# 前言
本文介绍了MogaNet中的通道聚合前馈网络(ChannelAggregationFFN)模块在YOLO26中的结合应用。ChannelAggregationFFN模块通过卷积、激活和特征分解操作,能有效减少通道信息冗余,提高信息利用率。我们将该模块集成到YOLO26的检测头部分,并在相关配置文件中进行设置。MogaNet在多个视觉基准测试中表现优异,将其ChannelAggregationFFN模块应用于YOLO26,有望提升目标检测的准确性和效率,验证了方法的有效性和应用潜力。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 介绍
- 摘要
- 文章链接
- 基本原理
- 1. 多阶门控聚合模块(Multi-Order Gated Aggregation)
- 2. 通道聚合模块(CA block)
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
在计算机视觉任务里,现代卷积网络借助尽可能全局地对内核进行语境化操作,展现出了极为可观的应用潜力。不过,深度神经网络(DNN)领域中多阶博弈论交互方面的最新研究进展,揭示了现代卷积网络存在表示瓶颈,具体表现为表达性交互未能通过增大内核尺寸而得到有效编码。为解决这一问题,我们提出了一个全新的现代卷积网络系列,名为 MogaNet,其用于在纯卷积网络模型中开展判别性视觉表示学习,具备良好的复杂度 - 性能权衡特性。MogaNet 将概念简洁却成效显著的卷积和门控聚合操作封装于一个紧凑模块内,能够高效地收集判别性特征并对其进行自适应语境化处理。相较于 ImageNet 以及包含 COCO 对象检测、ADE20K 语义分割、2D 和 3D 人体姿势估计与视频预测等多种下游视觉基准上的最先进的视觉Transformer(ViT)和卷积神经网络(ConvNet),MogaNet 呈现出卓越的可扩展性、令人惊叹的参数效率以及具备竞争力的性能。尤其值得关注的是,MogaNet 在 ImageNet - 1K 数据集上,以 5.2M 和 181M 个参数分别实现了 80.0% 和 87.8% 的准确率,性能优于 ParC - Net 和 ConvNeXt L,同时分别节省了 59% 的浮点运算次数(FLOP)和 17M 个参数。该网络的源代码可在 https://github.com/Westlake - AI/MogaNet 处获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
MogaNet是一种新型的卷积网络架构,旨在通过多阶门控聚合机制来增强视觉表示学习。以下是MogaNet的一些关键特性和创新点:
-
多阶卷积:MogaNet设计了三组并行的多阶深度卷积,这种结构使得网络能够在不同的交互尺度上学习信息,从而捕捉到更丰富的特征。这种设计旨在克服传统卷积网络在捕捉全局依赖性方面的局限性。
-
门控操作:MogaNet引入了双分支激活门控操作,允许网络在特征聚合时动态选择重要的特征。这种门控机制有助于网络在处理复杂的视觉任务时,自动调整对不同特征的关注程度。
-
通道聚合模块:为了确保网络能够学习到有意义的特征,MogaNet还提出了通道聚合模块。这一模块通过强化不同交互尺度的特征学习,进一步提升了网络的表现。
-
与ViT的比较:MogaNet在设计上借鉴了Vision Transformer(ViT)的优点,尤其是在全局信息处理方面。尽管ViT在图像分类任务中表现出色,但其通常需要大量的预训练数据。MogaNet通过结合卷积的局部性和ViT的全局性,提供了一种更高效的特征提取方式。
-
性能评估:MogaNet在多个基准测试上表现优异,包括ImageNet、COCO和ADE20K等数据集。与传统的卷积网络和ViT相比,MogaNet在准确性和效率上均有显著提升。
-
应用前景:MogaNet的设计理念和架构为未来的视觉任务提供了新的思路,尤其是在需要处理复杂场景和高维数据的应用中,如自动驾驶、医疗影像分析等。
在MogaNet架构中,多阶门控聚合模块(Multi-Order Gated Aggregation)和通道聚合模块(CA block)是两个关键的组成部分,它们共同提升了网络的特征学习能力和效率。以下是对这两个模块的详细介绍:
1. 多阶门控聚合模块(Multi-Order Gated Aggregation)
-
设计理念:多阶门控聚合模块旨在通过多层次的特征交互来增强网络的表达能力。该模块通过引入不同阶数的卷积操作,允许网络在多个尺度上捕捉特征,从而更好地理解图像中的复杂模式。
-
功能:该模块通过门控机制动态选择和聚合特征。具体来说,它会根据输入特征的上下文信息,决定哪些特征是重要的,哪些可以被忽略。这种自适应的特征选择过程有助于减少噪声,提高模型的鲁棒性。
-
实现方式:在实现上,多阶门控聚合模块通常包含多个并行的卷积层,每个层负责提取不同尺度的特征。通过对这些特征进行加权聚合,网络能够有效地整合来自不同层次的信息。
2. 通道聚合模块(CA block)
-
设计理念:通道聚合模块的主要目的是解决现有卷积网络中通道信息冗余的问题。许多传统方法在通道混合时使用线性投影,导致了参数的浪费和计算效率的低下。CA block通过重新分配通道特征,旨在提高信息的利用率。
-
功能:CA block通过对输入特征进行通道-wise的重新分配,增强了网络对重要特征的关注。它能够自适应地调整通道的权重,使得网络在处理高维特征时更加高效。
-
实现方式:CA block通常包括一个轻量级的卷积层和激活函数(如GELU),通过这些操作,网络能够在高维隐藏空间中重新分配通道特征。与传统的通道增强模块(如SE模块)相比,CA block在计算开销上更为高效。
核心代码
class ChannelAggregationFFN(nn.Module):"""An implementation of FFN with Channel Aggregation in MogaNet."""def __init__(self, embed_dims, mlp_hidden_dims, kernel_size=3, act_layer=nn.GELU, ffn_drop=0.):super(ChannelAggregationFFN, self).__init__()self.embed_dims = embed_dimsself.mlp_hidden_dims = mlp_hidden_dimsself.fc1 = nn.Conv2d(in_channels=embed_dims, out_channels=self.mlp_hidden_dims, kernel_size=1)self.dwconv = nn.Conv2d(in_channels=self.mlp_hidden_dims, out_channels=self.mlp_hidden_dims, kernel_size=kernel_size,padding=kernel_size // 2, bias=True, groups=self.mlp_hidden_dims)self.act = act_layer()self.fc2 = nn.Conv2d(in_channels=mlp_hidden_dims, out_channels=embed_dims, kernel_size=1)self.drop = nn.Dropout(ffn_drop)self.decompose = nn.Conv2d(in_channels=self.mlp_hidden_dims, out_channels=1, kernel_size=1)self.sigma = nn.Parameter(1e-5 * torch.ones((1, mlp_hidden_dims, 1, 1)), requires_grad=True)self.decompose_act = act_layer()def feat_decompose(self, x):x = x + self.sigma * (x - self.decompose_act(self.decompose(x)))return xdef forward(self, x):# proj 1x = self.fc1(x)x = self.dwconv(x)x = self.act(x)x = self.drop(x)# proj 2x = self.feat_decompose(x)x = self.fc2(x)x = self.drop(x)return x实验
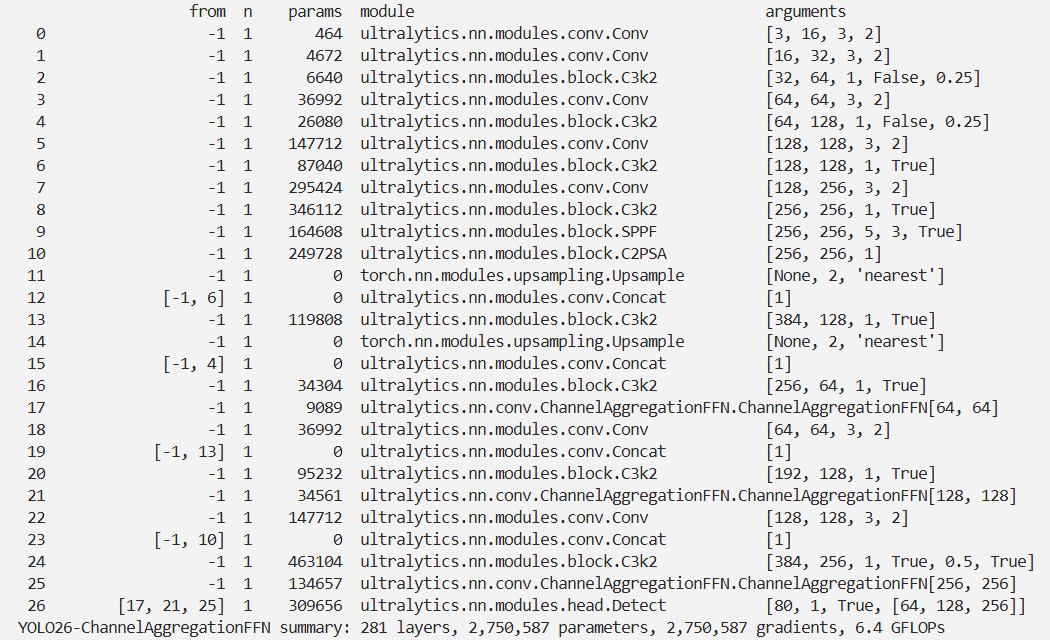
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-ChannelAggregationFFN.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD',amp=True,project='runs/train',name='yolo26-ChannelAggregationFFN',)结果