机器学习-白板推导系列(十四)-隐马尔可夫模型HMM(Hidden Markov Model)笔记
隐马尔科夫模型-胡浩基
马尔可夫链
【数之道 18】"马尔可夫链"是什么?了解它只需5分钟!_哔哩哔哩_bilibili
- 状态空间 States Space
- 无记忆性 Memorylessness
- 当期选择的概率只受上期状态的影响
- \(P(S_t|S_{t-1},S_{t-2},S_{t-3},......)=P(S_t|S_{t-1})\)
- 转移矩阵 Transition Matrix
转移矩阵如下:
\[\begin{align}
\begin{bmatrix}
0.2 & 0.1 & 0.5\\
0.5 & 0.7 & 0.4\\
0.3 & 0.2 & 0.1
\end{bmatrix}
\end{align}
\]
隐马尔可夫模型相关内容
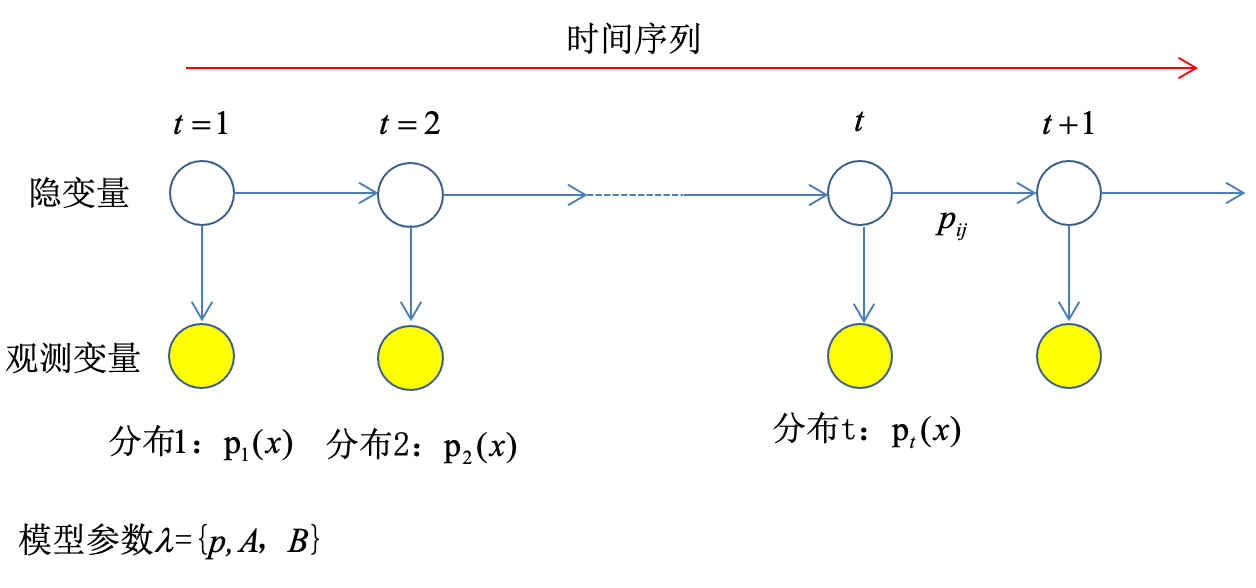
一个模型
\[\lambda=(\pi,A,B)
\]
- \(\pi\):初始时刻的概率分布
- A:状态转移矩阵,\(A=[a_{ij}],a_{ij}=p(i_{y+1}=1_j|i_t=q_i)\)
- B:发射矩阵,\(B=[b_j(k)],b_j(k)=p(o_t=v_k|i_t=q_j)\)
- 图中橙色变量是观测变量,表示为:\(O=o_1,o_2\dots,o_t,\dots\),其状态空间为:\(V={v_1,v_2,\dots,v_M}\)
- 图中空心变量是状态变量,表示为:\(I=i_1,i_2,\dots,i_t,\dots\),其状态空间为:\(Q={q_1,q_2,\dots,q_N}\)
二个假设
- 齐次Markov假设:当前假设只与前一状态有关。\(P(i_{t+1}|i_t,i_{t-1},\dots,i_1,o_t,o_{i-1},\dots,o_1)=P(i_{t+1}|i_t)\)
- 观测独立假设:当前的观测变量至于当前的状态变量有关。\(P(o_t|i_t,i_{t-1},\dots,i_1,o_{t-1},\dots,o_1)=P(o_t|i_t)\)
三个问题
- Evaluation:在知道所有参数\(\lambda\)的条件下,观测序列的概率,即\(P(O|\lambda)\),通常采用前向后向算法解决。
- Learning:如何求\(\lambda\),即\(\lambda=argmax P(O|\lambda)\),通常采用EM算法。
- Decoding:找到一个状态序列\(I\),使得\(P(I|\lambda)\)最大,即\(I=argmax P(I|O)\)
- 预测问题:\(P(i_{t+1}|o_1,o_2,\dots,o_t)\)求\(t+1\)时刻的隐状态
- 滤波问题:\(P(i_t|o_1,o_2,\dots,o_t)\)求\(t\)时刻的隐状态
Evaluation问题
\[P(O|\lambda)=\sum_IP(I,O|\lambda)=\sum_IP(O|I,\lambda)\cdot P(I|\lambda)
\]
分别计算\(P(I|\lambda)\)和\(P(O|I,\lambda)\)。
\[\begin{align*}
P(I|\lambda)&=P(i_1,i_2,\cdots,i_T|\lambda)\\
&=P(i_T|i_1,i_2,\cdots,i_{T-1},\lambda)\cdot P(i_1,i_2,\cdots,i_{T-1}|\lambda)\\
&=P(i_T|i_{T-1},\lambda)\cdot P(i_1,i_2,\cdots,i_{T-1}|\lambda)\text{(齐次Markov假设)}\\
&=\pi(a_{i_1})\prod_{t=2}^Ta_{i_{t-1},i_t}\\
P(O|I,\lambda)&=P(o_T,o_{T-1},\cdots,o_1|i_T,i_{T-1},\cdots,i_1,\lambda)\\
&=P(o_T|o_{T-1},\cdots,o_1,i_T,i_{T-1},\cdots,i_1,\lambda)\cdot P(o_{T-1},\cdots,o_1|i_T,i_{T-1},\cdots,i_1,\lambda)\\
&=P(o_T|o_{T-1})\cdot P(o_{T-1},\cdots,o_1|i_T,i_{T-1},\cdots,i_1,\lambda)\text{(观测独立假设)}\\
&=\prod_{t=1}^T b_{i_t}(o_t)
\end{align*}
\]
将上面两个式子带入\(P(O|\lambda)\)得到:
\[P(O|\lambda)=\sum_I\pi(a_{i_1})\prod_{t=2}^Ta_{i_{t-1},i_t}\prod_{t=1}^T b_{i_t}(o_t)
\]
这种计算方法的时间复杂度是\(O(N^T)\)太大,现实难以实现。后面介绍的前向算法和后向算法的复杂度为\(O(TN^2)\)。
前向算法
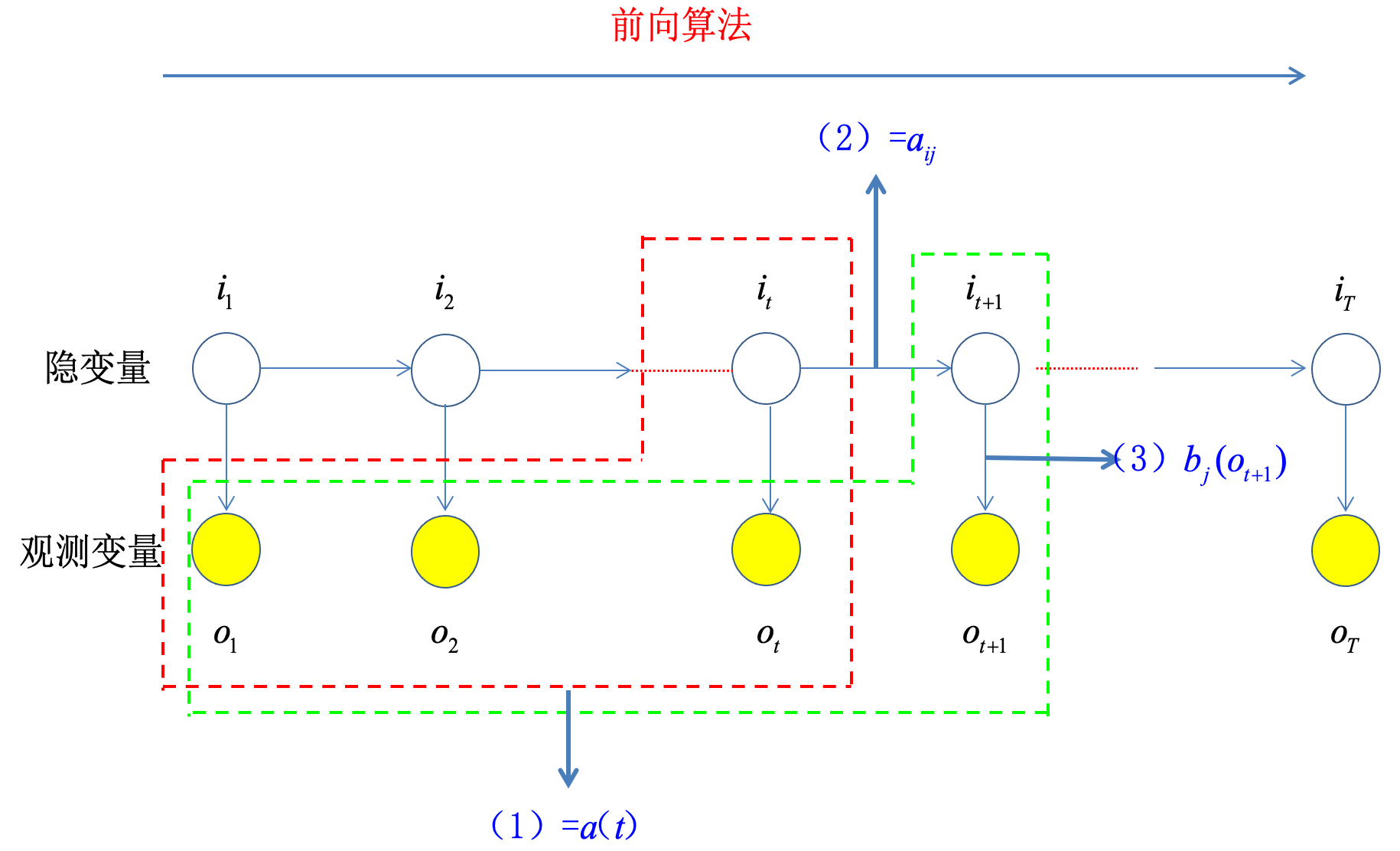
定义:\(\alpha_t(i)=P(o_1,\cdots,o_t,i_t=q_i|\lambda)\)。
则可得:\(P(O|\lambda)=\sum_{i=1}^NP(O,i_T=q_i|\lambda)=\sum_{i=1}^N\alpha_T(i)\)
\[\begin{aligned}
\alpha_{t+1}(j)&=P(o_1,\cdots,o_{t+1},i_{t+1}=q_j|\lambda)\\&=\sum_{i=1}^NP(o_1,\cdots,o_t,o_{t+1},i_{t+1}=q_j,i_t=q_i|\lambda)\\&=\sum_{i=1}^NP(o_{t+1}|o_1,\cdots,o_t,i_t=q_i,i_{t+1}=q_j,\lambda)\cdot P(o_1,\cdots,o_t,i_t=q_i,i_{t+1}=q_j|\lambda)\\&=\sum_{i=1}^NP(o_{t+1}|i_{t+1}=q_j,\lambda)\cdot P(o_1,\cdots,o_t,i_t=q_i,i_{t+1}=q_j|\lambda)\\&=\sum_{i=1}^NP(o_{t+1}|i_{t+1}=q_j,\lambda)\cdot P(i_{t+1}=q_j|o_1,\cdots,o_t,i_t=q_i,\lambda)\cdot P(o_1,\cdots,o_t,i_t=q_i|\lambda)\\&=\sum_{i=1}^NP(o_{t+1}|i_{t+1}=q_j,\lambda)\cdot P(i_{t+1}=q_j|i_t=q_i,\lambda)\cdot\alpha_t(i)\\
&=\sum_{i=1}^Nb_j(O_{t+1})\cdot a_{ij}\cdot\alpha_t(i)
\end{aligned}
\]
通过这个递推式可以快速计算出\(P(O|\lambda)\)
后向算法
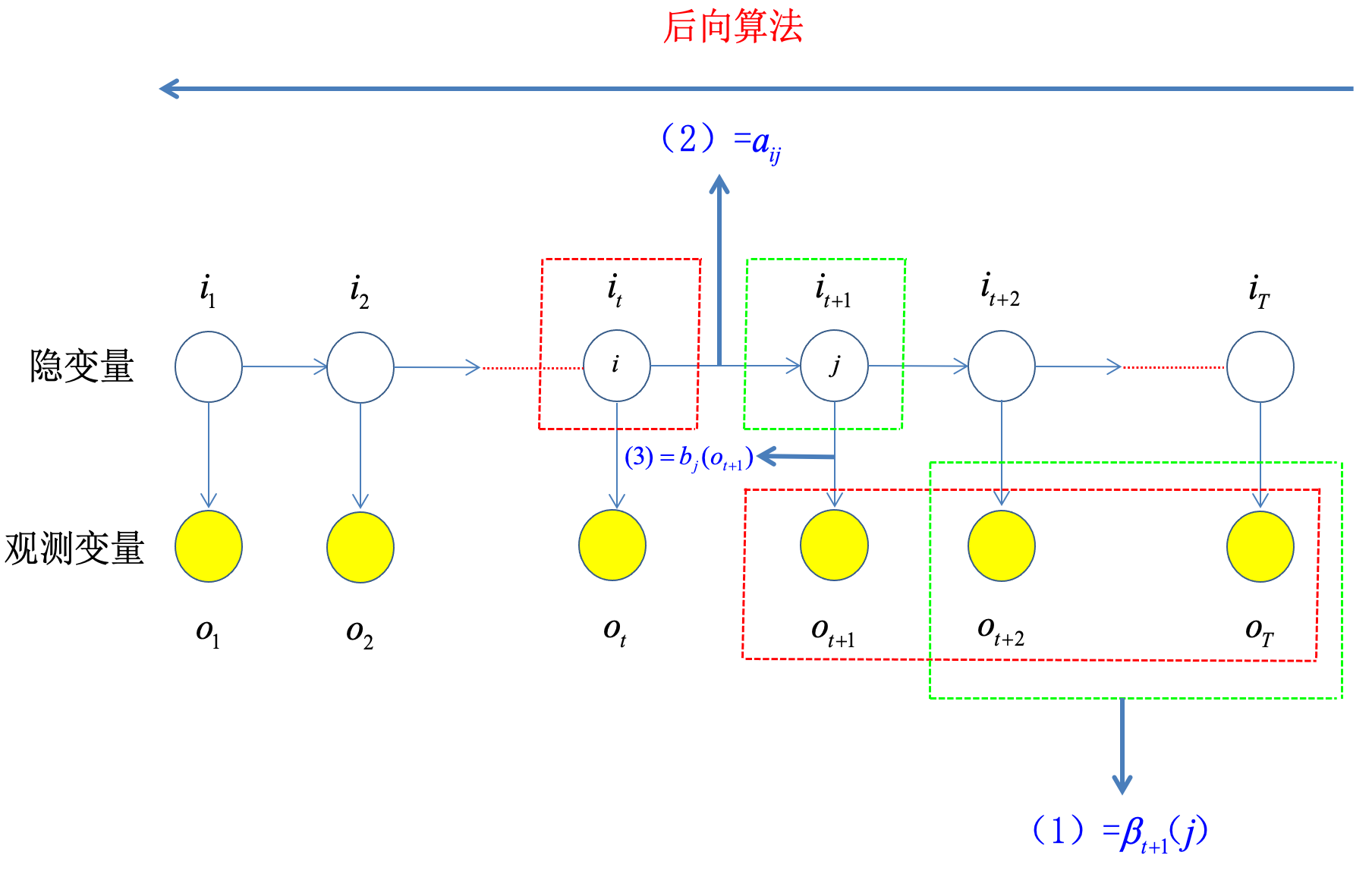
定义:\(\beta_t(i)=P(o_{t+1},\cdots,o_T|i_t=q_i,\lambda)\)
\[\begin{aligned}P(O|\lambda)&=P(o_1,\cdots,o_T|\lambda)\\&=\sum_{i=1}^NP(o_1,\cdots,o_T,i_1=q_i|\lambda)\\&=\sum_{i=1}^NP(o_1,\cdots,o_T|i_1=q_i,\lambda)\cdot P(i_1=q_i|\lambda)\\&=\sum_{i=1}^NP(o_1|o_2,\cdots,o_T,i_1=q_i,\lambda)\cdot P(o_2,\cdots,o_T|i_1=q_i,\lambda)\cdot P(i_1=q_i|\lambda)\\&=\sum_{i=1}^NP(o_1|i_1=q_i,\lambda)\cdot\beta_1(i)\cdot\pi_i\\&=\sum_{i=1}^Nb_i(o_1)\cdot\beta_1(i)\cdot\pi_i\end{aligned}
\]
\[\begin{aligned}
\beta_{t}(i)&=P(o_{t+1},\cdots,o_T|i_t=q_i,\lambda)\\
&=\sum_{j=1}^NP(o_{t+1},\cdots,o_T,i_{t+1}=q_j|i_t=q_i,\lambda)\\
&=\sum_{j=1}^NP(o_{t+1},\cdots,o_T|i_{t+1}=q_j,i_t=q_i,\lambda)\cdot P(i_{t+1}=q_j|i_t=q_i,\lambda)\\
&=\sum_{j=1}^NP(o_{t+1},\cdots,o_T|i_{t+1}=q_j,\lambda)\cdot a_{ij}\text{(根据head-tail的公式)}\\
&=\sum_{j=1}^NP(o_{t+1}|o_{t+2},\cdots,o_T,i_{t+1}=q_j,\lambda)\cdot P(o_{t+2},\cdots,o_T|i_{t+1}=q_j,\lambda)\cdot a_{ij}\\
&=\sum_{j=1}^NP(o_{t+1}|i_{t+1}=q_j,\lambda)\cdot\beta_{t+1}(j)\cdot a_{ij}\\
&=\sum_{j=1}^Nb_j(o_{t+1})\cdot\beta_{t+1}(j)\cdot a_{ij}
\end{aligned}
\]
Learning问题
Learning问题的本质:求解\(\lambda_{MLE}=argmax\mathrm{~P}(O|\lambda)\)
EM算法用在HMM算法的递推式如下。其中因为\(P(O,\lambda^{(t)})\)是常数,对\(\lambda\)的取值无影响进而消掉。
\[\begin{align*}
\lambda^{(t+1)}&=arg \max_{\lambda}\sum_I\log P(O,I|\lambda)\cdot P(I|O,\lambda^{(t)})\\
&=arg \max_{\lambda}\sum_I\log P(O,I|\lambda)\cdot \frac{
P(I,O|\lambda^{(t)})}{P(O,\lambda^{(t)})}\\
&=arg \max_{\lambda}\sum_I\log P(O,I|\lambda)\cdot P(I,O|\lambda^{(t)})
\end{align*}
\]
定义:\(Q(\lambda,\lambda^{(t)})=\sum_I\log P(O,I|\lambda)\cdot P(O,I|\lambda^{(t)})\)
将前向算法得到的\(P(O,I|\lambda)\)以\(\lambda^{(t)}\)带入\(Q(\lambda,\lambda^{(t)})\)得到:
\[Q(\lambda,\lambda^{(t)})=\sum_I[(\log\pi_{i_1}+\sum_{t=2}^T\log a_{i_{t-1},i_t}+\sum_{t=1}^T\log b_{i_t}(o_t))\cdot P(O,I|\lambda^{(t)})]
\]
这里面有3个参数,下面以\(\pi\)为例子求解。因为\(\sum_{t=2}^T\log a_{i_{t-1},i_t}\)和\(\sum_{t=1}^T\log b_{i_t}(o_t)\)两项与\(\pi\)无关可暂不考虑。
\[\begin{aligned}
\pi^{(t+1)}&=argmaxQ(\lambda,\lambda^{(t)})\\&=argmax\sum_{\pi}[\log\pi_{i_1}\cdot P(O,I|\lambda^{(t)})]\\&=argmax\sum_\pi\cdots\sum_{i_1}[\log\pi_{i_1}\cdot P(O,i_1,\cdots,i_T|\lambda^{(t)})]\\&=argmax\sum_{\pi}[\log\pi_{i_1}\cdot P(O,i_1|\lambda^{(t)})]\\&=argmax\sum_{\pi}^N[\log\pi_i\cdot P(O,i_1=q_i|\lambda^{(t)})]
\end{aligned}
\]
除此之外,\(\pi\)还有一个限制\(\sum\limits_{i=1}^N\pi_i=1\),一下使用拉格朗日乘子法解决这个问题:
\[L(\pi,\eta)=\sum_{i=1}^N[\log\pi_i\cdot P(O,i_1=q_i|\lambda^{(t)})]+\eta(\sum_{i=1}^N\pi_i-1)
\]
\[\begin{aligned}
\frac{\partial L}{\partial\pi_i}=\frac{1}{\pi_i}P(O,i_1=q_i|\lambda^{(t)})+\eta&=0\\
P(O,i_1=q_i|\lambda^{(t)})+\pi_i\eta&=0\\
\sum_{i=1}^N[P(O,i_1=q_i|\lambda^{(t)})+\pi_i\eta]&=0\\
P(O|\lambda^{(t)})+\eta&=0\\
\eta&=-P(O|\lambda^{(t)})
\end{aligned}
\]
将\(\eta\)代入\(P(O,i_1=q_i|\lambda^{(t)})+\pi_i\eta=0\)可得:
\[\pi_i^{(t+1)}=\frac{P(O,i_1=q_i|\lambda^{(t)})}{P(O|\lambda^{(t)})}
\]
Decoding问题-维特比算法(Viterbi)
【数之道 29】"隐马尔可夫模型"HMM是什么?了解它只需5分钟!
Decoding问题的本质:\(\hat{I}=arg \max\limits_I P(I|O,\lambda)\)
定义:\(\delta_t\left(i\right)=\max\limits_{i_1,i_2,\cdots,i_{t-1}}P(o_1,o_2,\cdots,o_t,i_1,\cdots,i_{t-1},i_t=q_i)\)
\(\delta\)的递推式:\(\delta_{t+1}(j)=\max\limits_{1\leq i\leq N}\delta_t(i)a_{ij}b_j(o_{t+1})\)
定义:\(\varphi_{t+1}(j)\)为\(\delta_{t+1}(j)\)所选择的最优的前一个状态i,即他的上一时刻的状态
则状态序号的公式如下:
\[\varphi_{t+1}(j)=arg \max_{1\leq i\leq N}\delta_t(i)\cdot a_{ij}
\]