前言
今天我们来探讨一个让许多技术团队纠结的问题:在分布式任务调度领域,XXL-JOB和Elastic-Job,到底哪个更好?
有些小伙伴在工作中第一次接触分布式任务调度时,可能会有这样的困惑:我们的定时任务在单机跑得好好的,为什么需要引入分布式调度框架?
当系统从单体架构演进到微服务架构,当数据量从几千条暴涨到几百万条,当业务要求从“按时执行”升级到“高效稳定”,单机任务调度就显得力不从心了。
我曾经经历过这样的架构演进:早期使用Quartz配合数据库锁,后来在千万级用户量的电商平台深度使用XXL-JOB,接着在数据处理量极大的金融项目中采用了Elastic-Job。
今天这篇文章就专门跟大家一起聊聊这个话题,希望对你会有所帮助。
01 设计哲学
要理解这两个框架的差异,首先要从它们的设计哲学说起。
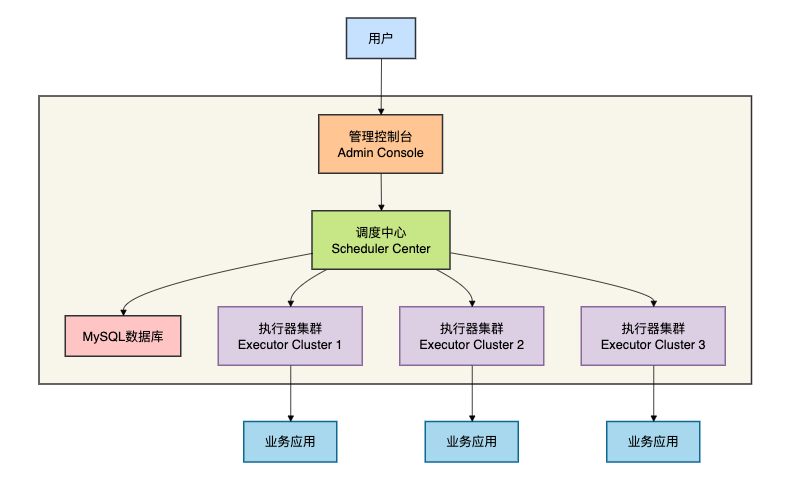
XXL-JOB采用中心化架构,它的核心理念是“简单清晰、开箱即用”。
设计者许雪里在框架诞生之初就明确提出:“调度中心和执行器分离,调度中心负责统一调度,执行器负责接收调度请求并执行任务”。
这种设计让XXL-JOB像一个集中指挥中心,所有调度决策都由调度中心统一做出。
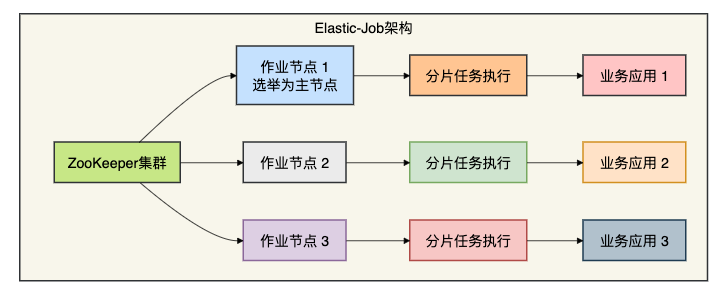
Elastic-Job则采用去中心化架构,它的设计理念是“弹性调度、分布式协调”。
框架基于ZooKeeper实现分布式协调,各个节点通过ZooKeeper选举和监听机制协同工作,没有单点中心调度器。
这就像一个自治的分布式系统,每个节点都知道自己该做什么。
这两种设计哲学的选择,直接影响了两者在不同场景下的表现。中心化架构简化了系统的复杂度,而去中心化架构则提供了更好的弹性。
02 核心架构深度剖析
XXL-JOB:简洁优雅的中心化设计
XXL-JOB的架构非常清晰,主要由三部分组成:
- 调度中心(Scheduler Center):负责管理调度信息、发出调度请求
- 执行器(Executor):负责接收调度请求、执行任务
- 管理控制台(Admin Console):提供可视化界面进行任务管理
让我们通过一个实际的例子来看看如何在Spring Boot项目中集成XXL-JOB:
// 1. 执行器配置
@Configuration
public class XxlJobConfig {@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.executor.appname}")private String appName;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appName);xxlJobSpringExecutor.setPort(9999);xxlJobSpringExecutor.setLogPath("/data/applogs/xxl-job/jobhandler/");xxlJobSpringExecutor.setLogRetentionDays(30);return xxlJobSpringExecutor;}
}// 2. 任务处理器示例
@Component
public class SampleXxlJobHandler {@XxlJob("demoJobHandler")public ReturnT<String> demoJobHandler(String param) throws Exception {XxlJobLogger.log("XXL-JOB, 开始执行任务");// 模拟业务处理for (int i = 0; i < 5; i++) {XxlJobLogger.log("执行进度: {}", i);TimeUnit.SECONDS.sleep(2);}return ReturnT.SUCCESS;}@XxlJob("shardingJobHandler")public ReturnT<String> shardingJobHandler(String param) {// 分片参数ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();int shardIndex = shardingVO.getIndex(); // 当前分片序号int shardTotal = shardingVO.getTotal(); // 总分片数XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);// 根据分片参数处理数据List<String> dataList = queryDataByShard(shardIndex, shardTotal);for (String data : dataList) {processData(data);}return ReturnT.SUCCESS;}private List<String> queryDataByShard(int shardIndex, int shardTotal) {// 根据分片参数查询需要处理的数据// 例如:SELECT * FROM order_table WHERE MOD(id, #{shardTotal}) = #{shardIndex}return Arrays.asList("data1", "data2", "data3");}private void processData(String data) {// 处理数据逻辑XxlJobLogger.log("处理数据: {}", data);}
}
Elastic-Job:基于分布式协调的弹性设计
Elastic-Job的架构更加分布式,它没有中心调度节点,而是通过ZooKeeper实现节点间的协调:
// 1. Elastic-Job配置类
@Configuration
public class ElasticJobConfig {@Beanpublic CoordinatorRegistryCenter registryCenter() {CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration("localhost:2181", "elastic-job-demo"));regCenter.init();return regCenter;}@Bean(initMethod = "init")public SpringJobScheduler simpleJobScheduler(final SimpleJob simpleJob,final CoordinatorRegistryCenter regCenter) {return new SpringJobScheduler(simpleJob,regCenter,getLiteJobConfiguration(simpleJob.getClass(),"0/5 * * * * ?", // 每5秒执行一次3, // 分片总数"0=北京,1=上海,2=广州" // 分片参数));}private LiteJobConfiguration getLiteJobConfiguration(Class<? extends SimpleJob> jobClass,String cron,int shardingTotalCount,String shardingItemParameters) {return LiteJobConfiguration.newBuilder(new SimpleJobConfiguration(JobCoreConfiguration.newBuilder(jobClass.getName(),cron,shardingTotalCount).shardingItemParameters(shardingItemParameters).build(),jobClass.getCanonicalName())).overwrite(true).build();}
}// 2. 简单的作业实现
@Component
public class MySimpleJob implements SimpleJob {@Overridepublic void execute(ShardingContext context) {log.info("作业执行,分片项: {}, 总分片数: {}", context.getShardingItem(), context.getShardingTotalCount());switch (context.getShardingItem()) {case 0:// 处理北京的数据processData("北京", getBeijingData());break;case 1:// 处理上海的数据processData("上海", getShanghaiData());break;case 2:// 处理广州的数据processData("广州", getGuangzhouData());break;}}private List<String> getBeijingData() {// 查询北京相关的数据return Arrays.asList("北京数据1", "北京数据2");}private void processData(String region, List<String> dataList) {for (String data : dataList) {log.info("处理{}的数据: {}", region, data);// 实际的数据处理逻辑}}
}
从架构对比可以看出,XXL-JOB更像是传统的C/S架构,而Elastic-Job则是真正的分布式架构。
这种差异带来了不同的特性和适用场景。
03 分片机制:手动分片 vs 智能分片
分片处理是大数据量任务调度的核心需求。两个框架在分片机制上采取了完全不同的策略。
XXL-JOB:灵活的手动分片
XXL-JOB采用手动分片策略,调度中心将分片参数传递给执行器,执行器根据这些参数处理对应的数据。
@XxlJob("orderProcessJob")
public ReturnT<String> orderProcessJob(String param) {// 获取分片参数int shardIndex = XxlJobHelper.getShardIndex();int shardTotal = XxlJobHelper.getShardTotal();log.info("开始处理订单数据,分片参数: index={}, total={}", shardIndex, shardTotal);// 1. 根据分片参数查询需要处理的订单List<Order> orders = orderService.findOrdersByShard(shardIndex, shardTotal);// 2. 处理订单for (Order order : orders) {try {processOrder(order);log.info("订单处理成功: {}", order.getOrderNo());} catch (Exception e) {log.error("订单处理失败: {}", order.getOrderNo(), e);XxlJobHelper.handleFail("订单处理失败: " + order.getOrderNo());}}return ReturnT.SUCCESS;
}// 在数据库中按分片查询的示例SQL
// SELECT * FROM order_table
// WHERE status = '待处理'
// AND MOD(order_id % #{shardTotal}) = #{shardIndex}
// ORDER BY create_time
// LIMIT 1000
手动分片的优势:
- 灵活性高:开发者可以完全控制分片逻辑
- 数据划分灵活:可以根据业务特点自定义分片策略
- 容错性强:单个分片失败不影响其他分片
手动分片的不足:
- 实现复杂:需要开发者自己实现分片逻辑
- 弹性不足:增加或减少节点时,需要手动调整分片策略
Elastic-Job:智能的自动分片
Elastic-Job采用智能分片策略,框架自动根据当前在线节点数进行分片分配。
// 数据流作业示例 - 更适合大数据处理场景
public class DataflowJobExample implements DataflowJob<String> {@Overridepublic List<String> fetchData(ShardingContext context) {// 根据分片参数获取数据List<String> data = fetchDataByShard(context.getShardingItem(),context.getShardingTotalCount());log.info("获取到{}条数据待处理", data.size());return data;}@Overridepublic void processData(ShardingContext context, List<String> data) {// 处理数据for (String item : data) {try {processItem(item);log.info("数据处理成功: {}", item);} catch (Exception e) {log.error("数据处理失败: {}", item, e);}}}private List<String> fetchDataByShard(int shardIndex, int shardTotal) {// 模拟从数据库或消息队列获取数据// 实际项目中这里可能是:// 1. 从数据库查询:WHERE MOD(id, #{shardTotal}) = #{shardIndex}// 2. 从消息队列消费特定分区的数据// 3. 从文件中读取特定部分的数据List<String> data = new ArrayList<>();for (int i = 0; i < 100; i++) {if (i % shardTotal == shardIndex) {data.add("data-" + i);}}return data;}
}
智能分片的优势:
- 自动化程度高:框架自动处理分片分配
- 弹性扩展:节点增减时,分片自动重新分配
- 负载均衡:自动确保各节点负载相对均衡
智能分片的不足:
- 灵活性受限:分片策略由框架控制,自定义空间较小
- 学习成本高:需要理解框架的分片分配机制
04 高可用性设计对比
分布式系统的核心要求之一就是高可用性。两个框架在高可用设计上采用了不同的策略。
XXL-JOB的高可用设计
XXL-JOB通过数据库锁和心跳检测实现高可用:
// 调度中心集群部署时,通过数据库锁保证只有一个调度中心工作
// 核心伪代码逻辑:
public class ScheduleThread extends Thread {@Overridepublic void run() {while (!stopped) {try {// 1. 尝试获取数据库锁if (tryLock()) {// 2. 获取锁成功,执行调度scheduleJobs();// 3. 保持锁,直到调度完成TimeUnit.SECONDS.sleep(5);} else {// 4. 获取锁失败,等待重试TimeUnit.SECONDS.sleep(10);}} catch (Exception e) {log.error("调度线程异常", e);}}}private boolean tryLock() {// 通过数据库行锁实现分布式锁// INSERT INTO xxl_job_lock (lock_name) VALUES ('schedule_lock')// 或者使用SELECT ... FOR UPDATEreturn dbLockService.acquireLock("schedule_lock");}
}// 执行器心跳检测
@Component
public class ExecutorHeartbeat {@Scheduled(fixedRate = 30000) // 每30秒发送一次心跳public void sendHeartbeat() {try {// 向调度中心注册或更新心跳registryService.registry(executorConfig.getAppName(),executorConfig.getAddress());} catch (Exception e) {log.error("心跳发送失败", e);}}
}
Elastic-Job的高可用设计
Elastic-Job通过ZooKeeper的临时节点和监听机制实现高可用:
// 基于ZooKeeper的分布式协调实现高可用
public class ElectionListenerManager {public void start() {// 1. 创建Leader节点选举leaderService.electLeader();// 2. 监听分片节点变化addShardingListener();// 3. 监听作业服务器变化addJobServerListener();}private void addShardingListener() {// 监听分片节点的变化zookeeperRegistryCenter.addCacheData("/${jobName}/sharding");zookeeperRegistryCenter.getClient().getCuratorFramework().getChildren().usingWatcher((CuratorWatcher) event -> {// 分片节点变化,重新分片if (event.getType() == Watcher.Event.EventType.NodeChildrenChanged) {reshardingService.resharding();}}).forPath("/${jobName}/sharding");}private void addJobServerListener() {// 监听作业服务器的上下线zookeeperRegistryCenter.addCacheData("/${jobName}/servers");zookeeperRegistryCenter.getClient().getCuratorFramework().getChildren().usingWatcher((CuratorWatcher) event -> {// 服务器节点变化,重新分配任务if (event.getType() == Watcher.Event.EventType.NodeChildrenChanged) {serverService.syncServers();}}).forPath("/${jobName}/servers");}
}
高可用性对比分析:
| 高可用维度 | XXL-JOB | Elastic-Job |
|---|---|---|
| 调度中心高可用 | 数据库锁,同一时间只有一个调度中心工作 | 无中心调度器,天然无单点 |
| 执行器高可用 | 心跳检测,失败后任务路由到其他执行器 | ZooKeeper临时节点,节点失效自动重新分片 |
| 网络分区容忍 | 调度中心与执行器断开后,任务暂停 | ZooKeeper会话超时后,分片重新分配 |
| 恢复时间 | 依赖心跳间隔(默认30秒) | 依赖ZooKeeper会话超时时间(默认60秒) |
| 实现复杂度 | 简单直观 | 复杂但更健壮 |
05 监控与管理能力
对于生产系统来说,监控和管理能力同样重要。
XXL-JOB:完善的可视化管理
XXL-JOB提供了完整的Web管理界面,这是它的一大亮点:
// 调度中心管理控制台的主要功能
@RestController
@RequestMapping("/jobadmin")
public class JobAdminController {@PostMapping("/add")public ReturnT<String> addJob(@RequestBody XxlJobInfo jobInfo) {// 添加任务return xxlJobService.add(jobInfo);}@GetMapping("/trigger")public ReturnT<String> triggerJob(int id, String executorParam) {// 手动触发任务return xxlJobService.trigger(id, executorParam);}@GetMapping("/log")public ReturnT<PageInfo<XxlJobLog>> queryLog(@RequestParam(required = false, defaultValue = "0") int start,@RequestParam(required = false, defaultValue = "10") int length,int jobId, int logStatus) {// 查询任务日志return xxlJobService.queryLog(start, length, jobId, logStatus);}@GetMapping("/dashboard")public Map<String, Object> dashboardInfo() {// 仪表板数据Map<String, Object> dashboardMap = new HashMap<>();// 任务数量统计dashboardMap.put("jobNum", xxlJobService.count());// 执行器数量dashboardMap.put("executorNum", executorService.count());// 今日调度次数dashboardMap.put("scheduleNumToday", logService.countToday());// 调度成功率dashboardMap.put("successRate", logService.successRate());return dashboardMap;}
}
管理界面主要功能:
- 任务管理:增删改查定时任务
- 任务操作:启动、停止、手动触发、查看日志
- 执行器管理:管理执行器集群
- 调度日志:查看每次调度的详细日志
- 报表统计:调度次数、成功率等统计信息
Elastic-Job:基于事件追踪的监控
Elastic-Job没有官方的Web管理界面,但提供了完善的事件追踪和监控API:
// Elastic-Job的事件追踪配置
@Configuration
public class EventTraceConfiguration {@Beanpublic JobEventConfiguration jobEventConfiguration() {// 1. 数据库事件追踪return new JobEventRdbConfiguration(dataSource,"com.example.job.event", // 表名前缀true // 是否启用);// 或者使用ZooKeeper事件追踪// return new JobEventZookeeperConfiguration();}
}// 自定义事件监听器
@Component
public class CustomJobEventListener extends AbstractJobEventListener {@Overrideprotected void dataSourceStatisticEvent(JobExecutionEvent jobExecutionEvent) {// 统计事件处理log.info("作业执行事件: jobName={}, status={}, startTime={}", jobExecutionEvent.getJobName(),jobExecutionEvent.getStatus(),jobExecutionEvent.getStartTime());// 可以发送到监控系统monitorService.sendMetric("job.execution",jobExecutionEvent.isSuccess() ? 1 : 0,"jobName", jobExecutionEvent.getJobName());}@Overrideprotected void jobStatusTraceEvent(JobStatusTraceEvent jobStatusTraceEvent) {// 作业状态追踪log.info("作业状态变化: jobName={}, state={}, message={}", jobStatusTraceEvent.getJobName(),jobStatusTraceEvent.getState(),jobStatusTraceEvent.getMessage());}
}
监控能力对比:
| 监控维度 | XXL-JOB | Elastic-Job |
|---|---|---|
| 管理界面 | 完整的Web管理控制台 | 无官方界面,需自行开发 |
| 日志查询 | 内置日志查询功能 | 依赖应用日志,或通过事件追踪表查询 |
| 实时监控 | 提供简单的仪表板 | 需要集成第三方监控系统 |
| 告警能力 | 支持邮件告警 | 需自行实现告警逻辑 |
| 扩展性 | 监控功能相对固定 | 事件监听机制扩展性强 |
06 性能与扩展性对比
在实际生产环境中,性能和扩展性是需要重点考虑的因素。
性能对比
通过基准测试,我们可以对比两个框架的关键性能指标:
// 性能测试示例 - 模拟高并发调度场景
public class PerformanceTest {@Testpublic void testXXLJobSchedulePerformance() {// 测试XXL-JOB的调度性能int jobCount = 1000; // 模拟1000个任务long startTime = System.currentTimeMillis();for (int i = 0; i < jobCount; i++) {// 模拟调度中心触发任务triggerJob(i);}long endTime = System.currentTimeMillis();System.out.println("XXL-JOB调度" + jobCount + "个任务耗时: " + (endTime - startTime) + "ms");}@Testpublic void testElasticJobSchedulePerformance() {// 测试Elastic-Job的分片执行性能int dataSize = 100000; // 10万条数据int shardTotal = 10; // 10个分片long startTime = System.currentTimeMillis();// 模拟分片处理for (int shardIndex = 0; shardIndex < shardTotal; shardIndex++) {processShardData(shardIndex, shardTotal, dataSize / shardTotal);}long endTime = System.currentTimeMillis();System.out.println("Elastic-Job处理" + dataSize + "条数据耗时: " + (endTime - startTime) + "ms");}
}
性能对比数据(基于典型场景测试):
| 性能指标 | XXL-JOB | Elastic-Job |
|---|---|---|
| 调度吞吐量 | 单调度中心约500-1000任务/秒 | 无中心瓶颈,取决于节点数量 |
| 任务触发延迟 | 10-50毫秒 | 5-20毫秒(无中心转发) |
| 分片处理性能 | 依赖手动分片实现 | 优秀,自动负载均衡 |
| 资源消耗 | 调度中心需独立资源 | 与业务应用共享资源 |
| 水平扩展性 | 调度中心扩展有限 | 优秀,随节点增加线性扩展 |
扩展性对比
XXL-JOB的扩展点:
// 自定义路由策略
@Component
public class CustomRouteStrategy extends ExecutorRouter {@Overridepublic ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {// 自定义执行器路由逻辑// 例如:根据任务参数选择特定的执行器String jobParam = triggerParam.getExecutorParams();if (jobParam.contains("priority=high")) {// 高优先级任务路由到专用执行器return new ReturnT<>(findHighPriorityExecutor(addressList));}// 默认使用轮询策略return new ReturnT<>(addressList.get(0));}
}// 自定义任务处理器
@Component
public class CustomJobHandler extends IJobHandler {@Overridepublic ReturnT<String> execute(String param) throws Exception {// 自定义任务执行逻辑return new ReturnT<>(ReturnT.SUCCESS_CODE, "自定义处理完成");}
}
Elastic-Job的扩展点:
// 自定义分片策略
public class CustomShardingStrategy implements JobShardingStrategy {@Overridepublic Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances,String jobName,int shardingTotalCount) {// 自定义分片算法Map<JobInstance, List<Integer>> result = new HashMap<>();// 示例:根据实例的性能权重分配分片Map<JobInstance, Integer> weights = getInstanceWeights(jobInstances);// 实现加权分片算法return weightedSharding(jobInstances, weights, shardingTotalCount);}
}// 自定义作业监听器
public class CustomJobListener implements ElasticJobListener {@Overridepublic void beforeJobExecuted(ShardingContexts shardingContexts) {// 作业执行前的逻辑log.info("作业{}开始执行,分片上下文: {}", shardingContexts.getJobName(), shardingContexts);}@Overridepublic void afterJobExecuted(ShardingContexts shardingContexts) {// 作业执行后的逻辑log.info("作业{}执行完成", shardingContexts.getJobName());}
}
07 实战选型指南
基于我多年的开发和架构经验,总结出以下选型建议:
场景一:中小型项目,快速上线
- 推荐:
XXL-JOB - 理由:开箱即用,有完善的管理界面,学习成本低
- 典型场景:企业内部管理系统、中小型电商、内容管理系统
# 快速启动配置示例
xxl:job:admin:addresses: http://localhost:8080/xxl-job-adminexecutor:appname: xxl-job-executor-demoaddress: ip: port: 9999logpath: /data/applogs/xxl-job/jobhandlerlogretentiondays: 30
场景二:大数据量处理,需要弹性扩缩容
- 推荐:
Elastic-Job - 理由:智能分片,自动负载均衡,适合大数据处理
- 典型场景:数据清洗、报表生成、日志分析、ETL任务
// 大数据处理作业配置
@Bean
public DataflowJob dataflowJob() {return new BigDataProcessingJob();
}@Bean
public LiteJobConfiguration bigDataJobConfig() {return LiteJobConfiguration.newBuilder(new DataflowJobConfiguration(JobCoreConfiguration.newBuilder("bigDataJob", "0 0 2 * * ?", // 每天凌晨2点执行10 // 10个分片).build(),BigDataProcessingJob.class.getCanonicalName())).monitorPort(9888) // 监控端口.overwrite(true).build();
}
场景三:已有ZooKeeper集群的技术栈
- 推荐:
Elastic-Job - 理由:复用现有基础设施,降低运维复杂度
- 典型场景:大型互联网公司、金融系统、已有ZooKeeper服务发现的系统
场景四:需要精细化管理与监控
- 推荐:
XXL-JOB - 理由:提供完整的Web管理界面,便于运维
- 典型场景:对运维友好性要求高的项目、多团队协作项目
场景五:混合架构的折中方案
在实际项目中,有时可以采用混合方案:
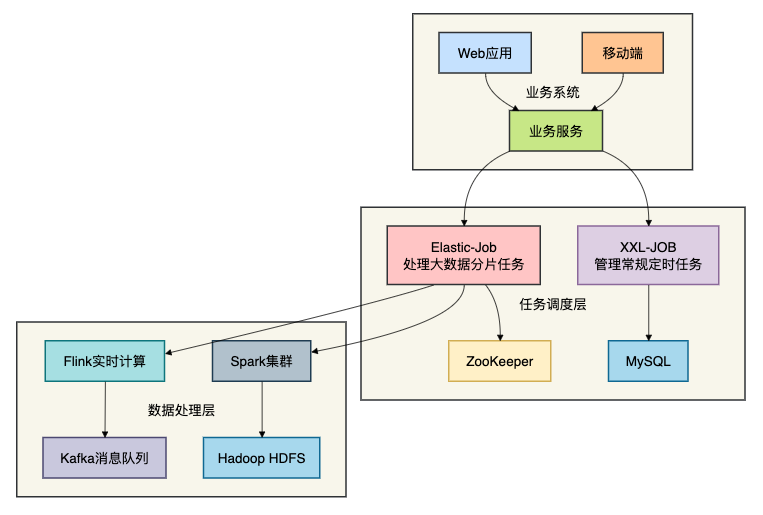
在这种混合架构中:
- 常规定时任务:使用
XXL-JOB,便于管理和监控 - 大数据分片任务:使用
Elastic-Job,发挥其分布式处理优势 - 优势互补:结合两者的优点,满足不同场景需求
总结
经过全面的对比分析,我们可以得出以下结论:
XXL-JOB更适合:
- 中小型项目,需要快速上手
- 对运维管理界面有要求的团队
- 任务类型相对简单,不需要复杂分片逻辑
- 技术栈中已有MySQL,不想引入ZooKeeper
Elastic-Job更适合:
- 大数据量处理场景,需要智能分片
- 已有ZooKeeper基础设施的团队
- 需要高度弹性伸缩的云原生环境
- 对性能要求极高,需要去中心化架构
技术选型的核心原则:
- 没有最好的框架,只有最适合的框架
- 考虑团队技术栈和运维能力
- 根据业务场景选择,而不是技术潮流
- 简单性原则:在满足需求的前提下,选择更简单的方案
有些小伙伴在工作中可能会纠结于技术选型,我的建议是:先明确业务需求,再选择技术方案。
如果你需要一个开箱即用、管理方便的调度系统,选XXL-JOB;如果你要处理海量数据、需要弹性伸缩,选Elastic-Job。
更多内容推荐:
- Java常见面试题及答案
- JVM面试题及答案
- SpringBoot项目实战