用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
在分析网站的数据结构和请求方式后,发现无法像普通分页网页那样简单地循环请求分页数据,原因主要是:
数据是通过前端 JS 动态生成的
- 网站使用 Nuxt.js(或类似 SPA 框架)渲染页面内容。
- 页面里的数据(大学排名、详细信息等)并不是直接在 HTML 里,而是存储在一个 JS 对象里,例如:
__NUXT_JSONP__("/rankings/bcur/2020", function(...) { return { data: [...], fetch: {...} }})

- 也就是说 每页的数据都在 JS 文件里预加载,浏览器解析 JS 后才渲染到页面。
- 对于爬虫而言,直接请求 HTML 无法获取 JS 渲染后的内容。
因此要爬取到全部大学排名信息无法使用urllib.request和BeautifulSoup这种传统做法
网络抓包分析后发现有一个payload.js文件拥有全部的数据
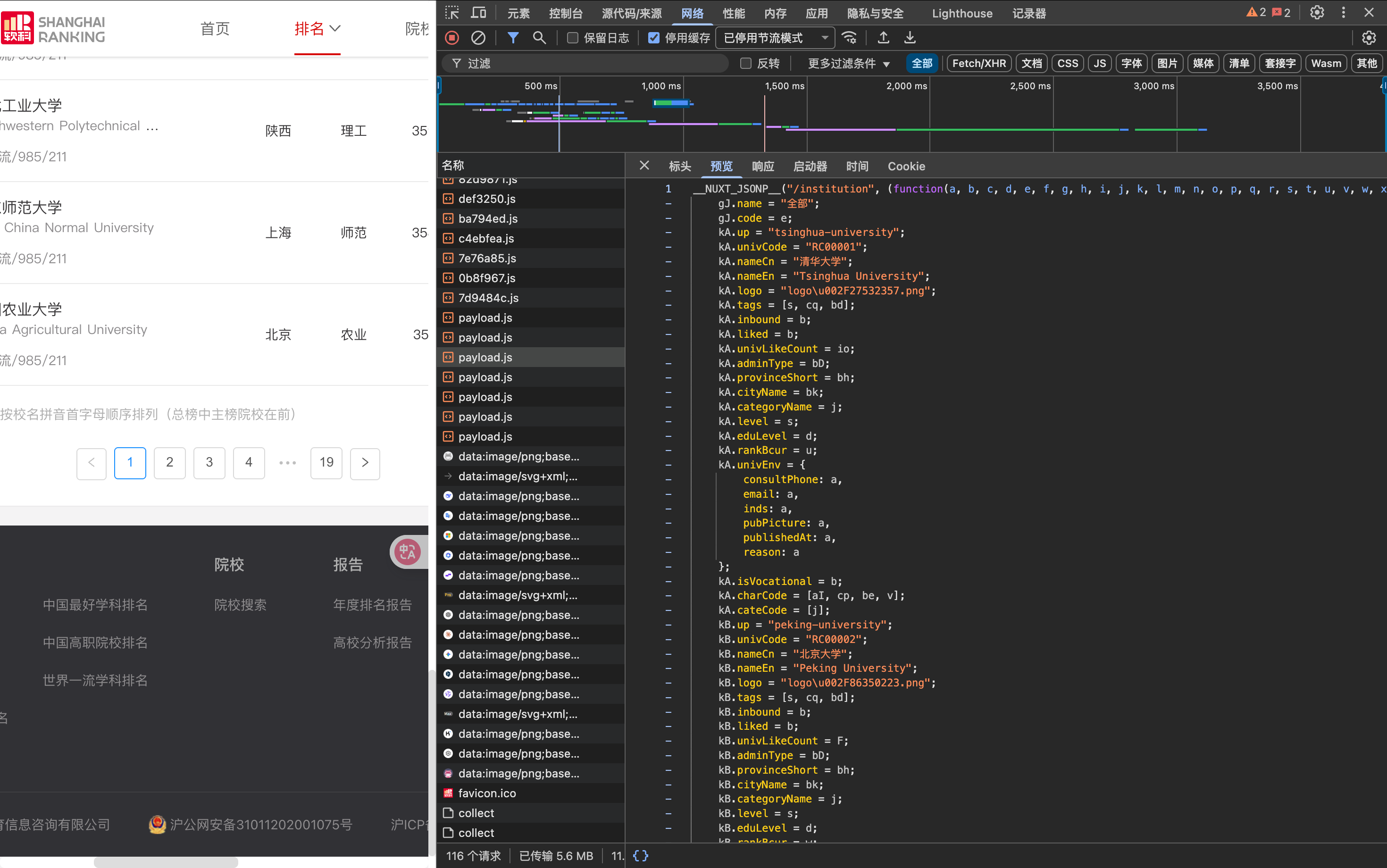
使用console查看
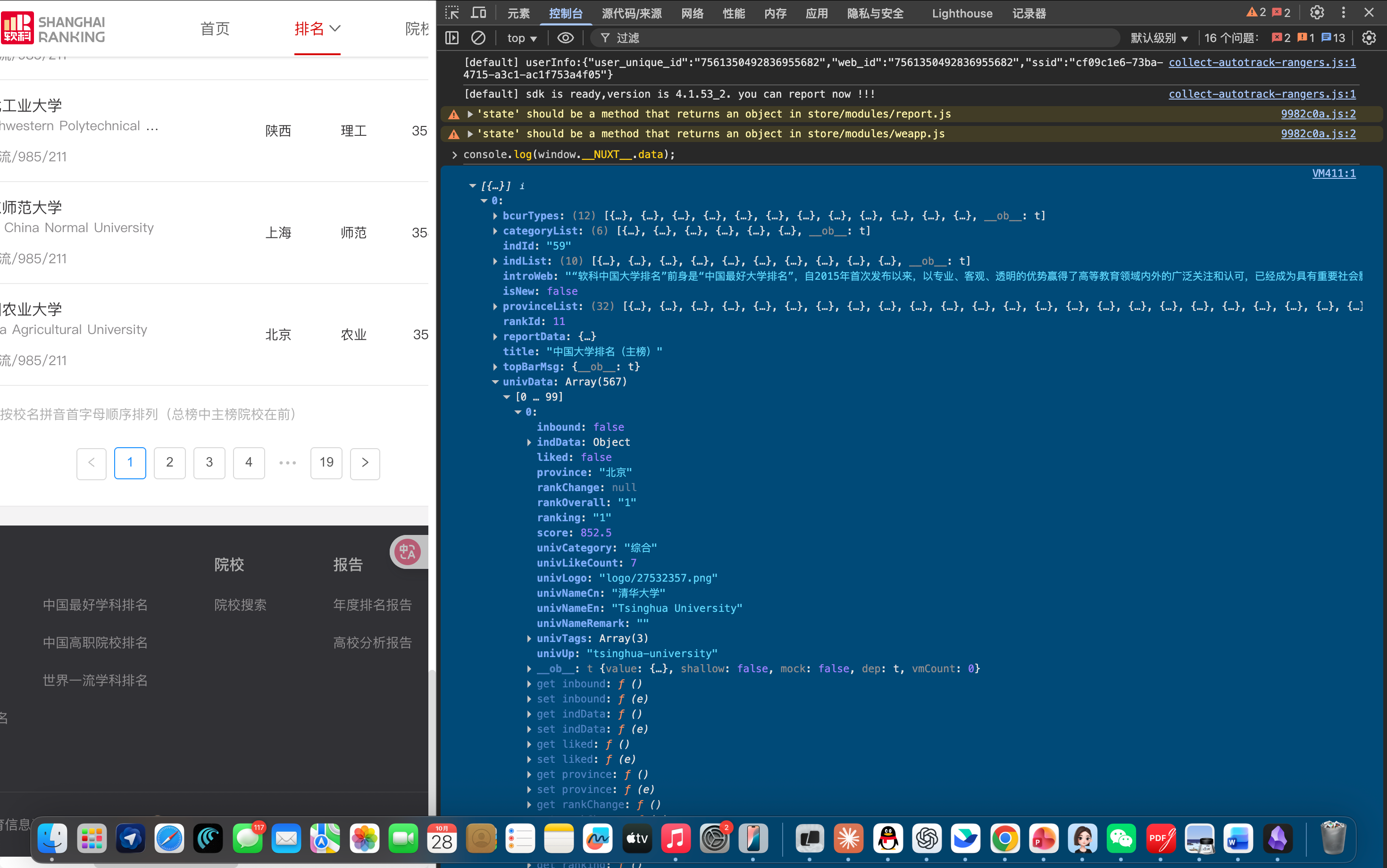
可以使用这一个console命令下载到数据


import urllib.request
import re
import csv def fetch_html(url): headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/128.0.0.0 Safari/537.36" ) } req = urllib.request.Request(url, headers=headers) with urllib.request.urlopen(req, timeout=5) as resp: return resp.read().decode('gb2312', errors='ignore') def parse_products(html): """ 使用正则从 HTML 中提取书包商品名称和价格 """ li_blocks = re.findall(r'<li[^>]*?>(.*?)</li>', html, re.S) products = [] for li in li_blocks: name_match = re.search(r'title="([^"]+)"', li) price_match = re.search(r'<span class="price_n">\s*(.*?)\s*</span>', li) if name_match and price_match: name = name_match.group(1).strip() price = price_match.group(1).replace('¥', '¥').strip() products.append((name, price)) return products def save_to_csv(products, filename="dangdang_bookbag.csv"): """ 保存为 CSV 文件 """ with open(filename, "w", newline="", encoding="utf-8-sig") as file: writer = csv.writer(file) writer.writerow(["序号", "价格", "商品名"]) for idx, (name, price) in enumerate(products, start=1): writer.writerow([idx, price, name]) print(f"\n✅ 数据已成功保存到文件:{filename}") def main(): url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab" print("开始爬取当当网“书包”商品数据...\n") try: html = fetch_html(url) products = parse_products(html) print(f"共爬取到 {len(products)} 件有效商品,正在保存到CSV...") save_to_csv(products) except Exception as e: print("❌ 爬取失败:", e) print("\n爬取任务结束!") if __name__ == "__main__": main()
运行结果:

用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
import urllib.request
import re
import csvdef fetch_html(url):headers = {"User-Agent": ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/128.0.0.0 Safari/537.36")}req = urllib.request.Request(url, headers=headers)with urllib.request.urlopen(req, timeout=5) as resp:return resp.read().decode('gb2312', errors='ignore')def parse_products(html):""" 使用正则从 HTML 中提取书包商品名称和价格 """li_blocks = re.findall(r'<li[^>]*?>(.*?)</li>', html, re.S)products = []for li in li_blocks:name_match = re.search(r'title="([^"]+)"', li)price_match = re.search(r'<span class="price_n">\s*(.*?)\s*</span>', li)if name_match and price_match:name = name_match.group(1).strip()price = price_match.group(1).replace('¥', '¥').strip()products.append((name, price))return productsdef save_to_csv(products, filename="dangdang_bookbag.csv"):""" 保存为 CSV 文件 """with open(filename, "w", newline="", encoding="utf-8-sig") as file:writer = csv.writer(file)writer.writerow(["序号", "价格", "商品名"])for idx, (name, price) in enumerate(products, start=1):writer.writerow([idx, price, name])print(f"\n✅ 数据已成功保存到文件:{filename}")def main():url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab"print("开始爬取当当网“书包”商品数据...\n")try:html = fetch_html(url)products = parse_products(html)print(f"共爬取到 {len(products)} 件有效商品,正在保存到CSV...")save_to_csv(products)except Exception as e:print("❌ 爬取失败:", e)print("\n爬取任务结束!")if __name__ == "__main__":main()

爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
import re
import urllib.request
import os
from colorama import Fore, Style, initinit(autoreset=True)# ------------------------------
# 1. 下载网页
# ------------------------------
def get_html(url):headers = {"User-Agent": "Mozilla/5.0"}req = urllib.request.Request(url, headers=headers)with urllib.request.urlopen(req) as response:html = response.read().decode("utf-8", errors="ignore")return html# ------------------------------
# 2. 提取 JPG / JPEG / PNG 图片链接
# ------------------------------
def get_image_links(html, base_url):# 匹配 jpg, jpeg, png 图片链接pattern = re.compile(r'src="([^"]+\.(?:jpg|jpeg|png))"', re.IGNORECASE)links = pattern.findall(html)domain = re.match(r"(https?://[^/]+)", base_url).group(1)full_links = []for link in links:if link.startswith("http"):full_links.append(link)elif link.startswith("/"):full_links.append(domain + link)else:full_links.append(base_url.rsplit("/", 1)[0] + "/" + link)return list(set(full_links))# ------------------------------
# 3. 下载图片
# ------------------------------
def download_images(links, folder="images"):if not os.path.exists(folder):os.makedirs(folder)for i, url in enumerate(links, start=1):try:ext = os.path.splitext(url)[1].split('?')[0] # 自动识别扩展名filename = os.path.join(folder, f"img_{i}{ext}")urllib.request.urlretrieve(url, filename)print(Fore.GREEN + f"下载成功: {filename}")except Exception as e:print(Fore.RED + f"下载失败: {url} ({e})")# ------------------------------
# 4. 主程序
# ------------------------------
if __name__ == "__main__":base_pages = ["https://news.fzu.edu.cn/yxfd.htm","https://news.fzu.edu.cn/yxfd/1.htm","https://news.fzu.edu.cn/yxfd/2.htm","https://news.fzu.edu.cn/yxfd/3.htm","https://news.fzu.edu.cn/yxfd/4.htm","https://news.fzu.edu.cn/yxfd/5.htm",]all_links = []for page in base_pages:print(f"\n正在爬取页面: {page}")html = get_html(page)links = get_image_links(html, page)print(f" 找到 {len(links)} 张图片")all_links.extend(links)# 去重all_links = list(set(all_links))print(f"\n共提取 {len(all_links)} 张图片,开始下载...\n")download_images(all_links)print("\n✅ 所有图片下载完成!")
