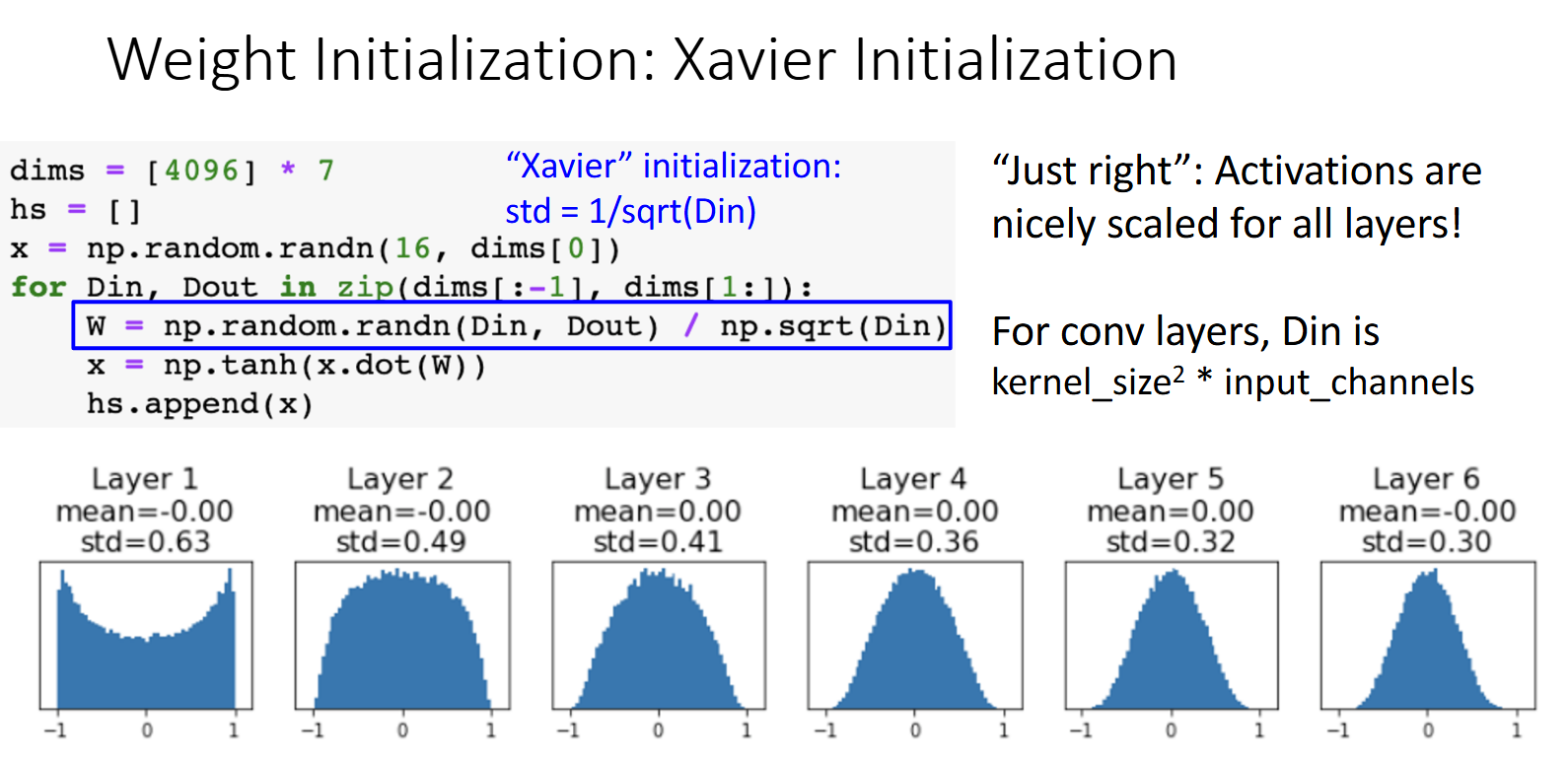
但是对于ReLU激活函数来说,Xavier初始化仍然会导致信号逐渐变小,因为ReLU会将一半的输入置零。
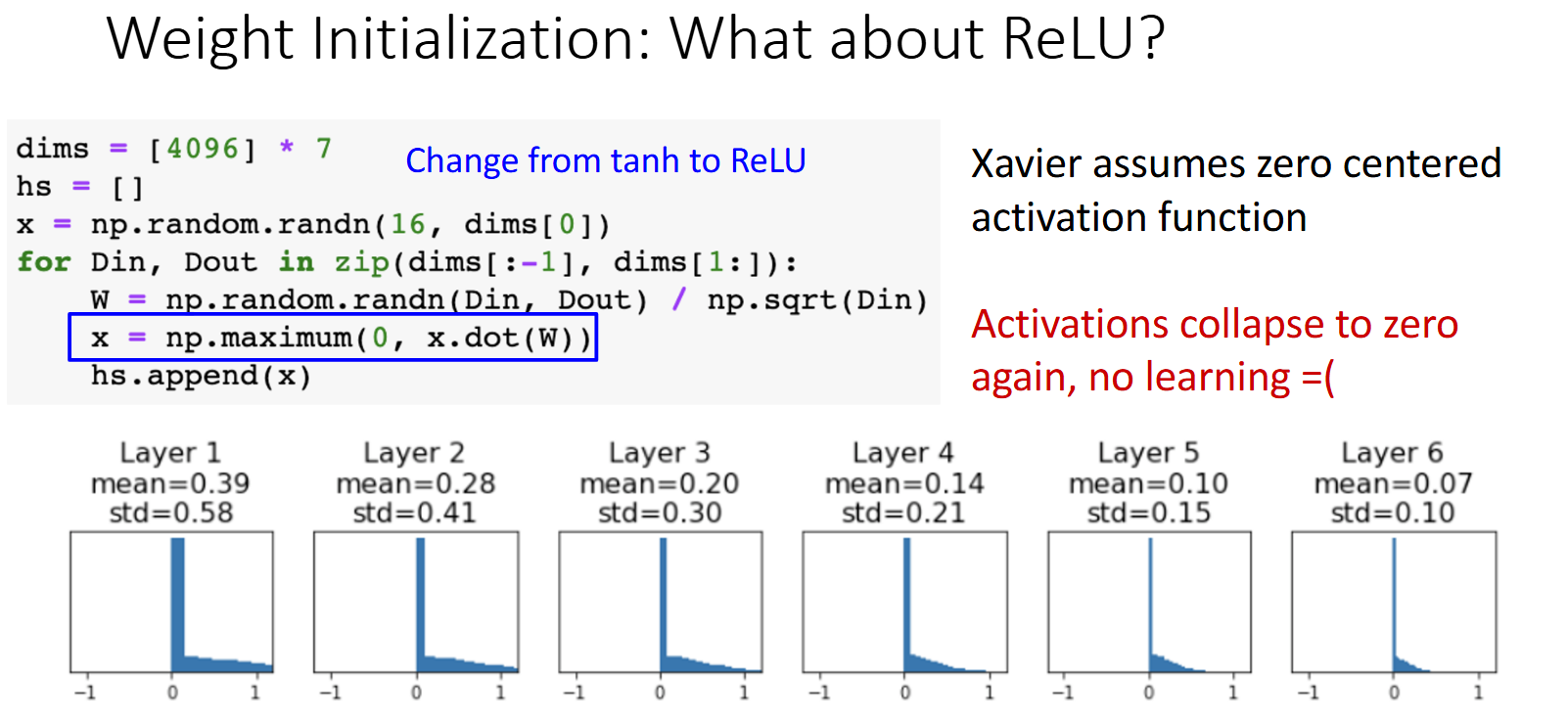
怎么办?只需把标准差设置为$\frac{2}{\sqrt{n}}$即可。这种方法叫做Kaiming Initialization。结果如下。

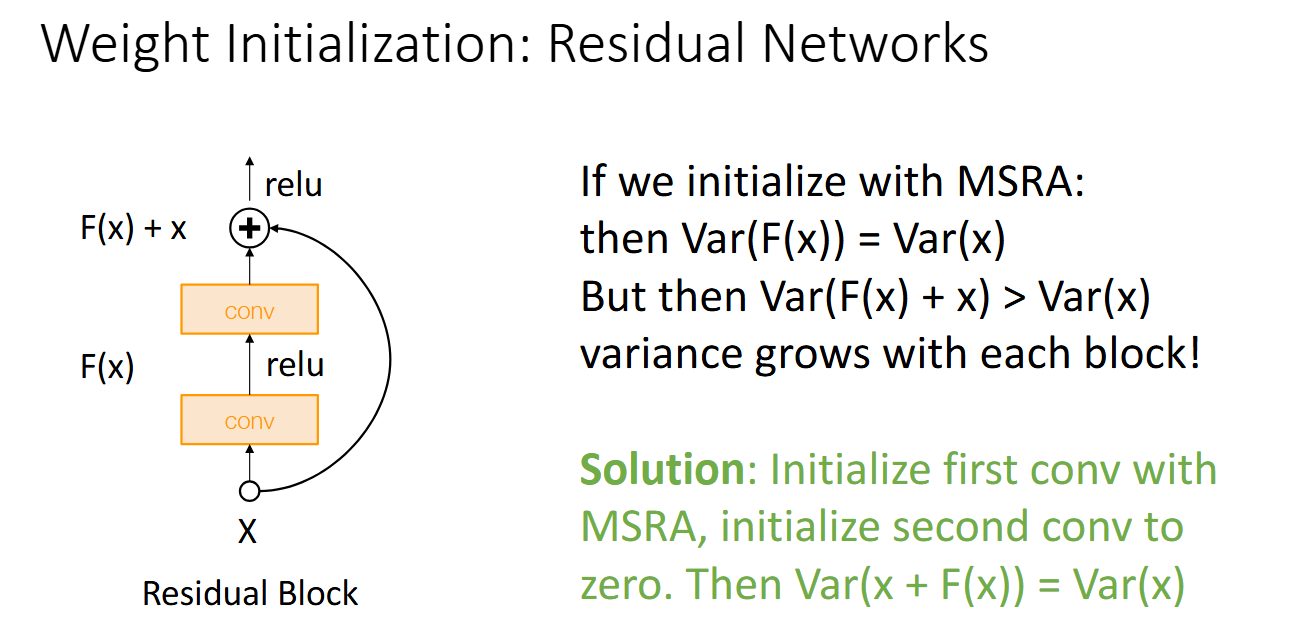
但是!!!Kaiming Initialization不适合Residual Networks,因为ResNet中有跳跃连接,一定会有$Var(F(x)+x) > Var(x)$。
因此我们需要将第一个卷积层做 MSRA, 而将第二个卷积层置为 0。
正则化
实际训练中我们需要一些正则化策略来防止过拟合。训练时我们会以某种方式注入一些噪声,干扰神经网络的训练,从而提升模型的泛化能力,在测试时则去除或者平均掉这些噪声。
L2 正则化
L2 正则化(也称为权重衰减)通过在损失函数中添加权重的平方和来惩罚过大的权重,从而防止过拟合。
$$Loss = Loss_{data} + \lambda \sum{W^2}$$
其中,$\lambda$ 是正则化强度的超参数。
Dropout
在前向传播时,以一定概率 $p$ 随机“丢弃”神经元(将其输出设为零),从而防止神经元之间的过度依赖。
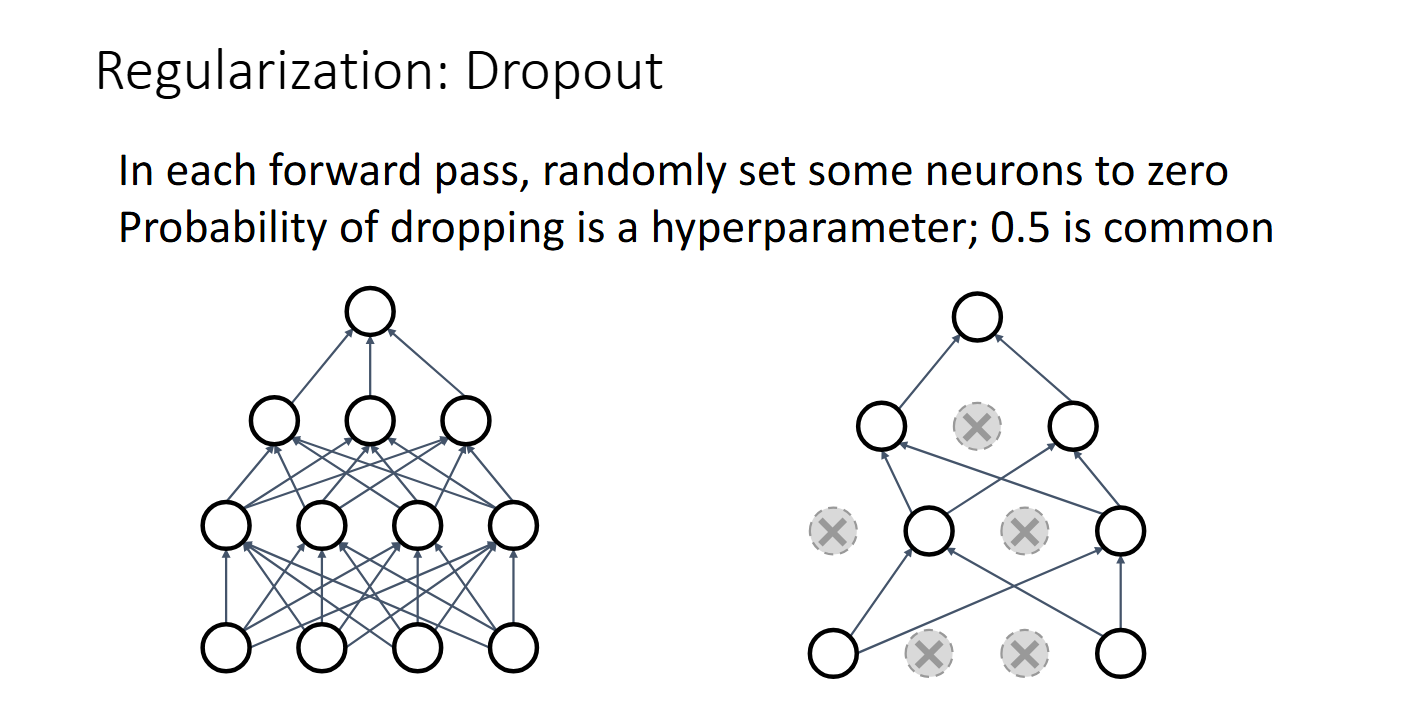
Dropout让神经网络具有一定的鲁棒性,因为它迫使网络在每次训练时都依赖不同的子网络,从而减少过拟合的风险。
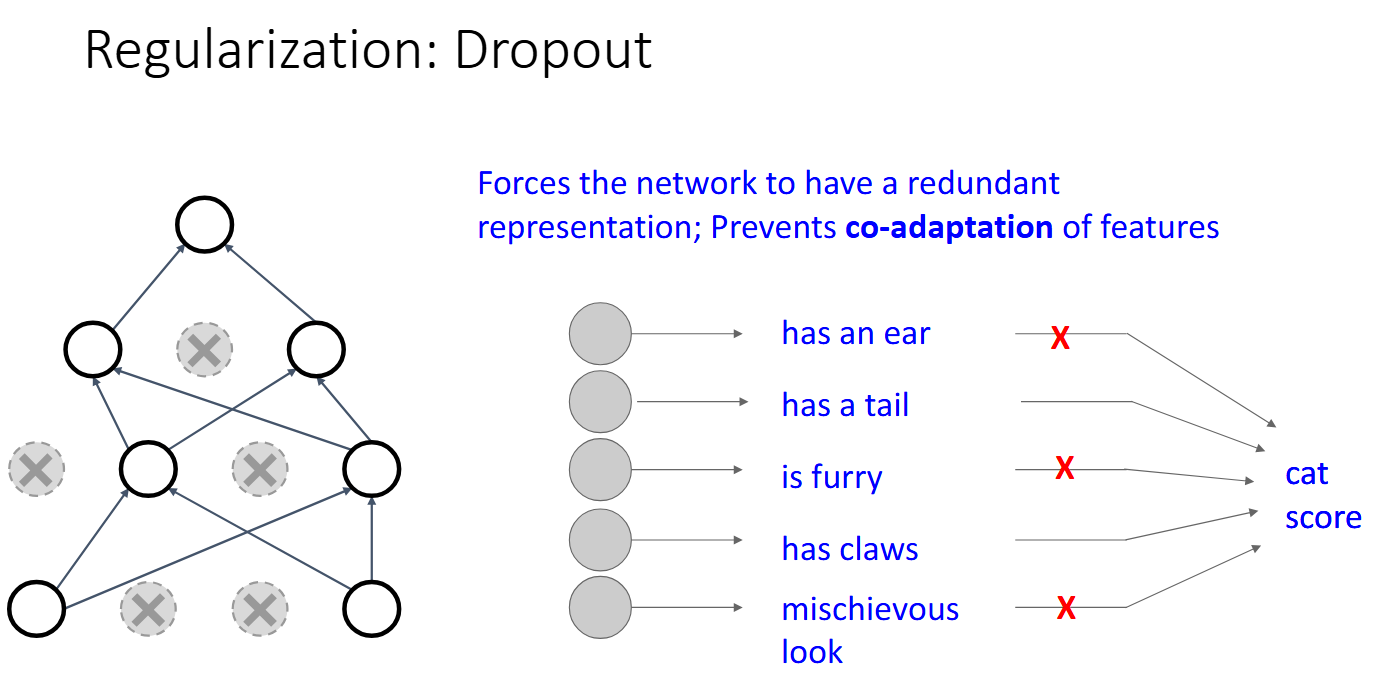
在测试时,为了让 Dropout 有一定稳定性,我们引入了随机掩码。

一般用于大型网络最后几层的全连接层中。但是后来一些网络(GoogleNet, ResNet)使用了全局平均池化, 就不用 Dropout 了
批量归一化(Batch Normalization)
批量归一化通过对每个小批量的数据进行归一化处理,使其均值为0,方差为1,从而加快训练速度并提高模型的稳定性。
数据增强(Data Augmentation)
图像反转, 图像裁剪, 图像旋转, 颜色抖动等都是引入随机性、扩充数据集的数据增强方法。
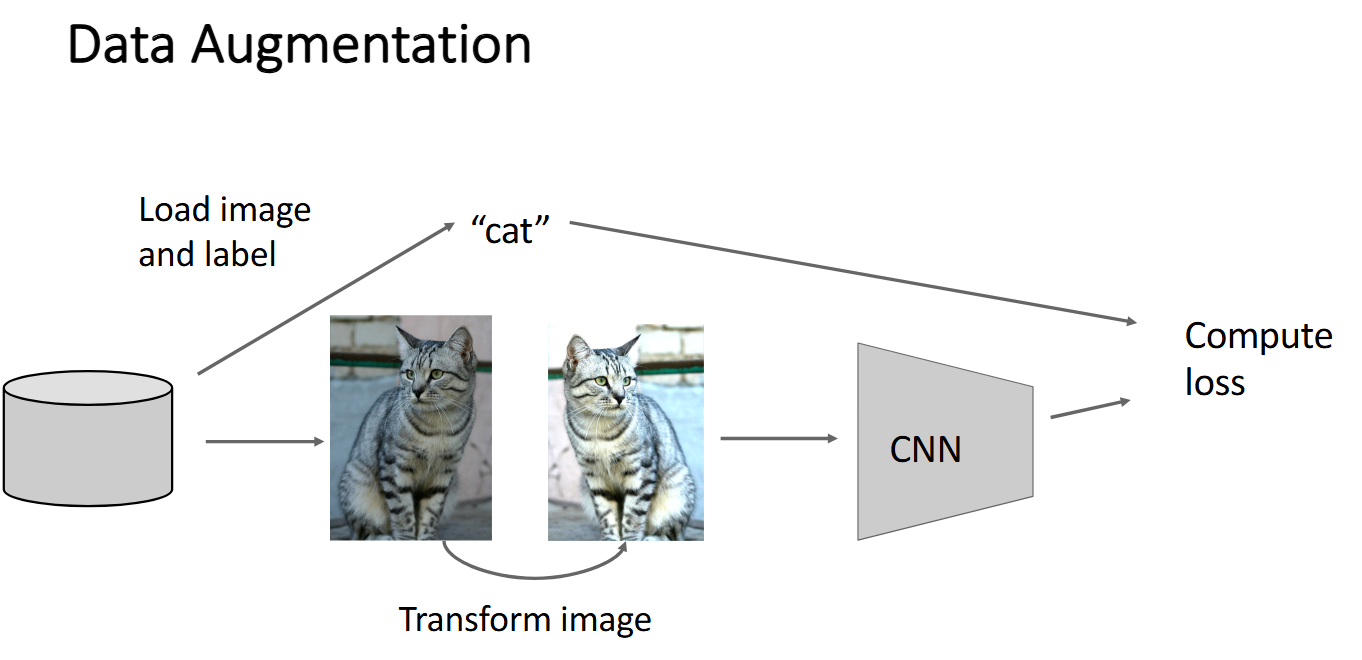
其他的如DropConnect, Stochastic Depth等就不展开了。
Reference
- EECS498
- 去相关与白化(decorrelation and whitening)