语义指纹检测是什么?搞懂原理你就知道怎么降AI了
你有没有想过一个问题——知网、维普这些AI检测工具,到底是怎么判断一段文字是不是AI写的?是一个词一个词比对吗?还是跟某个数据库去匹配?
都不是。目前主流AI检测工具用的核心技术叫"语义指纹检测"。搞懂了这个原理,你就能理解为什么有些降AI方法管用、有些不管用,也就知道该怎么有针对性地降了。
我花了不少时间研究这个领域的论文和技术文档,今天尽量用大白话把这事讲明白。
什么是语义指纹
先打个比方。每个人都有指纹,指纹的纹路是独一无二的,警察靠指纹就能确认一个人的身份。
文本也有"指纹"——不是某个具体的词或句子,而是整段文字在统计意义上的特征模式。包括用词习惯、句式偏好、逻辑连接方式、信息密度分布等等。这些特征组合在一起,就形成了文本的"语义指纹"。
AI生成的文本有自己独特的语义指纹,跟人类写的文本是不同的。检测工具做的事情就是提取待检测文本的语义指纹,然后判断它更接近AI的指纹模式还是人类的指纹模式。
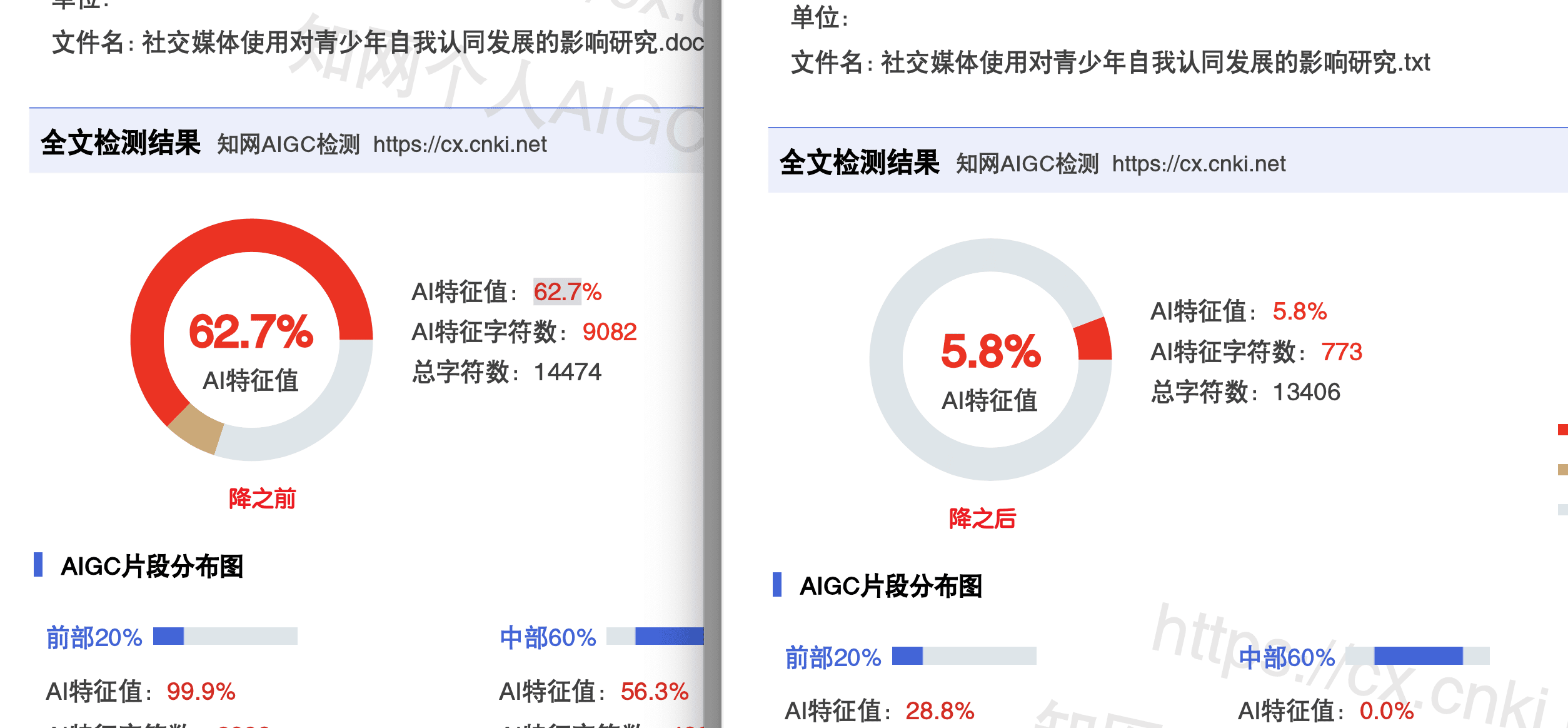
上图是知网AIGC检测的详细报告。你能看到它不是简单给一个通过或不通过的结论,而是给出了逐段的检测概率。这背后就是语义指纹分析在起作用。
语义指纹检测的三个核心维度
语义指纹检测不是只看一个指标,而是从多个维度综合判断。根据我的研究,目前主流检测工具主要看这三个维度。
维度一:困惑度(Perplexity)分析
困惑度是信息论里的概念,衡量的是一个语言模型对某段文本的"惊讶程度"。
直白点说:如果一段话里每个词出现在这个位置都非常"合理",困惑度就低;如果有些词的出现让模型"意外",困惑度就高。
AI生成的文本困惑度普遍偏低,因为AI本来就是按"最合理"的方式选词的。人写的文本困惑度更高,因为人的选词带有个人风格、情绪影响、甚至笔误。
举个例子:
AI可能写:经济发展带来了人民生活水平的显著提高。
人可能写:日子确实是比以前好过了,起码我妈现在买菜不像以前那样一分钱掰两半花了。
第二句的困惑度明显高于第一句,因为"一分钱掰两半花"这种表达在语言模型看来概率很低,但它恰恰是真人才会写出来的。
维度二:N-gram分布模式
N-gram是自然语言处理的基础概念,指的是文本中连续的N个词(或字)的组合。
AI文本的N-gram分布有个特点——高频搭配出现得特别多。比如"进行了深入的""取得了显著的""随着...的不断"这些组合,在AI文本中的出现频率远高于人类文本。
检测工具会统计待检测文本中各种N-gram的分布情况,如果高频搭配的比例超过某个阈值,就倾向于判定为AI生成。
我测过一组数据:同一个话题的AI文本和人类文本各1000字,AI文本中3-gram高频搭配(在训练语料中出现频率前10%的组合)占比约38%,人类文本只有17%。差距还是很明显的。
维度三:语义向量聚类
这个稍微复杂一点。检测工具会把文本中的句子转化为向量(可以理解为多维空间中的一个点),然后看这些点的分布情况。
AI生成的文本,句子的语义向量往往聚得比较紧——因为AI写东西逻辑连贯、主题聚焦,句子之间的语义距离比较近。人写的文本向量分布更分散,因为人会跑题、会突然换个角度、会在严肃论述中插一句吐槽。
简单说,AI的文本像排列整齐的方阵,人的文本像自由散步的人群。检测工具就是在看你的文本长得更像方阵还是人群。
搞懂原理之后,降AI的思路就清楚了
理解了上面三个维度,降AI的思路就不再是瞎蒙了。你需要做的就是:
针对困惑度:引入"不那么标准"的表达。不是写错别字,而是用更个性化、更口语化的表达替代AI的"标准答案"。
针对N-gram:打破高频搭配。"进行了深入的分析"可以改成"仔细扒了一遍数据";"取得了显著的成效"可以改成"效果比预期好不少"。
针对语义聚类:让你的论述不要太"规矩"。适当跑题、适当插入与主题相关但角度不同的内容,让语义向量分布更分散。
下面是三个维度的改写策略对比:
| 检测维度 | AI文本特征 | 针对性改写策略 | 改写难度 | 降幅预期 |
|---|---|---|---|---|
| 困惑度 | 偏低,选词过于"标准" | 口语化、个性化表达 | 低 | 检测率降30%到50% |
| N-gram分布 | 高频搭配占比高 | 打破固定搭配 | 中 | 检测率降20%到40% |
| 语义聚类 | 向量分布密集 | 插入多角度内容 | 高 | 检测率降10%到30% |
三个维度同时处理效果最好,但如果只能选一个,优先处理困惑度,因为它最容易操作,效果也最直接。
工具降AI的底层逻辑也是这个
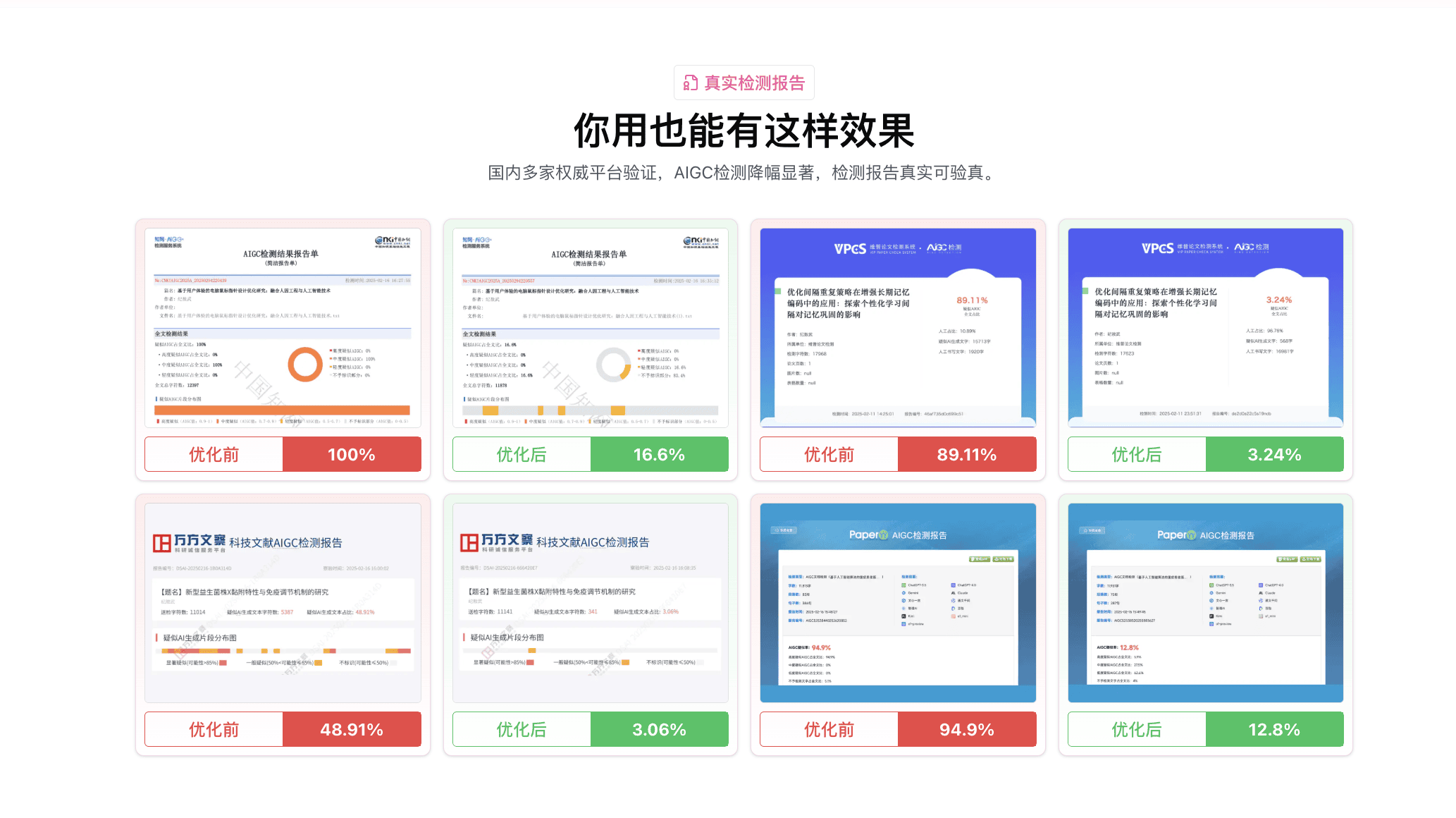
你可能会好奇,像嘎嘎降AI(aigcleaner.com)这类工具是怎么工作的?其实它们底层也是在针对这三个维度做处理。
好的降AI工具不是简单换词,而是对整段文本进行语义层面的重构——提高困惑度、打散N-gram分布、增加语义向量的离散性。这也是为什么工具处理的效果往往比手动换词好得多。
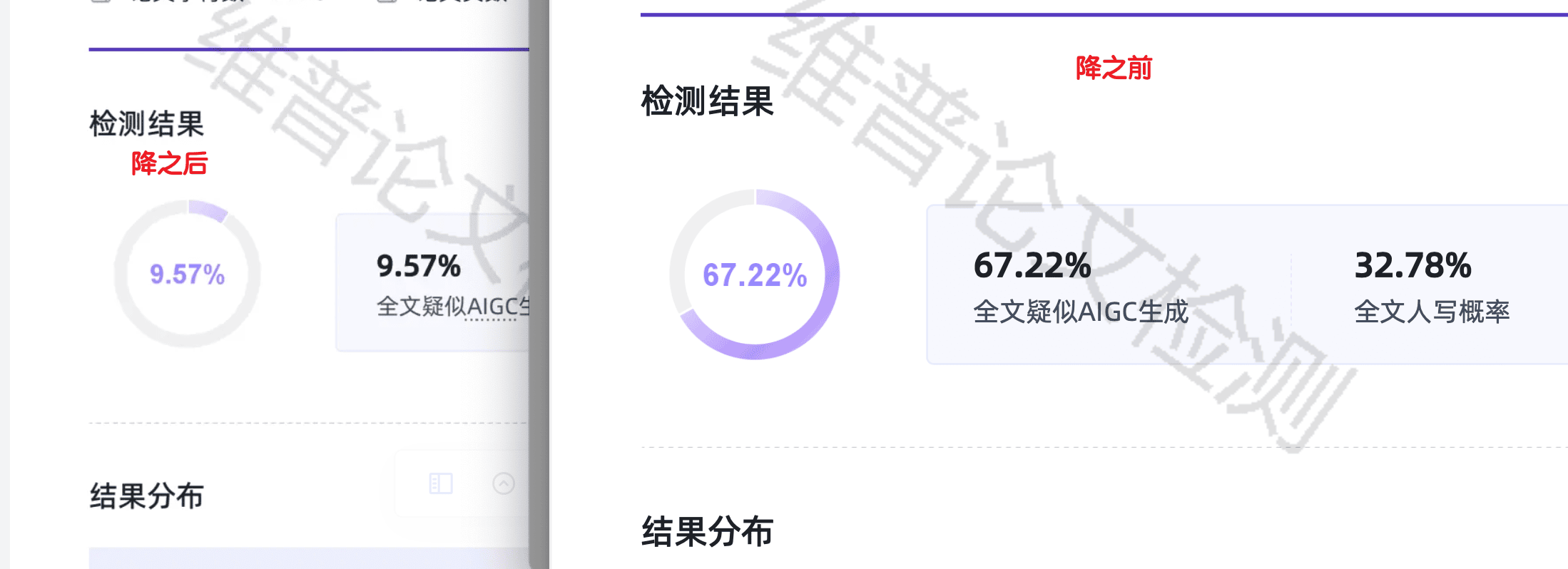
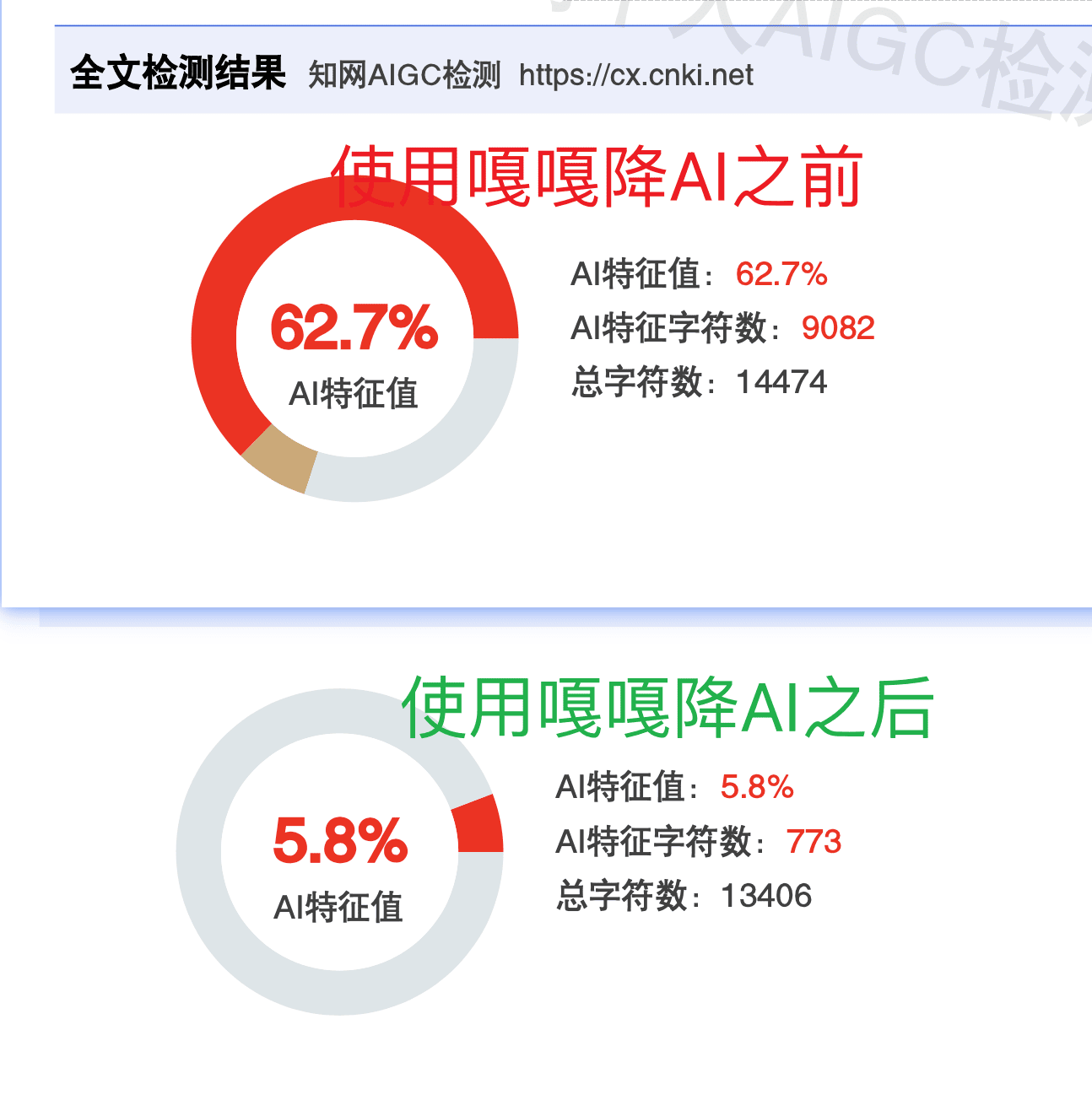
上图是嘎嘎降AI在维普平台的实测效果,从67.22%降到9.57%。知网那边的数据更好,62.7%降到5.8%。这个降幅说明工具确实在有效地改变文本的语义指纹。
比话(bihuapass.com)和率零(0ailv.com)也是类似的原理,只是具体的算法和侧重点不同。比话偏向保留学术语感,率零更偏速度。去AIGC(quaigc.com)走的是另一条技术路线,可以当作互补方案。
有一点很重要:建议把全文上传进去降,不要只降某几段,否则效果可能不太好。从语义指纹的角度很好理解这一点——如果你只处理了几段,处理过和没处理过的段落语义指纹风格不一致,这种不一致本身就是一个检测信号。检测工具看到一篇文章里有两种完全不同的语义指纹模式,反而会更加怀疑。
为什么有些降AI方法不管用
明白了语义指纹的原理,我们也能解释为什么一些常见的"降AI方法"其实不太管用。
方法一:纯换近义词
换近义词不改变句子结构,困惑度几乎不变,N-gram分布也只是微调,效果自然有限。我测过,纯换近义词的降幅通常只有15%到20%。
方法二:乱序句子
把句子顺序打乱可以影响语义聚类,但如果每句话的内部结构没变,困惑度和N-gram照样暴露。而且乱序容易导致逻辑不通。
方法三:加大量引用
引用别人的原文确实不是AI生成的,但检测工具会识别引用并排除,只检测你自己写的部分。靠加引用稀释检测率,治标不治本。
方法四:混入错别字
这个方法确实能提高困惑度,但也太损了。一篇到处是错别字的论文,检测率可能降下来了,答辩也过不了。

未来语义指纹检测会往哪走
最后聊聊趋势。2026年的AI检测技术比2024年精度高了不少,主要是两个方向的进步:
一个是多维度交叉验证。以前的检测工具可能只看困惑度一个指标,现在是多个维度同时分析、交叉印证,误判率降了很多,但漏检率也在降。
另一个是针对"改写后文本"的二次检测能力。检测工具已经开始训练专门识别"被改写过的AI文本"的模型。这意味着简单的改写可能会逐渐失效,未来降AI需要更深层次的语义重构。
这也是为什么我一直建议大家理解原理而不是只学方法。方法会过时,但原理不会。你知道检测工具在看什么,就能始终找到应对的方向。
总结一下:语义指纹检测通过困惑度、N-gram分布、语义向量聚类三个维度来识别AI文本。降AI的本质就是改变文本的语义指纹,让它更接近人类的特征模式。理解了这个,不管是手动改写还是用工具处理,你都能做到心里有数。