博主介绍选择放心、选择安心毕业✌就是:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就
> 想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。点击查看作者主页,了解更多项目!
通过感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都能够给我留言咨询,希望帮助同学们顺利毕业 。
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机大数据专业毕业设计选题大全(建议收藏)✅
1、项目介绍
该新闻数据爬取情感分析体系是一款融合爬虫技术与自然语言处理能力的智能新闻分析平台,基于Python语言构建,整合Django后端框架、Vue前端框架与Scrapy爬虫框架,核心技术涵盖jieba分词、朴素贝叶斯算法、TextRank算法及NLP情感分析技能,实现新闻数据的全流程智能化处理。
系统核心功能兼具实用性与智能性:通过Scrapy爬虫精准抓取新闻内容并直接存储至数据库,前端提供新闻列表展示、分类浏览、关键词搜索及详情查看等基础功能,满足用户高效获取信息的需求。同时,依托NLP与机器学习工艺,实现新闻摘要抽取、关键词分析、词性标注及情感分类等深度分析功能,其中TextRank算法快速提炼新闻核心概要,朴素贝叶斯算法支撑精准的新闻分类与情感倾向判断,帮助用户快速把握新闻重点与情感基调。
后台管理端支持新闻素材维护、用户注册登录及权限管控,确保系统稳定运行。平台界面直观清晰,涵盖数据分析可视化、词性分析展示等特色页面,既为普通用户提供高效的新闻获取与深度分析软件,也为管理者提供便捷的平台运营支持,高效解决了新闻信息筛选难、分析浅的痛点,达成了新闻数据从采集、处理到分析应用的全链路智能化升级。
技术栈:
Python语言、django框架、 vue框架、 scrapy爬虫框架、 jieba分词、 nlp算法、 爬虫抓取
机器学习、朴素贝叶斯算法、TextRank算法、情感分类、情感分析
功能:
新闻列表 新闻详情 新闻分类 新闻搜索
新闻摘要抽取 关键词分析 情感分析 朴素贝叶斯算法 词性分析
新闻资料爬虫、爬虫新闻数据直接存储到数据库
后台新闻数据管理、用户管理
一个基于Python语言和相关技术栈开发的系统。它主要包括以下功能:就是新闻数据爬取情感分析系统
- 新闻列表:展示新闻的标题、摘要和发布日期等信息。
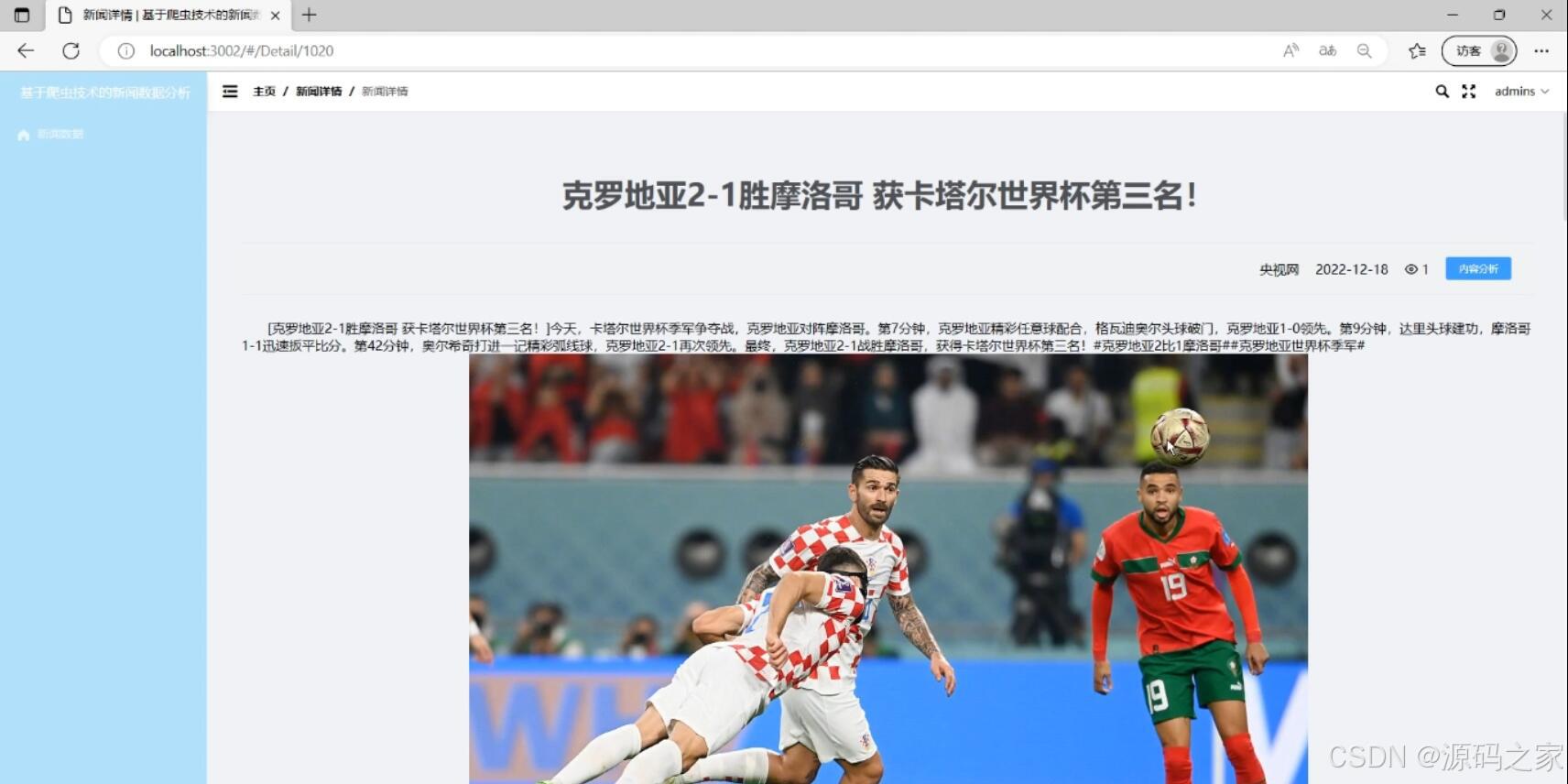
- 新闻详情:点击新闻标题可以查看新闻的详细内容。
- 新闻分类:对新闻进行分类,使用户能够按照不同主题浏览新闻。
- 新闻搜索:用户可以通过关键词搜索新闻,快速找到感兴趣的内容。
- 新闻摘要抽取:经过TextRank算法对新闻内容进行摘要抽取,提供用户快速了解新闻的概要。
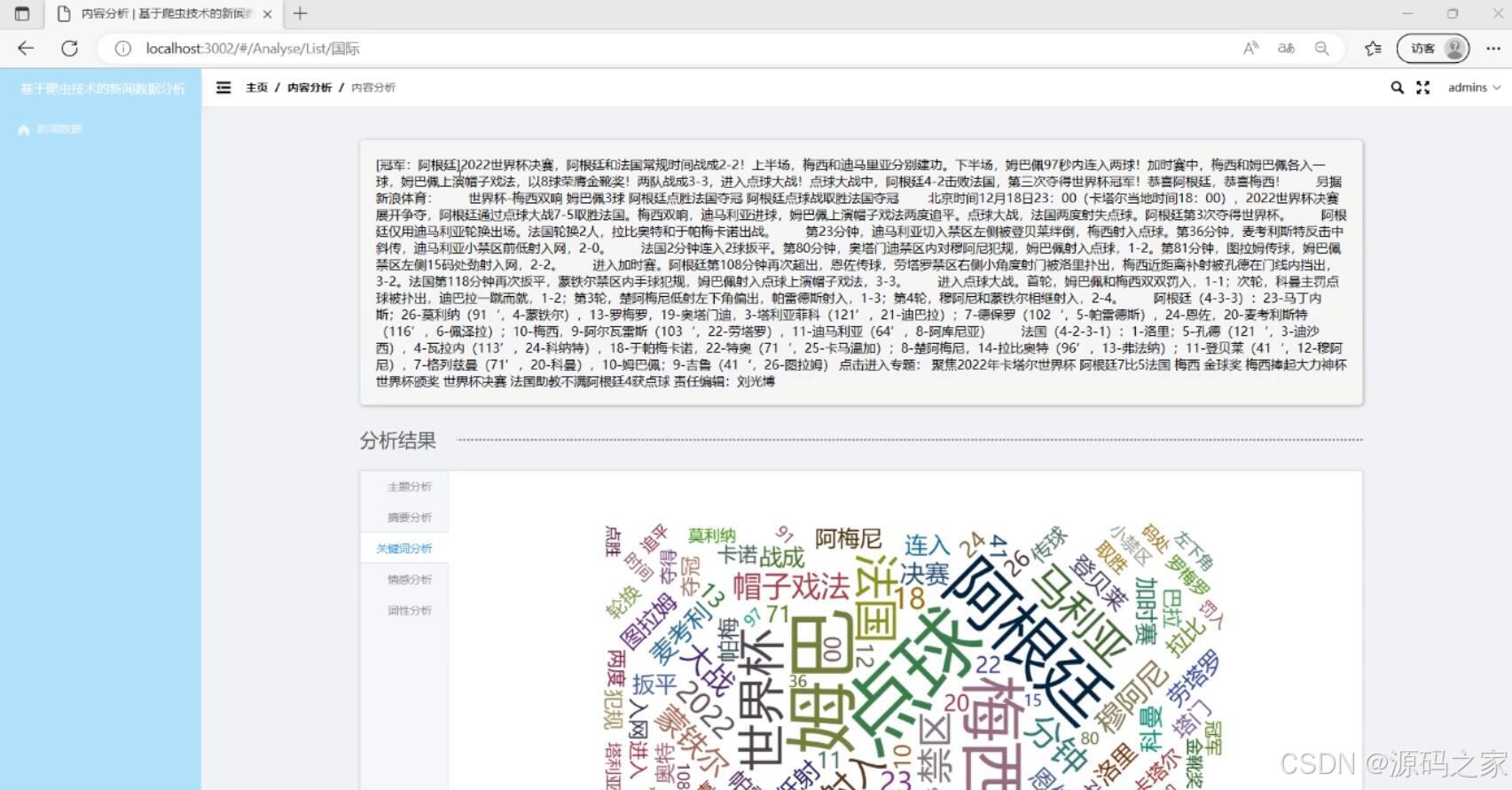
- 关键词分析:使用jieba分词应用对新闻内容进行分词,并提取关键词,帮助用户了解新闻的重点内容。
- 情感分析:使用nlp算法对新闻内容进行情感分析,判断新闻的情感倾向。
- 朴素贝叶斯算法:利用朴素贝叶斯算法进行新闻分类和情感分析。
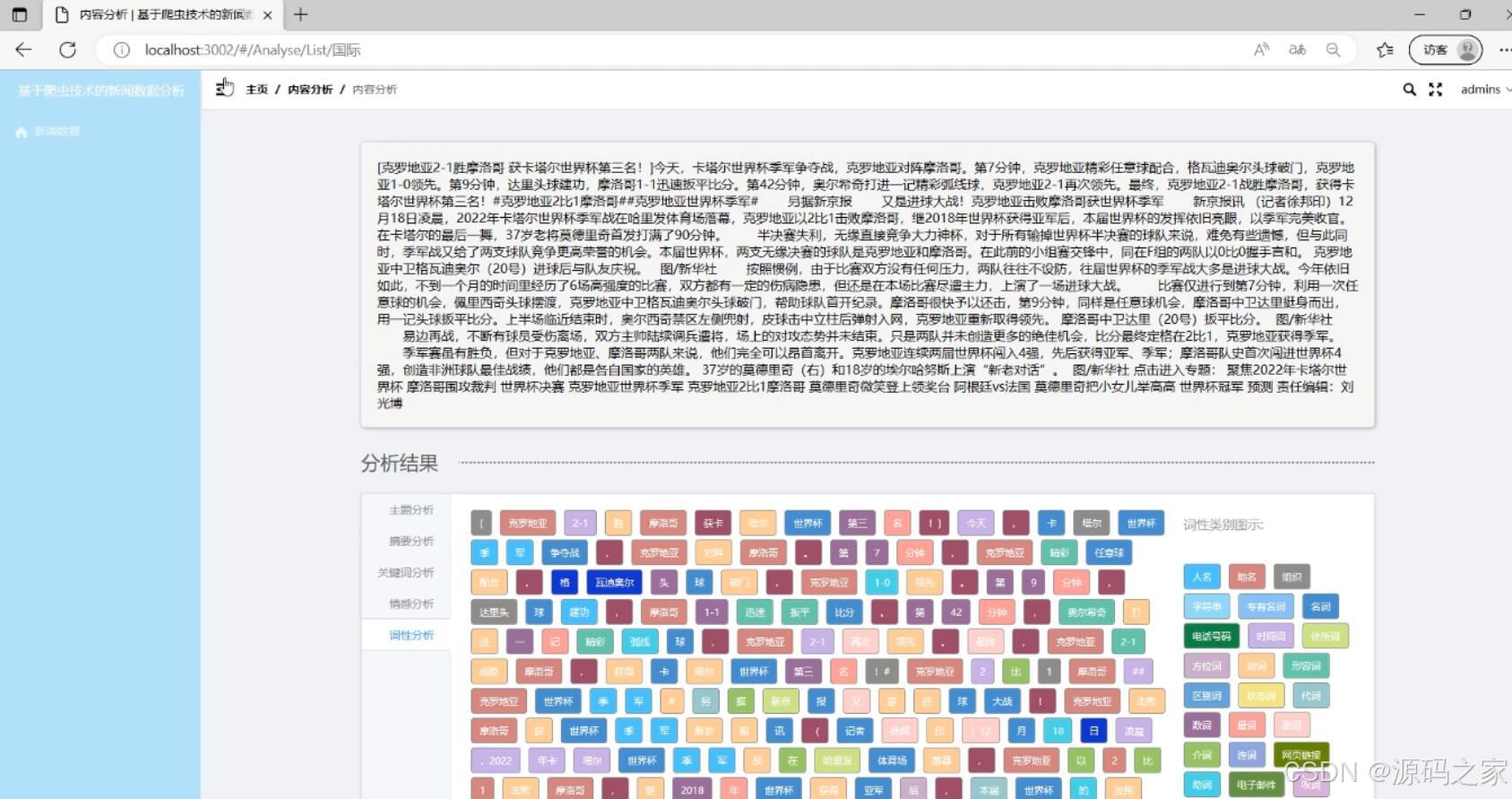
- 词性分析:对新闻内容进行词性标注,帮助用户了解词语的语法属性。
- 新闻数据爬虫:利用scrapy爬虫框架对新闻网站进行数据抓取,获取最新的新闻数据。
- 爬虫抓取:将爬虫抓取到的新闻数据直接存储到数据库中,方便后续分析和展示。
- 后台新闻数据管理:提供后台管理界面,方便管理员对新闻数据进行管理和维护。
- 用户管理:提供用户管理功能,包括用户注册、登录、权限管理等。
通过以上特性,新闻资料爬取情感分析系统行帮助用户快速浏览和搜索新闻,并提供关键词分析、情感分析等功能,帮助用户更好地理解和分析新闻内容。
2、项目界面
(1)新闻数据分析
(2)新闻详情页
(3)新闻资料浏览
(4)新闻词性分析
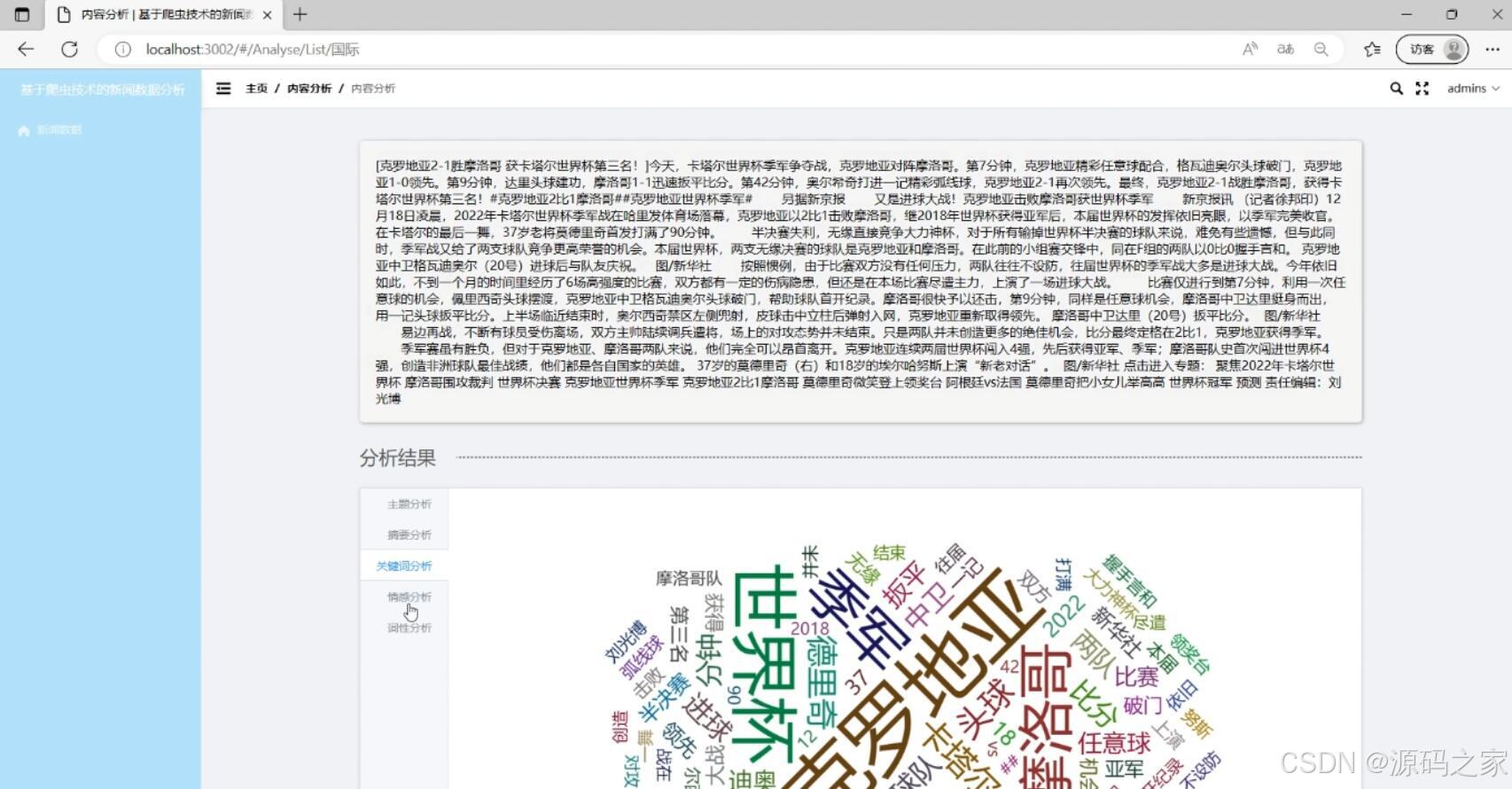
(5)后台管理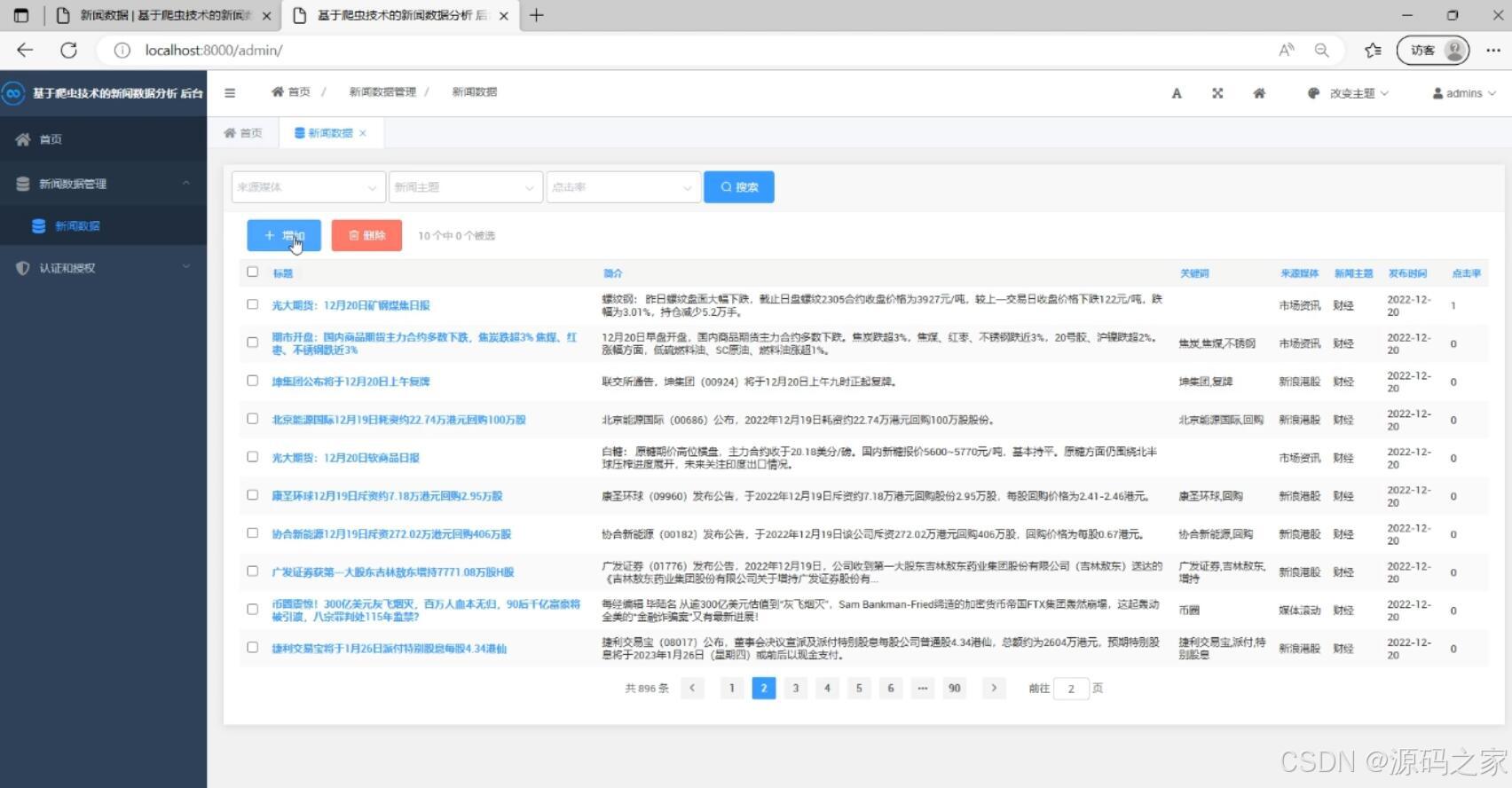
3、项目说明
技术栈:
Python语言、django框架、 vue框架、 scrapy爬虫框架、 jieba分词、 nlp算法、 爬虫抓取
机器学习、朴素贝叶斯算法、TextRank算法、情感分类、情感分析
该新闻数据爬取情感分析框架是一款融合爬虫技术与自然语言处理能力的智能新闻分析平台,基于Python语言构建,整合Django后端框架、Vue前端框架与Scrapy爬虫框架,核心技术涵盖jieba分词、朴素贝叶斯算法、TextRank算法及NLP情感分析手艺,实现新闻数据的全流程智能化处理。
系统核心功能兼具实用性与智能性:通过Scrapy爬虫精准抓取新闻素材并直接存储至数据库,前端给予新闻列表展示、分类浏览、关键词搜索及详情查看等基础机制,满足用户高效获取信息的需求。同时,依托NLP与机器学习技术,实现新闻摘要抽取、关键词分析、词性标注及情感分类等深度分析功能,其中TextRank算法快速提炼新闻核心概要,朴素贝叶斯算法支撑精准的新闻分类与情感倾向判断,帮助用户快捷把握新闻重点与情感基调。
后台管理端支持新闻素材维护、用户注册登录及权限管控,确保系统稳定运行。平台界面直观清晰,涵盖数据分析可视化、词性分析展示等特色页面,既为普通用户提供高效的新闻获取与深度分析工具,也为管理者提供便捷的环境运营支持,有效消除了新闻信息筛选难、分析浅的痛点,实现了新闻数据从采集、处理到分析应用的全链路智能化升级。
功能:
新闻列表 新闻详情 新闻分类 新闻搜索
新闻摘要抽取 关键词分析 情感分析 朴素贝叶斯算法 词性分析
新闻数据爬虫、爬虫新闻数据直接存储到数据库
后台新闻数据管理、用户管理
新闻数据爬取情感分析系统是一个基于Python语言和相关技术栈编写的系统。它主要包括以下功能:
- 新闻列表:展示新闻的标题、摘要和发布日期等信息。
- 新闻详情:点击新闻标题可以查看新闻的详细内容。
- 新闻分类:对新闻进行分类,使用户能够按照不同主题浏览新闻。
- 新闻搜索:用户可以通过关键词搜索新闻,快速找到感兴趣的内容。
- 新闻摘要抽取:通过TextRank算法对新闻内容进行摘要抽取,提供用户飞快了解新闻的概要。
- 关键词分析:启用jieba分词工具对新闻内容进行分词,并提取关键词,帮助用户了解新闻的重点内容。
- 情感分析:采用nlp算法对新闻内容进行情感分析,判断新闻的情感倾向。
- 朴素贝叶斯算法:利用朴素贝叶斯算法进行新闻分类和情感分析。
- 词性分析:对新闻内容进行词性标注,帮助用户了解词语的语法属性。
- 新闻素材爬虫:使用scrapy爬虫框架对新闻网站进行数据抓取,获取最新的新闻数据。
- 爬虫抓取:将爬虫抓取到的新闻内容直接存储到数据库中,方便后续分析和展示。
- 后台新闻数据管理:提供后台管理界面,方便管理员对新闻素材进行管理和维护。
- 用户管理:献出用户管理机制,包括用户注册、登录、权限管理等。
通过以上功能,新闻内容爬取情感分析系统可以帮助用户快速浏览和搜索新闻,并提供关键词分析、情感分析等机制,支援用户更好地理解和分析新闻内容。
4、核心代码
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
from ..sim.bm25 import BM25
class TextRank(object):
def __init__(self, docs):
self.docs = docs
self.bm25 = BM25(docs)
self.D = len(docs)
self.d = 0.85
self.weight = []
self.weight_sum = []
self.vertex = []
self.max_iter = 200
self.min_diff = 0.001
self.top = []
def solve(self):
for cnt, doc in enumerate(self.docs):
scores = self.bm25.simall(doc)
self.weight.append(scores)
self.weight_sum.append(sum(scores)-scores[cnt])
self.vertex.append(1.0)
for _ in range(self.max_iter):
m = []
max_diff = 0
for i in range(self.D):
m.append(1-self.d)
for j in range(self.D):
if j == i or self.weight_sum[j] == 0:
continue
m[-1] += (self.d*self.weight[j][i]
/ self.weight_sum[j]*self.vertex[j])
if abs(m[-1] - self.vertex[i]) > max_diff:
max_diff = abs(m[-1] - self.vertex[i])
self.vertex = m
if max_diff <= self.min_diff:
break
self.top = list(enumerate(self.vertex))
self.top = sorted(self.top, key=lambda x: x[1], reverse=True)
def top_index(self, limit):
return list(map(lambda x: x[0], self.top))[:limit]
def top(self, limit):
return list(map(lambda x: self.docs[x[0]], self.top))
class KeywordTextRank(object):
def __init__(self, docs):
self.docs = docs
self.words = {}
self.vertex = {}
self.d = 0.85
self.max_iter = 200
self.min_diff = 0.001
self.top = []
def solve(self):
for doc in self.docs:
que = []
for word in doc:
if word not in self.words:
self.words[word] = set()
self.vertex[word] = 1.0
que.append(word)
if len(que) > 5:
que.pop(0)
for w1 in que:
for w2 in que:
if w1 == w2:
continue
self.words[w1].add(w2)
self.words[w2].add(w1)
for _ in range(self.max_iter):
m = {}
max_diff = 0
tmp = filter(lambda x: len(self.words[x[0]]) > 0,
self.vertex.items())
tmp = sorted(tmp, key=lambda x: x[1] / len(self.words[x[0]]))
for k, v in tmp:
for j in self.words[k]:
if k == j:
continue
if j not in m:
m[j] = 1 - self.d
m[j] += (self.d / len(self.words[k]) * self.vertex[k])
for k in self.vertex:
if k in m and k in self.vertex:
if abs(m[k] - self.vertex[k]) > max_diff:
max_diff = abs(m[k] - self.vertex[k])
self.vertex = m
if max_diff <= self.min_diff:
break
self.top = list(self.vertex.items())
self.top = sorted(self.top, key=lambda x: x[1], reverse=True)
def top_index(self, limit):
return list(map(lambda x: x[0], self.top))[:limit]
def top(self, limit):
return list(map(lambda x: self.docs[x[0]], self.top))✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多任务可以查看主页,大家在毕设选题,项目编程以及论文编写等相关疑问都可以给我留言咨询,希望可以帮助同学们顺利毕业!✌
5、源码获取方式
由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。
点赞、收藏、关注,不迷路,下方查看获取联系方式
