1.需求场景
在智能驾驶等复杂业务场景中,模型往往具备多任务分支结构,例如在同一个网络中同时包含 BEV 动态任务(如目标检测、跟踪、运动预测)与 BEV 静态任务(如地图构建、车道线提取、可行驶区域预测),这些任务对推理频率(Frames Per Second, FPS)的要求通常并不相同。也就是有不同任务分支 推理不同帧率的需求,例如 BEV 动态任务 20 帧,静态任务 10 帧这种情况,BEV 模型结构简单示例如下所示。
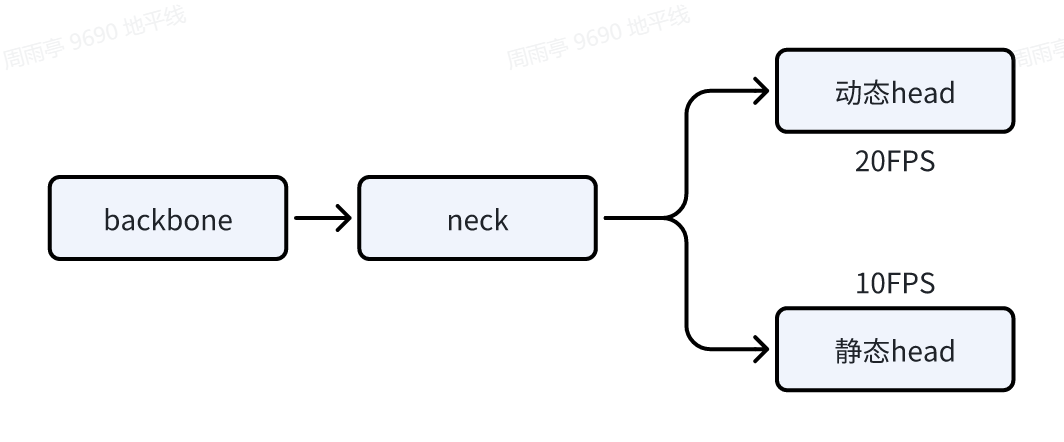
2.技术分析
以 BEV 动静态任务为例,实现不同任务分支推理不同帧率(动态 20 帧,静态 10 帧),很容易想到两种方案:
方案 1-拆分为三个子模型:模型 1-公共部分(backbone+neck)、模型 2-动态 head、模型 3-静态 head
- 模型 1 推理 20 次,输出分别送给模型 2 推理 20 次,模型 3 推理 10 次。
- 优点:应用层可灵活调度 3 个子模型的推理;模型 1-公共部分 只需要推理 20 次;
- 缺点:模型 1-公共部分的输出内存需要额外存储,增加 load/store 带宽消耗;拆分次数多,影响编译时的全图优化,可能会增加 latency;
方案 2-拆分为两个子模型:模型 1-公共动态(backbone+neck+ 动态 head)、模型 2-公共静态(backbone+neck+ 静态 head):
- 模型 1-公共动态推理 20 次,模型 2-公共静态推理 10 次。
- 优点:应用层可灵活调度 2 个子模型的推理;只需准备整个模型输入/出内存,无需准备公共部分输出的内存;拆分次数少,编译时可全图优化,减小 latency;
- 缺点:公共部分(backbone+neck)需要推理 30 次,造成 latency 增加与 BPU 资源浪费;公共部分需要存储两份;
为了兼顾方案 1 与方案 2 的优点,同时实现不同任务分支推理不同帧率,工具链提供了 link 打包功能,具体打包方式如下:
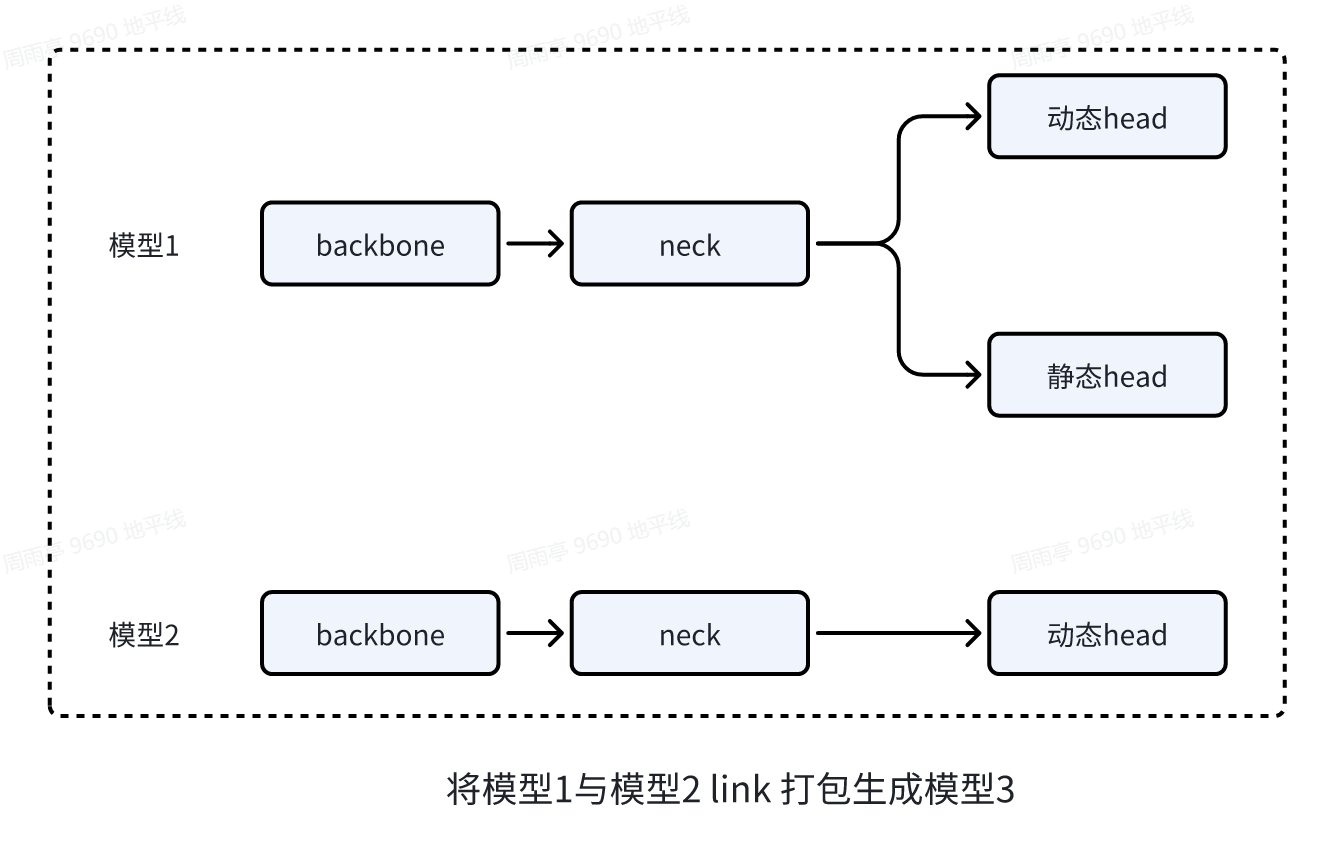
工具链提供的 link 功能,能够 复用 不同 模型/任务 的公共部分 constant 常量(包括权重等),即不会存储多份,在模型加载时,公共部分只会占用一份静态内存,需要注意推理时动态内存不会复用(作为不同模型处理),关于内存占用相关介绍可见文章《【地平线 J6 工具链入门教程】板端部署 UCP 使用指南-内存占用》。
上图中将模型 1 与模型 2 link 打包生成的模型 3,相比于模型 1 体积不会大多少,同时具备推理模型 1 与模型 2 的功能。根据需求,调整模型 1 与模型 2 的推理次数,即可实现不同任务采用不同帧率部署。
如下图所示:推理一次模型 1,可实现动态任务 head 与静态任务 head 各推理一次,推理模型 2 可实现仅推理一次动态任务 head,当模型 1 推理 10 次、模型 2 推理 10 次时,即可实现动态推理 20 次,静态推理 10 次的效果。(公共部分 backbone+neck 仅推理 20 次)
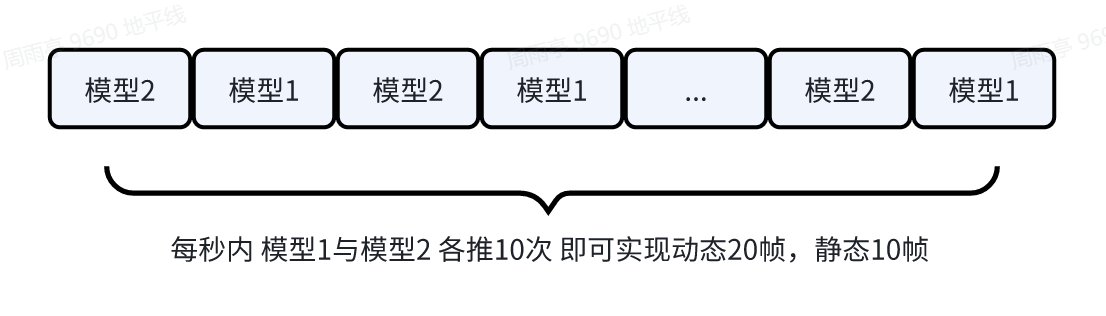
3.方案实现
3.1 模型 link 打包
根据需求场景,先将多任务模型拆分导出为不同子任务的 qat.bc,然后分别将他们编译成 hbo 文件,最后将多个 hbo 文件 link 打包为一个 hbm 模型。
在工具链用户手册《HBDK Tool API Reference》章节中详细介绍了 compile 与 link API,可以看到:
- compile 输出同时支持 hbm 与 hbo 两种文件格式,可通过配置文件后缀名为"。hbm" or ".hbo"来区分。
- link 支持将多个 hbo 文件打包生成一个 hbm 文件。
将两个 hbo 文件通过 link 打包生成一个 hbm 模型,示例代码如下:
from horizon_plugin_pytorch.quantization.hbdk4 import export
from hbdk4.compiler import load, convert, compile, link
# export 阶段记得配置 name
qat_bcA = export(qat_model_A, example_input, name="1_backbone_head1_head2")
quantized_modelA = convert(qat_bcA, "nash-m")
# 注意:此时compile生成的模型后缀名为.hbo
hbo_nameA = "nameA_compiled.hbo"
hboA = compile(quantized_modelA, path=hbo_nameA, march="nash-m", opt=2, progress_bar=True, jobs=48)qat_bcB = export(qat_model_B, example_input, name="2_backbone_head1")
quantized_modelB = convert(qat_bcB, "nash-m")
hbo_nameB = "nameB_compiled.hbo"
hboB = compile(quantized_modelB, path=hbo_nameB, march="nash-m", opt=2, progress_bar=True, jobs=48)# link生成打包模型,后缀名为.hbm
hbm_name = "compiled.hbm"
hbm = link([hboA, hboB], hbm_name)
# 如果在其他地方已经生成了hbo
# 可以通过 hbo = Hbo(hbo_name) 进行加载 所需头文件: from hbdk4.compiler.hbm import Hbo
3.2 打包模型推理
3.2.1 hrt_model_exec 工具推理
通过 hrt_model_exec model_info --model_file compiled.hbm 可查看打包模型的数量,输入输出等信息,示例如下
This model file has 2 model:
[2_backbone_head1] [1_backbone_head1_head2]
---------------------------------------------------------------------
[model name]: 2_backbone_head1input[0]:
name: ...output[0]:
name: ...------------------------------------------------------------------------------------------------------------------------------------------
[model name]: 1_backbone_head1_head2input[0]:
name: ...output[0]:
name: ...output[1]:
name: ...
结合--model_file 与--model_name 即可实现对打包 compiled.hbm 模型中的某一个模型进行推理。
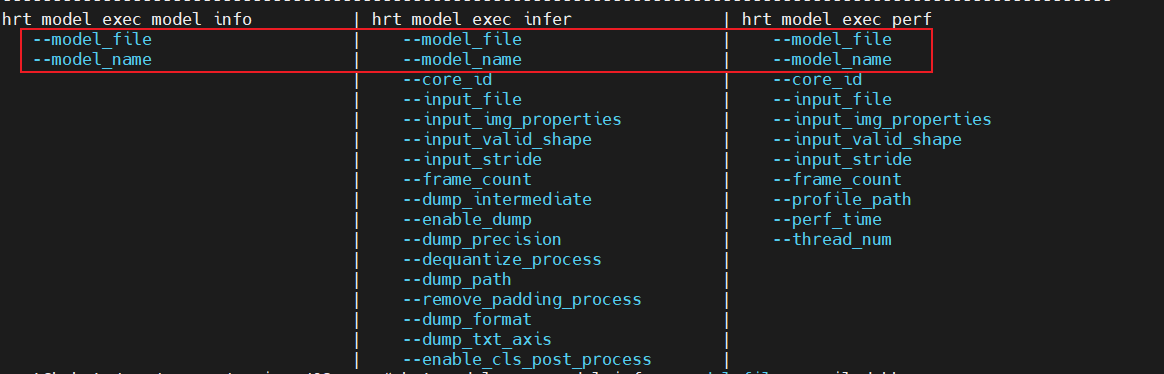
以 perf 评测打包 compiled.hbm 模型 中 2_backbone_head1 的性能为例,参考命令如下:
hrt_model_exec perf --model_file compiled.hbm --model_name 2_backbone_head1
3.2.2 UCP API 推理
在工具链用户手册《统一计算平台 UCP - 模型推理开发 - 模型推理 API 手册 - 功能接口》中,详细介绍了加载打包模型 hbDNNInitializeFromFiles 与 获取单个模型句柄 hbDNNGetModelHandle 的使用方式,截图如下:
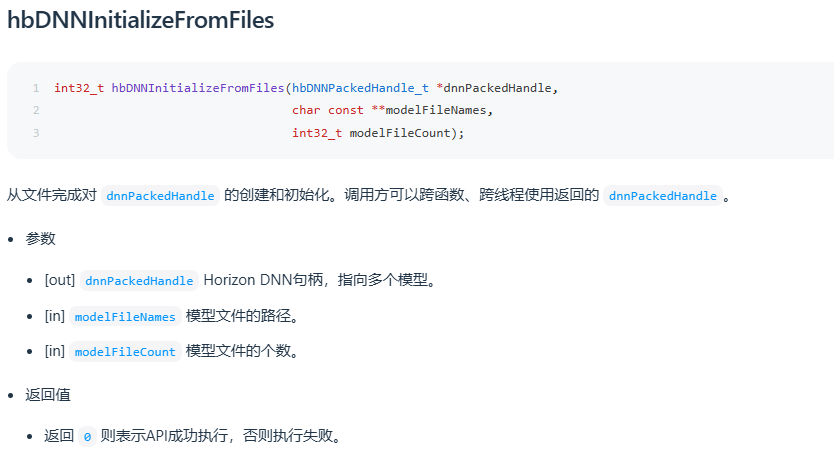
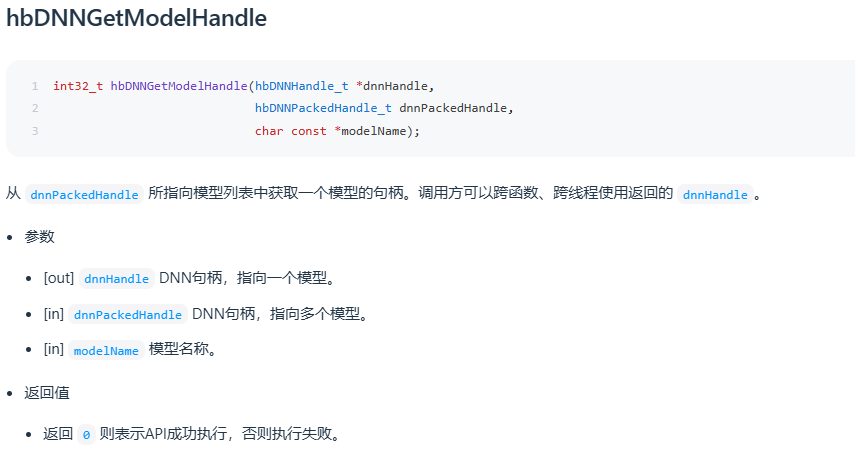
在工具链开发包路径:OE/samples/ucp_tutorial/dnn/basic_samples 下方的示例中有用到这两个接口,可参考使用。
3.3 多任务不同帧率推理
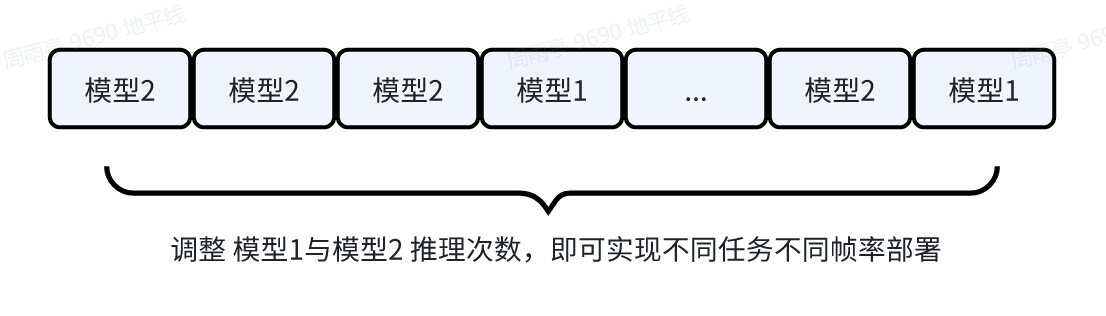
根据需求,调整打包模型 compiled.hbm 中的 模型 1 backbone_head1_head2 与模型 2 backbone_head1 的推理次数,即可实现不同任务采用不同帧率部署。
3.4 性能数据示例
下表中,backbone_head1 是公共部分,注意:公共部分权重是一样的
| 模型名称 | 模型大小/KB | 模型 name | latency/ms |
|---|---|---|---|
| 1_backbone_head1_head2.hbm | 30295 | / | 5.19 |
| 2_backbone_head1.hbm | 21781 | / | 4.84 |
| compiled.hbm | 30776 | 1_backbone_head1_head2 | 5.18 |
| 2_backbone_head1 | 4.83 |
可以看到,compiled.hbm 体积相比于 1_backbone_head1_head2.hbm 并没有增加多少。
模型加载推理时,ION 内存差异如下:
加载 1_backbone_head1_head2.hbm,直接推理:
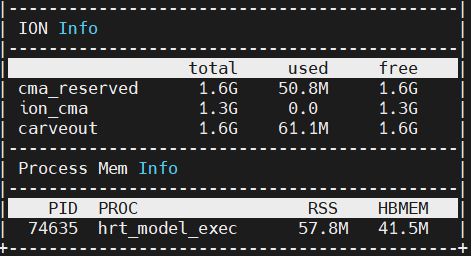
加载 compiled.hbm,推理 1_backbone_head1_head2:
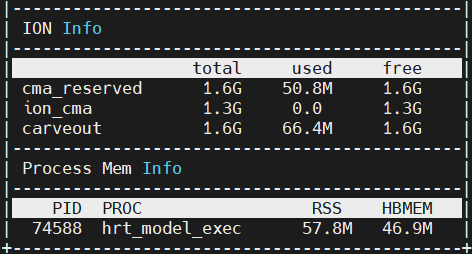
可以看到,compiled.hbm 占用的内存相比于 1_backbone_head1_head2.hbm 并没有增加多少。