物流行业信息咨询智能问答系统
2025-09-20 15:58 dribs 阅读(0) 评论(0) 收藏 举报背景
练手rag项目
LLM都是基于过去的经验数据进行训练完成;无法处理获取实时的信息,需结合RAG实现;处理私域的数据
流程原理
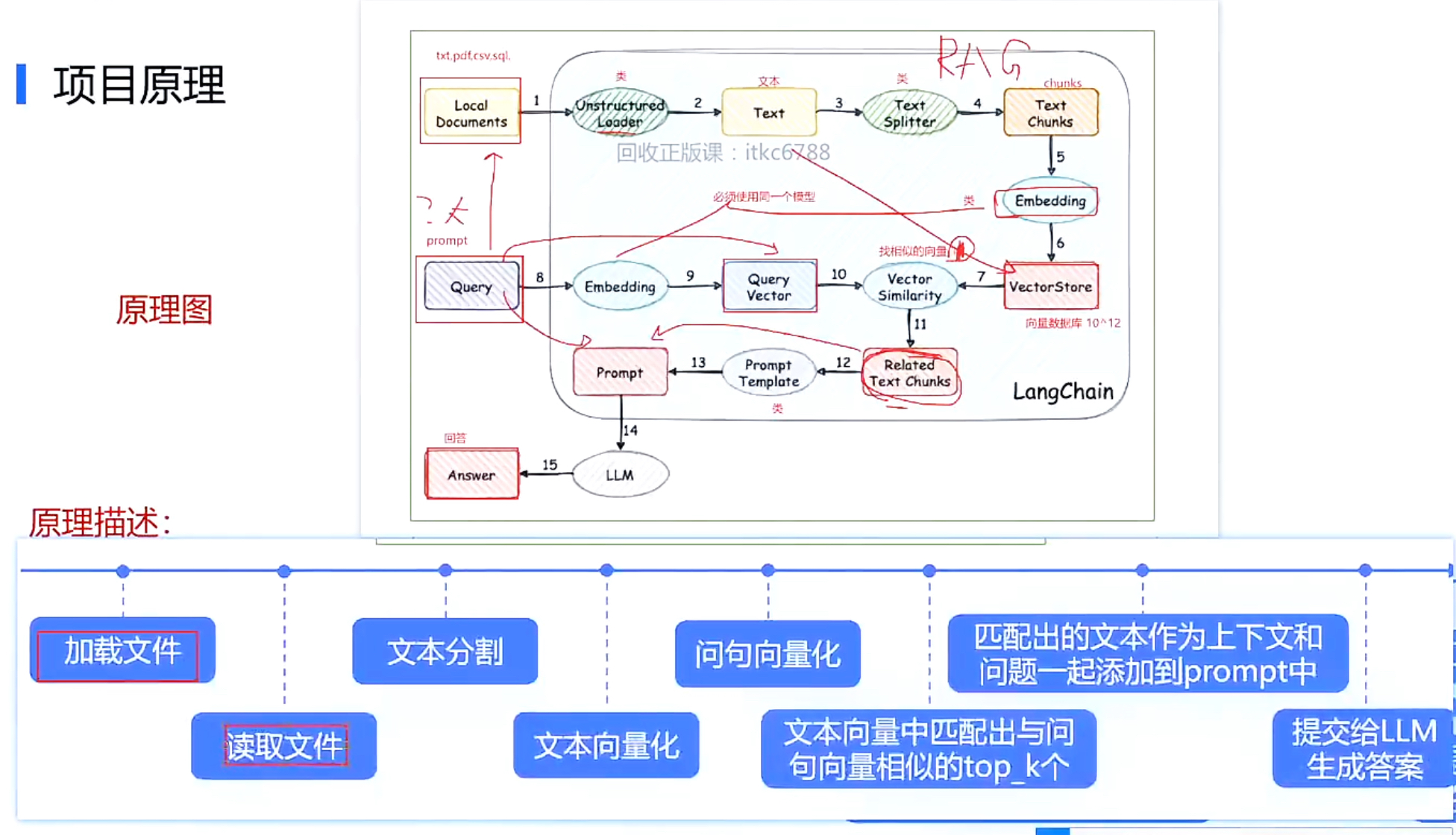
项目流程
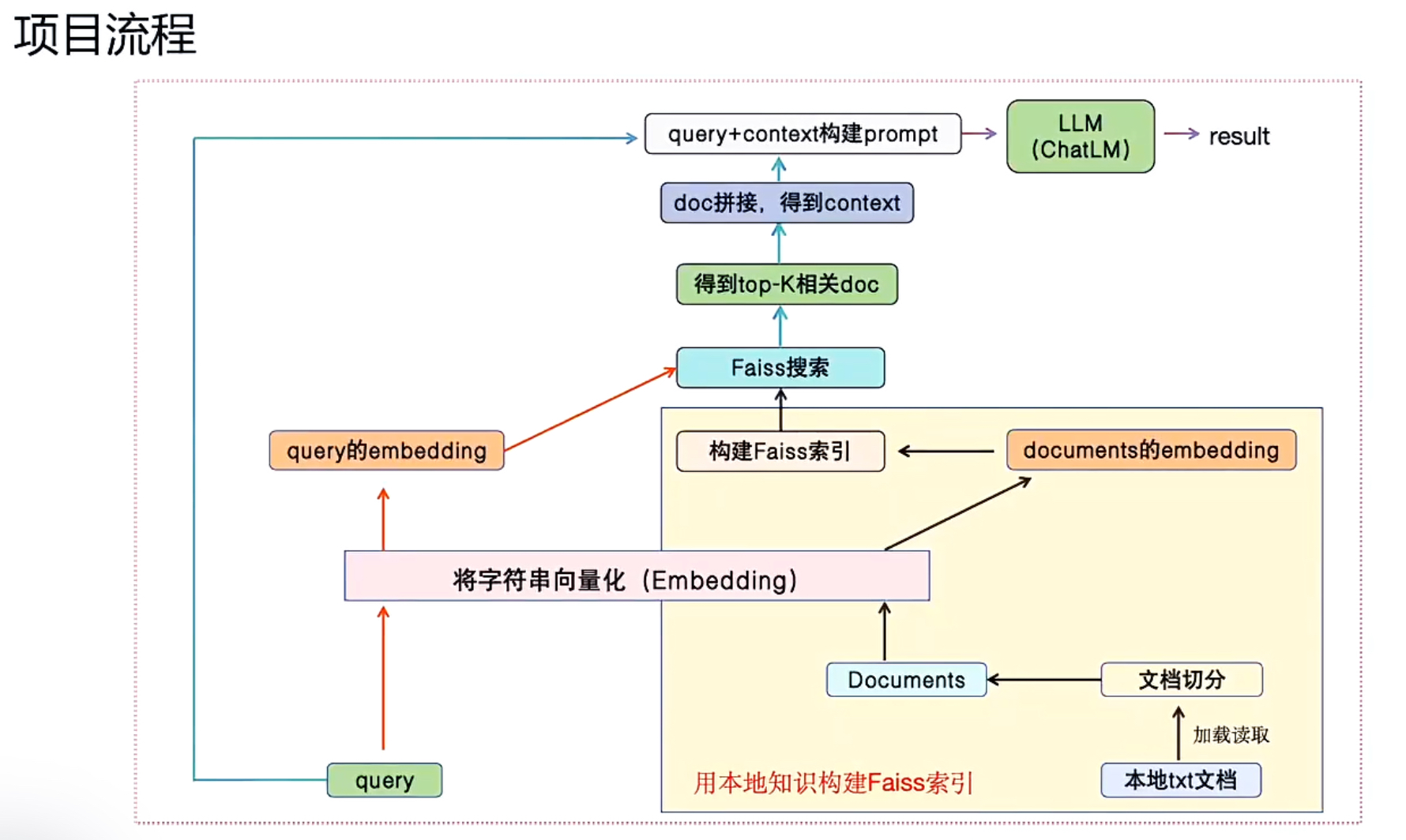
依赖关系
langchain==0.1.20 faiss-gpu==1.7.2 sentence-transformers==2.2.2
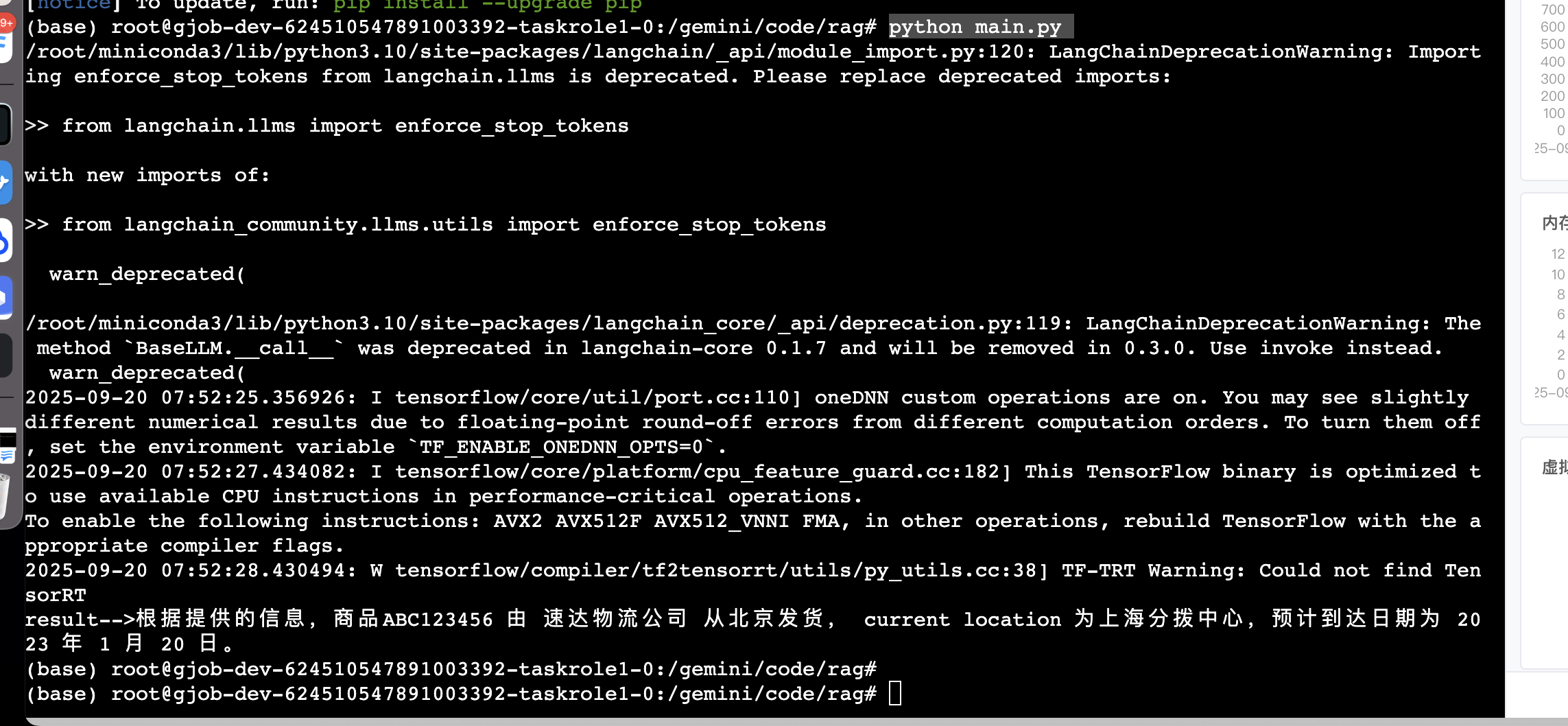
执行结果
目录结构
tree . ├── faiss │ ├── camp │ │ ├── index.faiss │ │ └── index.pkl │ └── logistics │ ├── index.faiss │ └── index.pkl ├── get_vector.py ├── m3e-base │ ├── 1_Pooling │ │ └── config.json │ ├── config.json │ ├── gitattributes │ ├── model.safetensors │ ├── modules.json │ ├── pytorch_model.bin │ ├── sentence_bert_config.json │ ├── special_tokens_map.json │ ├── tokenizer.json │ ├── tokenizer_config.json │ └── vocab.txt ├── main.py ├── model.py ├── new_demo.py ├── test.py └── 物流信息.txt
main.py
# coding:utf-8
# 导入必备的工具包
from langchain.prompts import PromptTemplate
from get_vector import *
from model import ChatGLM2
# 加载FAISS向量库
EMBEDDING_MODEL = './m3e-base'
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL)
db = FAISS.load_local(r'faiss/camp',embeddings,allow_dangerous_deserialization=True)def get_related_content(related_docs):related_content = []for doc in related_docs:related_content.append(doc.page_content.replace('\n\n', '\n'))return '\n'.join(related_content)def define_prompt():question = '我买的商品ABC123456来自于哪个仓库,从哪出发的,预计什么到达'docs = db.similarity_search(question, k=1)# print(f'docs-->{docs}')related_docs = get_related_content(docs)# 构建模板PROMPT_TEMPLATE = """基于以下已知信息,简洁和专业的来回答用户的问题。不允许在答案中添加编造成分。已知内容:{context}问题:{question}"""prompt = PromptTemplate(input_variables=["context", "question"],template=PROMPT_TEMPLATE)my_prompt = prompt.format(context=related_docs,question=question)return my_promptdef qa():llm = ChatGLM2()llm.load_model(r'../../pretrain/model/chatglm2-6b-int4')my_prompt = define_prompt()result = llm(my_prompt)return resultif __name__ == '__main__':result = qa()print(f'result-->{result}')
get_vector.py
from langchain_community.document_loaders import UnstructuredFileLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.vectorstores import FAISS # 向量数据库 # from langchain.document_loaders import UnstructuredFileLoader # from langchain.text_splitter import RecursiveCharacterTextSplitter # from langchain.embeddings import HuggingFaceEmbeddings # from langchain.vectorstores import FAISS # 向量数据库def main():# 定义向量模型路径EMBEDDING_MODEL = './m3e-base'# 第一步:加载文档:loader = UnstructuredFileLoader('物流信息.txt')data = loader.load()# print(f'data-->{data}')# 第二步:切分文档:text_split = RecursiveCharacterTextSplitter(chunk_size=128,chunk_overlap=4)split_data = text_split.split_documents(data)# print(f'split_data-->{split_data}')# 第三步:初始化huggingface模型embeddingembeddings = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL)# 第四步:将切分后的文档进行向量化,并且存储下来db = FAISS.from_documents(split_data, embeddings)db.save_local('./faiss/camp')return split_dataif __name__ == '__main__':split_data = main()print(f'split_data-->{split_data}')
model.py
from langchain.llms.base import LLM from langchain.llms.utils import enforce_stop_tokens from transformers import AutoTokenizer, AutoModel from typing import List, Optional, Any# 自定义GLM类 class ChatGLM2(LLM):max_token: int = 4096temperature: float = 0.8top_p = 0.9tokenizer: object = Nonemodel: object = Nonehistory = []def __init__(self):super().__init__()@propertydef _llm_type(self) -> str:return "custom_chatglm2"# 定义load_model的方法def load_model(self, model_path=None):# 加载分词器self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)# 加载模型self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()# 定义_call方法:进行模型的推理def _call(self,prompt: str, stop: Optional[List[str]] = None) -> str:response, _ = self.model.chat(self.tokenizer,prompt,history=self.history,temperature=self.temperature,top_p=self.top_p)if stop is not None:response = enforce_stop_tokens(response, stop)self.history = self.history + [[None, response]]return responseif __name__ == '__main__':llm = ChatGLM2()llm.load_model(model_path=r'../../pretrain/model/chatglm2-6b-int4')print(f'llm--->{llm}')print(llm("1+1等于几?"))
物流信息.txt
物流公司:速达物流 公司总部:北京市 业务范围:国际快递、仓储管理货物追踪: - 货物编号:ABC123456 - 发货日期:2024-06-15 - 当前位置:上海分拨中心 - 预计到达日期:2024-06 -20运输方式: - 运输公司:快运通 - 运输方式:陆运 - 出发地:广州 - 目的地:重庆 - 预计运输时间:3天仓储信息: - 仓库名称:东方仓储中心 - 仓库位置:深圳市 - 存储货物类型:电子产品 - 存储条件:常温仓储 - 当前库存量:1000件