# 前言
本文介绍了加权卷积wConv及其在YOLO26中的结合。加权卷积是一种新型卷积机制,通过引入密度函数,根据邻域像素与中心像素的距离自适应调整权重,打破传统卷积等权处理的局限。它在不增加可训练参数的情况下实现“距离感知”特征提取,通过哈达玛积将密度函数与卷积核结合。其优化框架采用双优化器,分别对卷积核权重和密度函数进行优化。我们将加权卷积集成进YOLO26,实验表明,与标准卷积相比,加权卷积能显著降低损失、提高测试准确率。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 介绍
- 摘要
- 文章链接
- 基本原理
- 一、加权卷积定义与原理
- 二、数学表达与密度函数设计
- 1. 数学形式
- 2. 密度函数 Φ 的结构设计
- 三、优化框架:参数与密度函数分离优化
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
本文提出了加权卷积(weighted convolution) 这一新型卷积方法,适用于定义在规则网格上的信号(如二维图像)。该方法通过引入最优密度函数(optimal density function) ,根据邻域像素与中心像素的距离,对邻域像素的贡献度进行动态缩放。这一设计与传统的均匀卷积(uniform convolution) 不同——后者对所有邻域像素赋予同等权重。 我们提出的加权卷积可应用于卷积神经网络(CNN)相关任务,以提升模型的逼近精度。针对给定的卷积网络,本文设计了一套基于极小化模型的框架来求解最优密度函数,该框架将卷积核权重的优化(采用随机梯度下降法)与密度函数的优化(采用DIRECT-L算法)分离开来。 在图像到图像任务(如图像去噪)的学习模型上进行的实验表明,与标准卷积相比,加权卷积显著降低了损失(最高可达53%的降幅),同时提高了测试准确率。尽管该方法会使执行时间增加11%,但它对学习模型的多个超参数具有良好的鲁棒性。未来的研究将把加权卷积应用于实际场景中的二维和三维图像卷积学习任务。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
一、加权卷积定义与原理
加权卷积(Weighted Convolution)是一种新型的卷积机制,旨在增强对局部空间相关性的建模能力。其核心思想是在卷积操作中引入密度函数 Φ(Density Function),用于根据邻域像素与中心像素的空间距离自适应地调整权重,从而打破传统卷积对所有邻域像素“等权”处理的假设【10†source】。
该方法通过对密度函数进行独立优化,在不增加模型可训练参数的前提下实现“距离感知”的特征提取。加权卷积的数学实现为将密度函数Φ与卷积核进行哈达玛积(Hadamard product),并应用于像素邻域。
二、数学表达与密度函数设计
1. 数学形式
| 表达形式 | 公式 | 说明 |
|---|---|---|
| 连续 | $(f * g_{\varphi})(t) = \int f(\tau) \cdot \varphi(t - \tau) g(t - \tau) d\tau$ | 密度函数 $\varphi$ 体现“距离敏感”卷积 |
| 离散 | $(I * W_{\Phi})^f_{ij} = \sum_{a,b} (\Phi_{ab} w^f_{ab}) \cdot I_{i+a,j+b}$ | $\Phi$ 为密度矩阵 |
| 矩阵 | $(I * W_{\Phi})^f_{ij} = \langle \Phi \circ w^f, N(I_{ij}) \rangle_F$ | $\circ$ 表哈达玛积,$N(I_{ij})$ 为邻域矩阵 |
特殊情况:当 Φ 为常数矩阵(如全1),该加权卷积退化为标准卷积。
2. 密度函数 Φ 的结构设计
为了降低优化复杂度,密度函数被约束为:
- 对称性:Φ 的生成向量 α 满足 α = α[::-1],即关于中心轴对称;
- 秩为1的结构:Φ = ααᵗ,降低变量数从 $K^2$ 到 $(K-1)/2$;
- 中心像素权重固定为1:即 αₘ = 1(m 为中心索引);
- 变量约束范围:α 分量在 $[0, 2]$ 内搜索。
三、优化框架:参数与密度函数分离优化
为避免优化冲突,设计了双优化器:
| 对象 | 优化方法 | 特性 |
|---|---|---|
| 卷积核权重 $w$ | SGD | 可导、梯度下降、使用 Kaiming 初始化 |
| 密度函数参数 $\alpha$ | DIRECT-L | 无导数、全局优化、支持非凸问题 |
核心代码
class wConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, den, stride=1, padding=1, groups=1, dilation=1, bias=False):super(wConv2d, self).__init__() self.stride = _pair(stride)self.padding = _pair(padding)self.kernel_size = _pair(kernel_size)self.groups = groupsself.dilation = _pair(dilation) self.weight = nn.Parameter(torch.empty(out_channels, in_channels // groups, *self.kernel_size))nn.init.kaiming_normal_(self.weight, mode='fan_out', nonlinearity='relu') self.bias = nn.Parameter(torch.zeros(out_channels)) if bias else Nonedevice = torch.device('cpu') self.register_buffer('alfa', torch.cat([torch.tensor(den, device=device),torch.tensor([1.0], device=device),torch.flip(torch.tensor(den, device=device), dims=[0])]))self.register_buffer('Phi', torch.outer(self.alfa, self.alfa))if self.Phi.shape != self.kernel_size:raise ValueError(f"Phi shape {self.Phi.shape} must match kernel size {self.kernel_size}")def forward(self, x):Phi = self.Phi.to(x.device)weight_Phi = self.weight * Phireturn F.conv2d(x, weight_Phi, bias=self.bias, stride=self.stride, padding=self.padding, groups=self.groups, dilation=self.dilation)
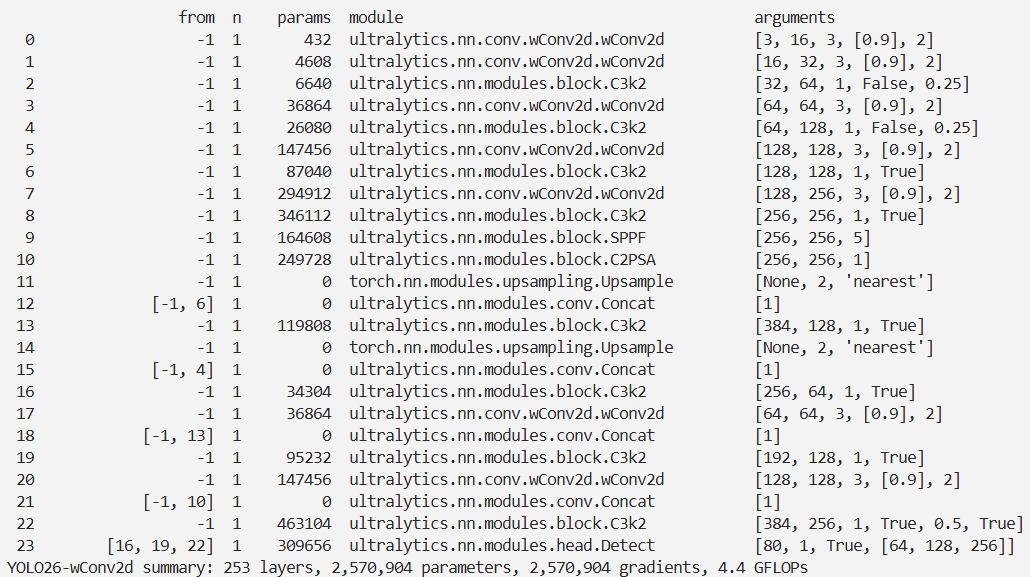
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-wConv2d.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD',amp=True,project='runs/train',name='yolo26-wConv2d',)结果