文章目录
- 前言
- 一、安装环境
- 二、使用步骤
- 1.下载模型
- 2.实时录音转文本脚本
- 3.报错解决方法
- 总结
前言
要想实现像豆包、微信等一样的语音输入功能,通常有两种主流方案:云端 API(轻量、准确度极高)和 本地模型(免费、隐私、无需联网)。由于目前开发的系统需要添加一个语音识别功能,刚好记录一下使用 Faster-Whisper 实时语音输入转文本。Faster-Whisper官网地址链接: Faster-Whisper官网地址
复现成功如下图所示,请看下文教程就能部署本地实时语音输入转文本模型: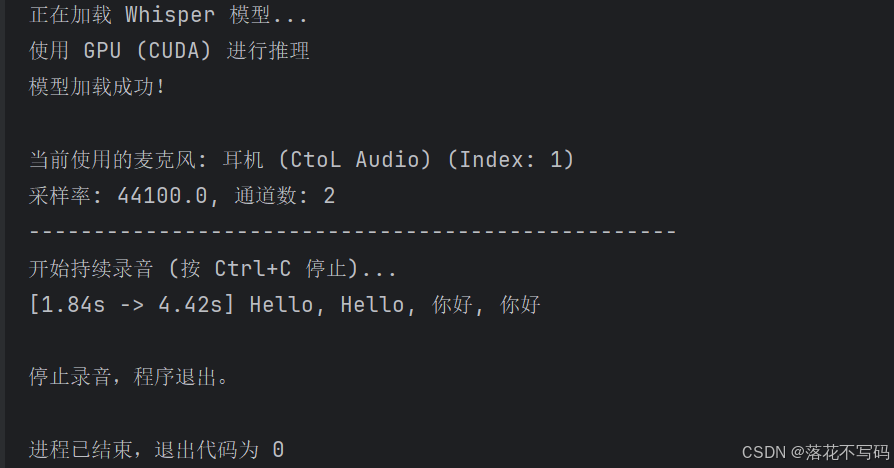
电脑有显卡的话可以参考下面这篇文章安装 cuda 和 cudnn
cuda和cudnn的安装教程: cuda和cudnn的安装教程(全网最详细保姆级教程)
一、安装环境
在你的虚拟环境安装 faster-whisper,命令如下:
pip install faster-whisper
安装录音库
pip install pyaudiowpatch
二、使用步骤
1.下载模型
手动下载(离线使用)
如果你的服务器无法联网,或者你想把模型放在指定文件夹,可以手动下载。根据需求点击链接下载:
- Tiny (最小/最快):Systran/faster-whisper-tiny
- Base:Systran/faster-whisper-base
- Small:Systran/faster-whisper-small
- Medium:Systran/faster-whisper-medium
- Large-v2:Systran/faster-whisper-large-v2
- Large-v3 (效果最好):Systran/faster-whisper-large-v3
- Distil-Large-v3 (蒸馏版/速度快):Systran/faster-distil-whisper-large-v3
在 Hugging Face 的 “Files and versions” 页面中,下载以下几个关键文件(放入同一个文件夹):
config.jsonmodel.bintokenizer.jsonvocabulary.jsonpreprocessor_config.json
我是下载 faster-whisper-large-v3 的模型下载链接: faster-whisper-large-v3 模型下载地址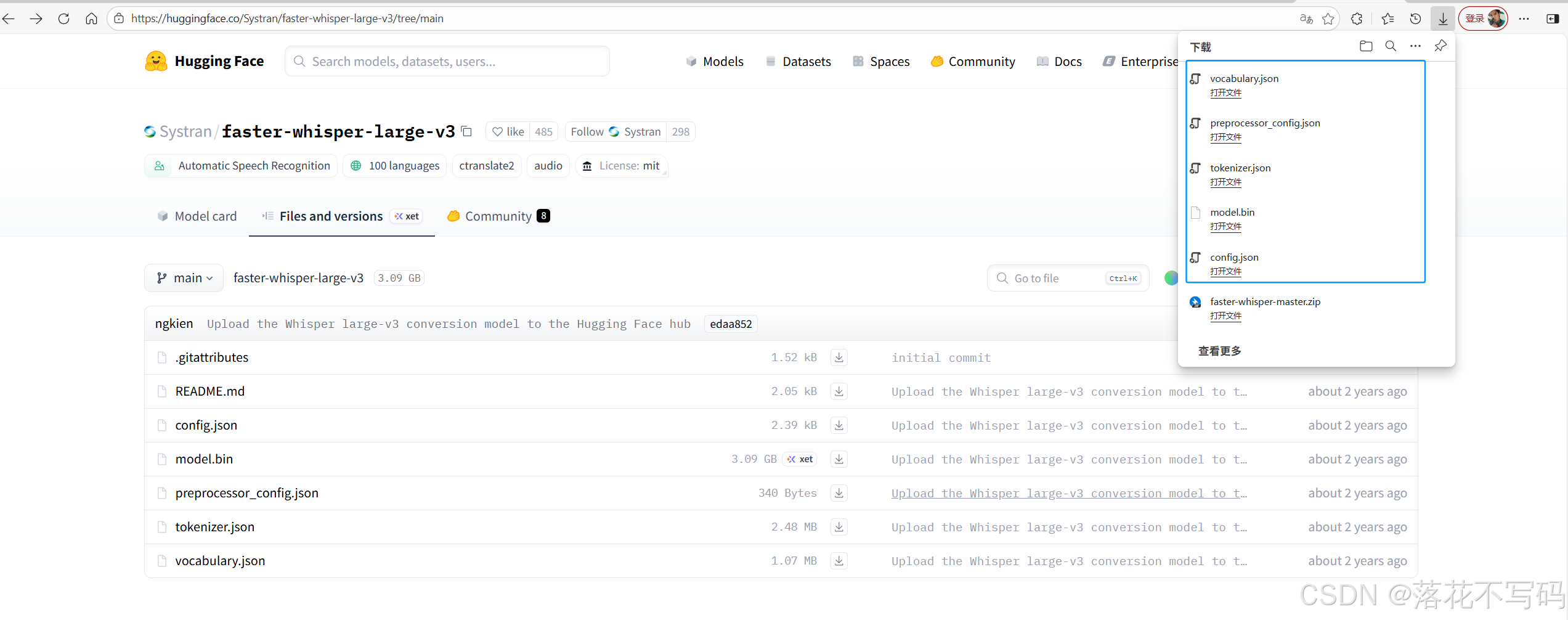
把下载的模型文件放到一个文件夹内: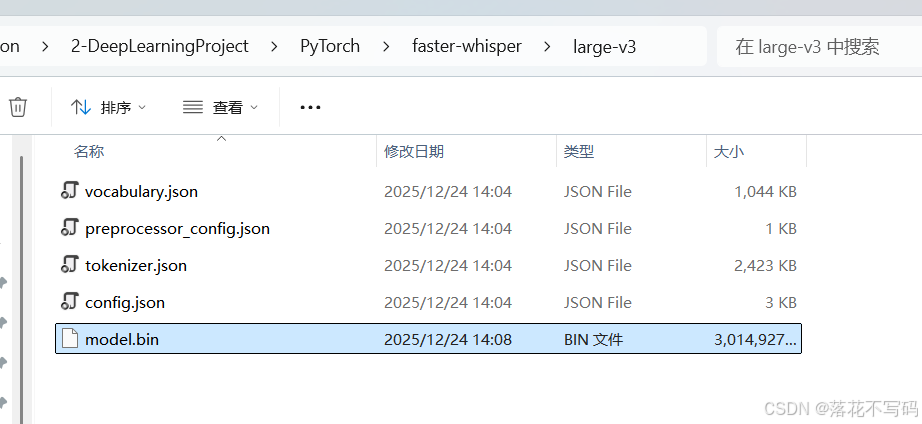
2.实时录音转文本脚本
代码如下(示例):
# -*- coding: utf-8 -*-
"""
@Auth :落花不写码
@File :mian.py
@IDE :PyCharm
@Motto :学习新思想,争做新青年
"""
import os
import sys
import time
import wave
import tempfile
import threading
import torch
import pyaudiowpatch as pyaudio
from faster_whisper import WhisperModel
# 录音切片时长(秒)
AUDIO_BUFFER = 5
def record_audio(p, device):
# 创建临时文件
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
filename = f.name
wave_file = wave.open(filename, "wb")
wave_file.setnchannels(int(device["maxInputChannels"]))
wave_file.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wave_file.setframerate(int(device["defaultSampleRate"]))
def callback(in_data, frame_count, time_info, status):
"""写入音频帧"""
wave_file.writeframes(in_data)
return (in_data, pyaudio.paContinue)
try:
stream = p.open(
format=pyaudio.paInt16,
channels=int(device["maxInputChannels"]),
rate=int(device["defaultSampleRate"]),
frames_per_buffer=1024,
input=True,
input_device_index=device["index"],
stream_callback=callback,
)
time.sleep(AUDIO_BUFFER) # 阻塞主线程进行录音
except Exception as e:
print(f"录音出错: {e}")
finally:
if 'stream' in locals():
stream.stop_stream()
stream.close()
wave_file.close()
return filename
def whisper_audio(filename, model):
"""
调用模型进行转录
"""
try:
# vad_filter=True 可以去掉没说话的静音片段
segments, info = model.transcribe(
filename,
beam_size=5,
language="zh",
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500)
)
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
except Exception as e:
print(f"转录出错: {e}")
finally:
# 转录完成后删除临时文件
if os.path.exists(filename):
os.remove(filename)
def main():
print("正在加载 Whisper 模型...")
# 检查 GPU
if torch.cuda.is_available():
device = "cuda"
compute_type = "float16" # 或者 "int8_float16"
print("使用 GPU (CUDA) 进行推理")
else:
device = "cpu"
compute_type = "int8" # CPU 上推荐用 int8
print("使用 CPU 进行推理")
# 模型路径
model_path = "large-v3"
try:
model = WhisperModel(model_path, device=device, compute_type=compute_type,local_files_only=True)
print("模型加载成功!")
except Exception as e:
print(f"模型加载失败: {e}")
return
with pyaudio.PyAudio() as p:
try:
default_mic = p.get_default_input_device_info()
print(f"\n当前使用的麦克风: {default_mic['name']} (Index: {default_mic['index']})")
print(f"采样率: {default_mic['defaultSampleRate']}, 通道数: {default_mic['maxInputChannels']}")
print("-" * 50)
print("开始持续录音 (按 Ctrl+C 停止)...")
while True:
filename = record_audio(p, default_mic)
thread = threading.Thread(target=whisper_audio, args=(filename, model))
thread.start()
except OSError:
print("未找到默认麦克风,请检查系统声音设置。")
except KeyboardInterrupt:
print("\n停止录音,程序退出。")
except Exception as e:
print(f"\n发生未知错误: {e}")
if __name__ == '__main__':
main()3.报错解决方法
报错:
Could not locate cudnn_ops64_9.dll. Please make sure it is in your library path!
Invalid handle. Cannot load symbol cudnnCreateTensorDescriptor
Faster-Whisper 所依赖的 CTranslate2 引擎是基于 cuDNN 9.x 版本编译的,我电脑上没有找到 cuDNN v9,看了一下官网的解释如下: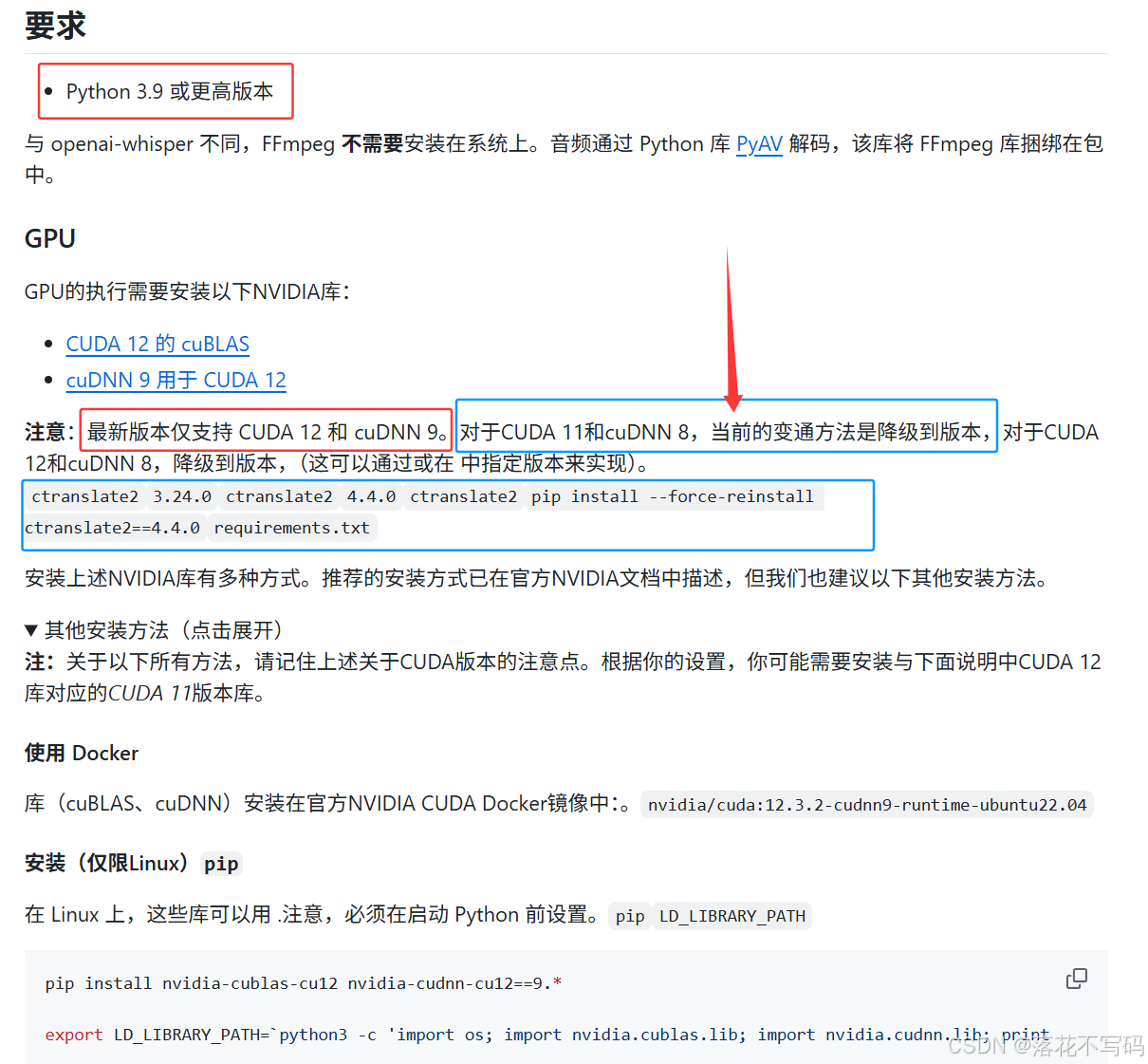
安装旧版本:
pip install --force-reinstall ctranslate2==4.4.0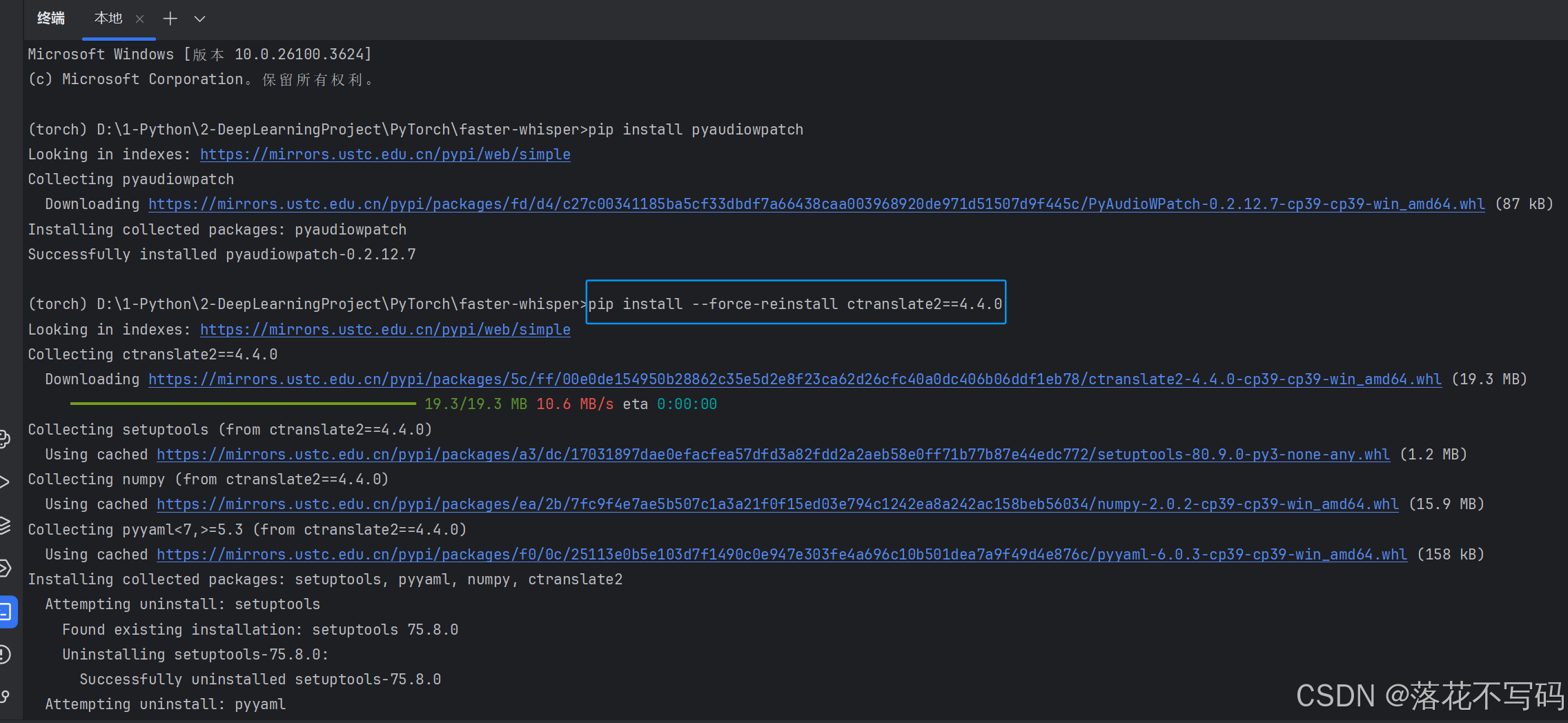
还是报错: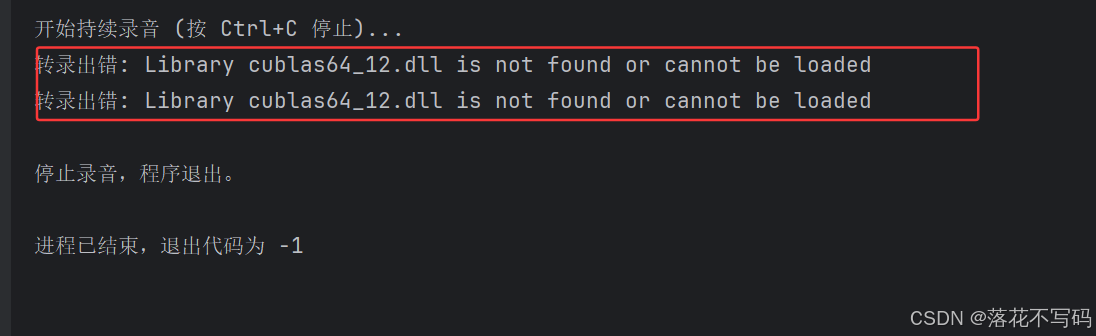
找到你的 CUDA 安装在其他位置,我的在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\bin
找到 cublas64_11.dll,复制出来,改成 cublas64_12.dll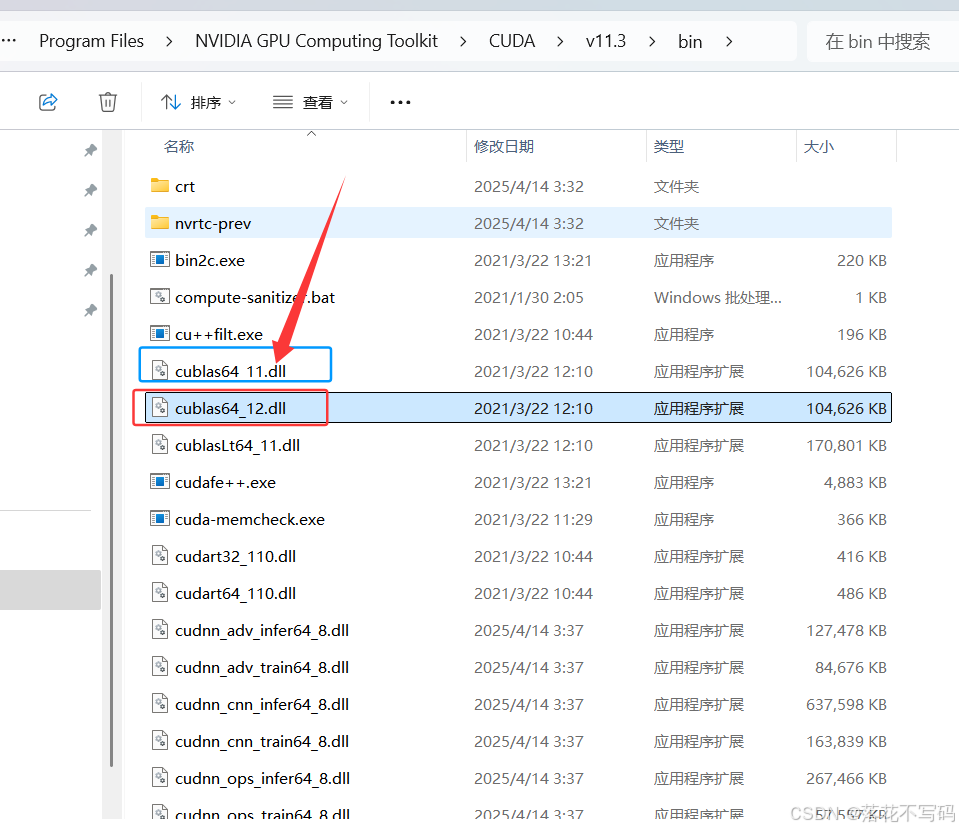
当我换了一个虚拟环境,使用 CUDA11.8 时候,虚拟环境已经安装了 CUDA11.8,报错:cuBLAS failed with status CUBLAS_STATUS_NOT_SUPPORTED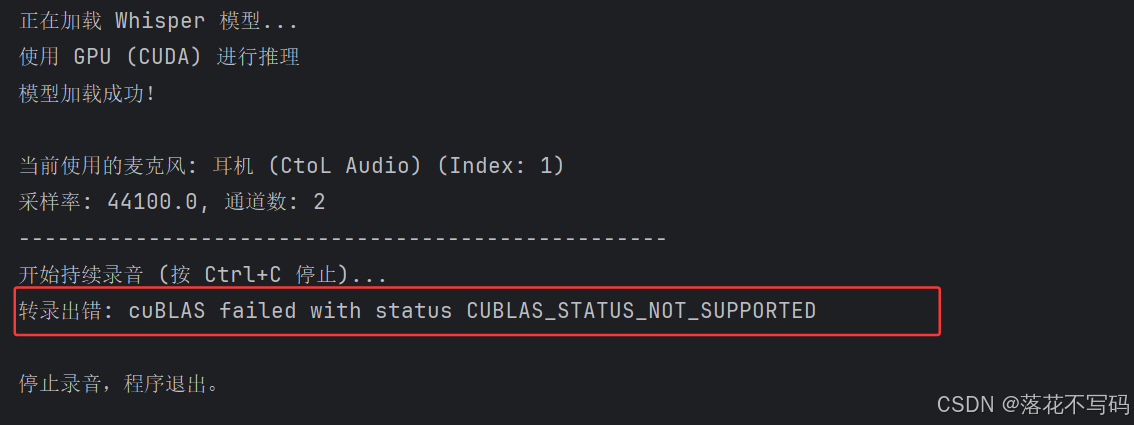
这是因为调用虚拟环境的 CUDA 11.8 ,PyTorch 安装的是 2.2.2+ cu118(自带 CUDA 11.8)如下图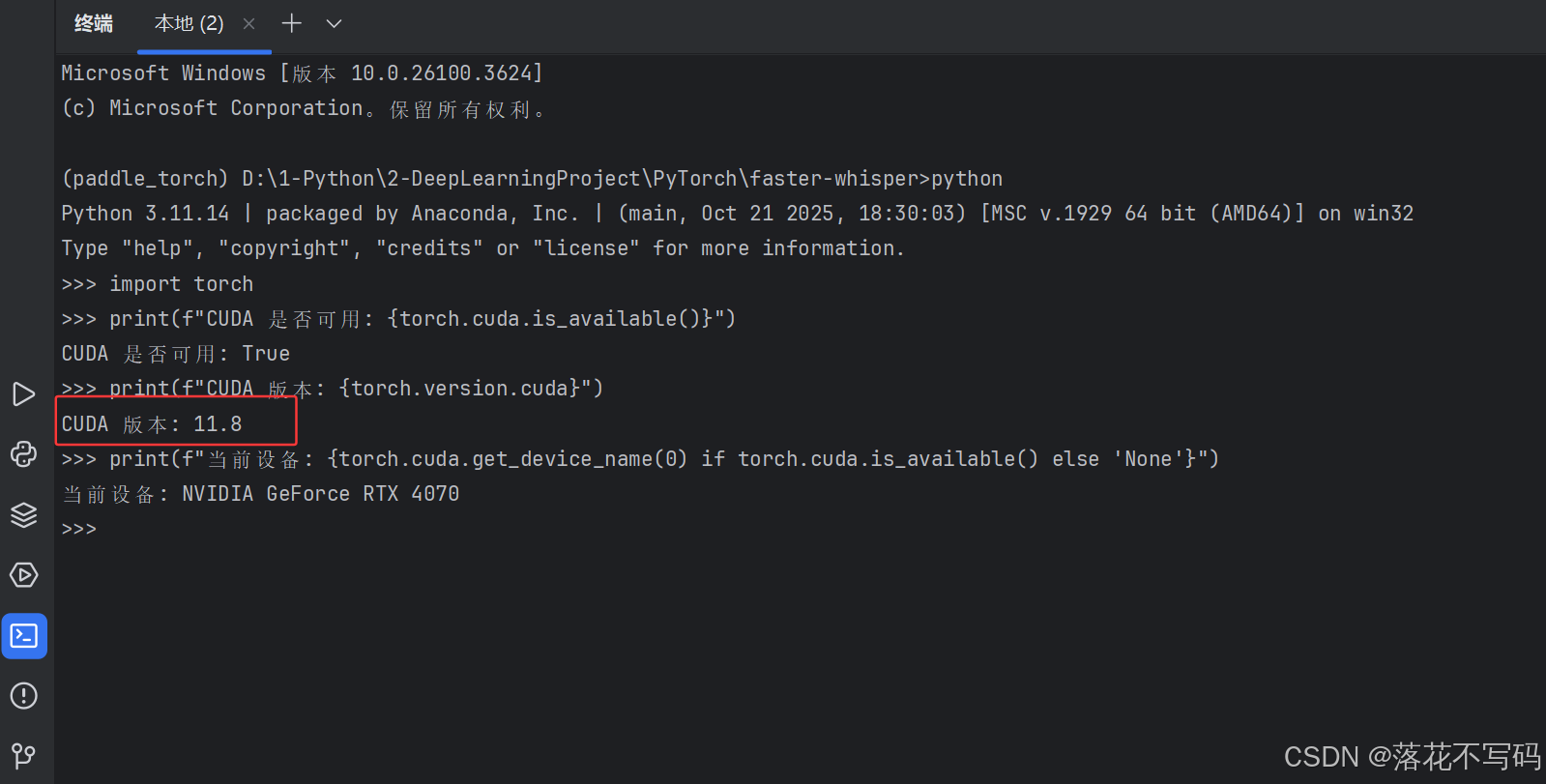
报错因为你虚拟环境没有 cublas64_12.dll ,那么跟之前的操作一样,找到你的虚拟环境 cublas64_11.dll 所在的位置,我的在 D:\1-Python\ProgramFiles\Miniconda\envs\paddle_torch\Lib\site-packages\torch\lib
把 cublas64_11.dll 复制一份,改成 cublas64_12.dll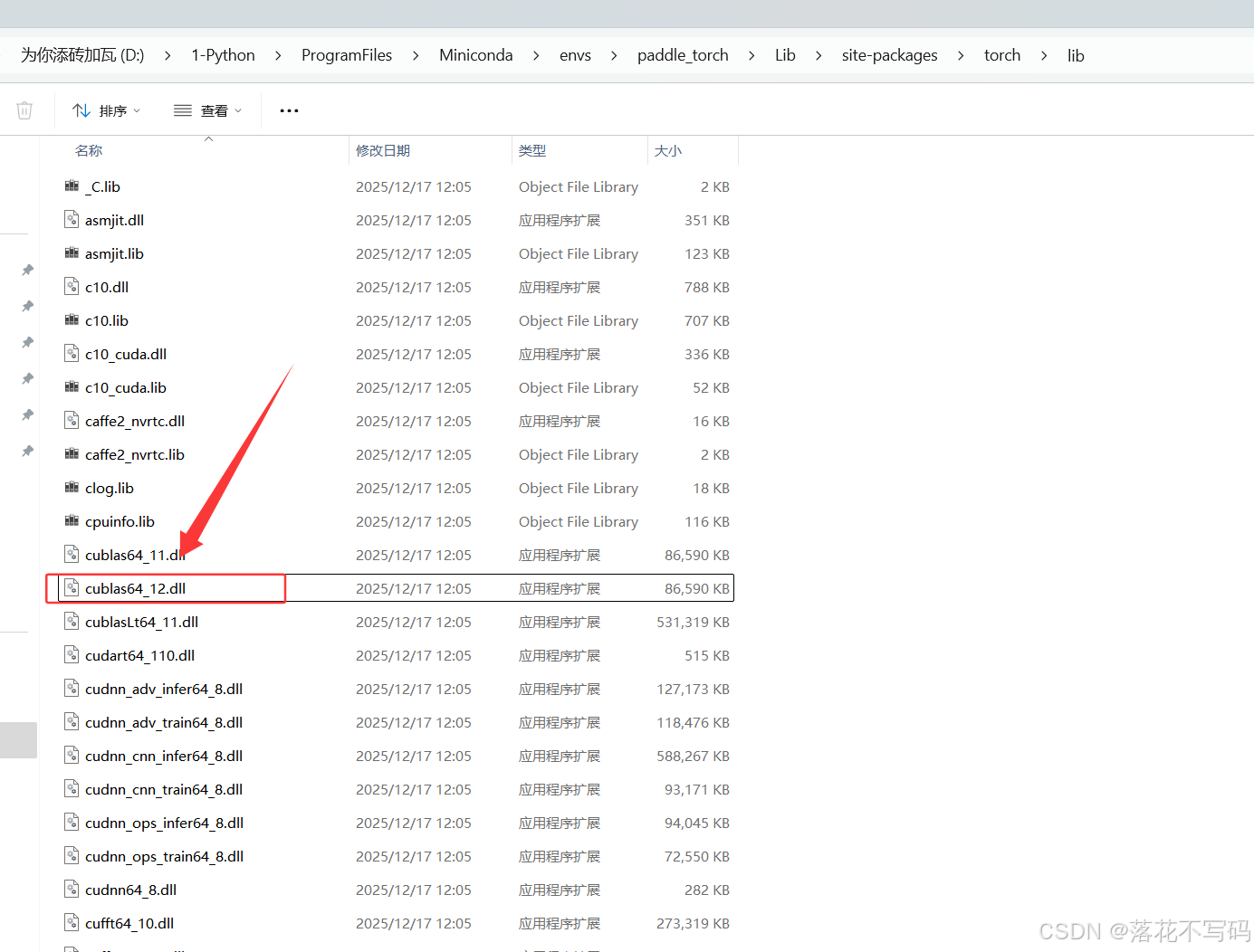
报错 :Applying the VAD filter requires the onnxruntime package
把 onnxruntime 库版本降低就行,我安装 1.19.2
pip install onnxruntime==1.19.2参考文章:
报错RuntimeError: Library cublas64_12.dll is not found or cannot be loaded
最后成功了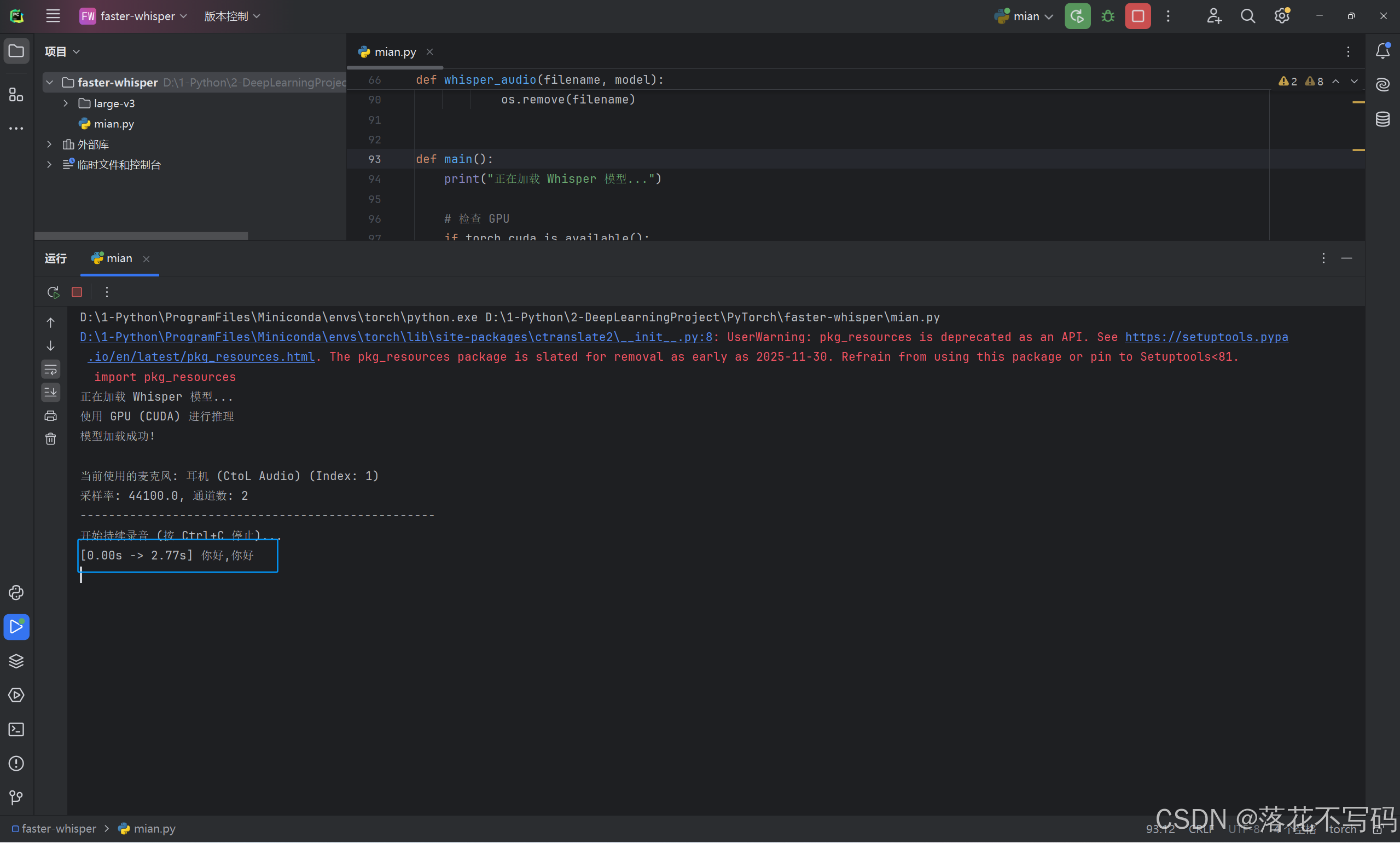
总结
对你有帮助请帮我一键三连。