概要:移动平均是一种常用的平滑处理技术,常用与深度学习/深度强化学习的loss或者reward曲线的绘制,其核心思想是当前的点和历史的点之间的加权平均
QA-before
Q: 为什么要加权平均?
A: - 消除噪声 - 识别趋势 - 训练稳定性评估
常见的移动平均方法
在深度学习中常用的移动平均算法包括:简单移动平均算法、指数移动平均算法、高斯滤波
A. 简单移动平均
简单移动平均(Simple moving averge)的思想很简单: 取过去 n 个点的算数平均值,即
我们一般将这里的 n 成为窗口,当然可以发现这里会出现初始点的处理问题,也就是当数据还不满n个的时候,怎么移动平均,一般采用的方法也很容易想到,有多少个点就算多少个的平均,满足了之后再按照公式来,即只有一个点的时候按一个点平均,两个点按两个点平均...,以此类推,这种方法叫做最小值观测法,这也是Pandas 和 OpenAI 工具库的做法。当然还有还有一些丢弃和补充的方法,思想都很简单,这里不做说明。
B. 指数移动平均
指数平均方法核心就是一个递推公式,即
- \(S_t\) : 当前时刻的平滑值
- \(\alpha\) : 平滑系数
- \(x_t\) : 当前时刻的loss, 即原始的数值
类似于markov性质,当前值只与上一个时刻的 \(S_{t-1}\) 相关。
我们将这个式子展开可以看到:
可以看出历史数值对当前数值的影响以 \((1-\alpha)^n\) 的速率衰减。
C. 高斯滤波
在 A 和 B 中介绍的移动平均方法都属于“向前看”的方法,也就是只使用之前的历史值,而高斯滤波采用的是 "中心化加权" 的方法,其一维的概率密度形式为:
- \(x\) : 与中心点的距离
- \(\sigma\) : 标准差,\(\sigma\) 越大越平滑,给予两端数值的权重也就越多
也就是正态分布的曲线,这里的加权平均可以理解为积分
也可以写为离散加权求和的形式。
D. 对比与理解
在实际运用中,三者各有优缺点,在一般的深度强化学习论文中,通常采用SMA方法才绘制最终的奖励曲线,并在图片的批注中标出移动窗口大小,在Tensorboard中实时展示算法更新等场景则习惯于采用EMA方法,而在某些情况下想要看到更为平滑美观的曲线则使用高斯滤波。下面是对比的表格:
| 方法 | SMA | EMA | 高斯滤波 |
|---|---|---|---|
| 直观理解 | 移动的平均窗口 | 类markov的历史加权 | 移动中心钟形加权窗口 |
| 优点 | 简单,易实现 | 内存占用低的情况下对历史数据进行了考虑,数值稳定 | 两端考虑,滤除噪声效果好 |
| 缺点 | 滞后性,整体像右移动,需要保存历史数据 | \(\alpha\) 参数敏感,异常值敏感 | 计算量大,无法实时更新,边缘点处理 |
| 平滑质量 | 容易产生阶梯感或假峰 | 较圆滑,但对最新波动敏感 | 曲线最圆润自然 |
| 主要场景 | 一般的汇报,深度强化学习loss曲线 | 算法的监控和更新 | 精修 |
代码实现与效果对比
A. SMA
def sma_smooth_curve(data: np.ndarray, windows_size: int) -> np.ndarray:smoothed = []for i in range(len(data)):smooth_c = 0if i < windows - 1:windows = data[0:i+1]else:windows = data[(i - windows_size + 1) : i + 1]sma_windows = np.sum(windows) / len(windows)smoothed.append(sma_windows)return np.array(smoothed)
B. EMA
def ema_smooth_curve(data: np.ndarray, weight:float = 0.9):last = data[0]smoothed = []for point in data:smoothed_val = last * weight + point * (1 - weight)smoothed.append(smoothed_val)last = smoothed_valreturn np.array(smoothed, dtype=np.float32)
C. 高斯滤波
高斯滤波算法这里直接采用 scipy 库的gaussian_filter函数实现
def gaussian_smooth_scipy(data: np.ndarray, sigma:int = 2):return gaussian_filter(data, sigma=sigma)
当然,也可是自己手动实现,实现一个卷积即可
def create_gaussian_kernel(sigma):"""根据 sigma 自动计算高斯核的大小和权重"""radius = int(3 * sigma)x = np.arange(-radius, radius + 1)kernel = np.exp(-x**2 / (2 * sigma**2))return kernel / kernel.sum()def gaussian_smooth_manual(data, sigma=2):"""手动实现高斯卷积"""kernel = create_gaussian_kernel(sigma)padded_data = np.pad(data, len(kernel)//2, mode='edge')smoothed = np.convolve(padded_data, kernel, mode='valid')return smoothedD. 滤波效果对比
数据采用随机生成,并加上一定的正态分布噪声
def main():np.random.seed(42)x = np.linspace(0, 100, 300)true_trend = 20 * (1 - np.exp(-x / 30)) # 理想的回报曲线noise = np.random.normal(0, 3, size=x.shape) # 训练中的随机波动raw_scores = true_trend + noisesma = sma_smooth_curve(raw_scores, windows_size=20)ema = ema_smooth_curve(raw_scores, weight=0.8)gaussia = gaussian_smooth_scipy(raw_scores, sigma=5)plt.figure(figsize=(10, 6))plt.plot(x , raw_scores, color='blue', alpha=0.2, label='Raw Scores')plt.plot(x , sma, color='blue', linewidth=2, label='Smoothed (SMA)')plt.plot(x , ema, color='orange', linewidth=2, label='Smoothed (EMA)')plt.plot(x , gaussia, color='green', linewidth=2, label='Smoothed (Gaussian)')plt.title('Training Scores with Smoothing', fontsize=14)plt.xlabel('Steps / Epochs')plt.ylabel('Score Value')plt.legend()plt.grid(True, linestyle='--', alpha=0.6)plt.show()
对比结果图如下:
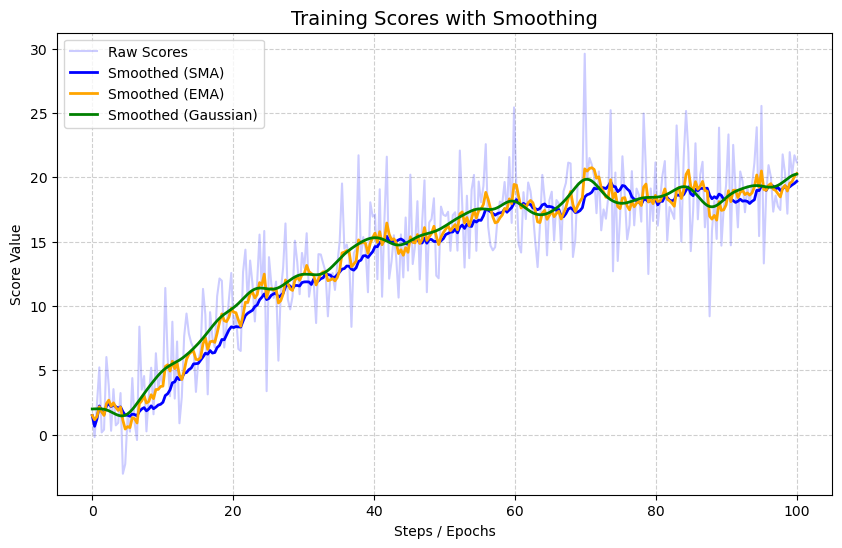
可以看到Gaussian滤波的方法得到的绿色曲线是较为平滑的,将 \(\sigma\) 参数调大之后将会更加平滑。而EMA则对 \(\alpha\) 参数敏感,SMA得到的曲线也有平滑的效果,但是其会出现阶梯状的现象,当然这里的噪声加的比较小,对比不是很明显,感兴趣的也可以自己调调参数试试。