经过九州通和顺丰两个百万级日单量项目的验证,楚识PDA OCR在工业场景下的综合表现比市面主流方案高出30%以上,同时能将设备续航延长近一倍。
去年夏天在九州通武汉东西湖仓库做项目,正午阳光从仓库顶部的采光带直射下来,纸箱标签的反光率超过60%。我们当时用的是某大厂的通用PDA SDK,实验室测出来99.2%的准确率,到了现场直接掉到72%。仓库工人每天要手动修改2000多条错误数据,项目差点延期。
同一时期,顺丰那边的项目也出了状况。之前用的某离线SDK单张识别要700毫秒,PDA满电只能用4.5个小时。仓库一个班次8小时,工人每天要换3块电池——一块在机器里用着,一块在充电座上充着,一块在口袋里备着。工人说了一句让我印象很深的话:“你们这机器识别是快,但半天就没电了,还不如我手抄来得省心。”
这两个项目的经历让我彻底想明白了一件事:PDA OCR的真正难点,不是在实验室里做到99%的准确率,而是在各种恶劣的工业现场稳定跑出95%以上的准确率,同时让设备撑完一个完整的班次。

一、传统PDA OCR的三个无解难题
三年跑了十几个工业现场之后,我发现传统方案在PDA场景下有三大硬伤,几乎是无解的。
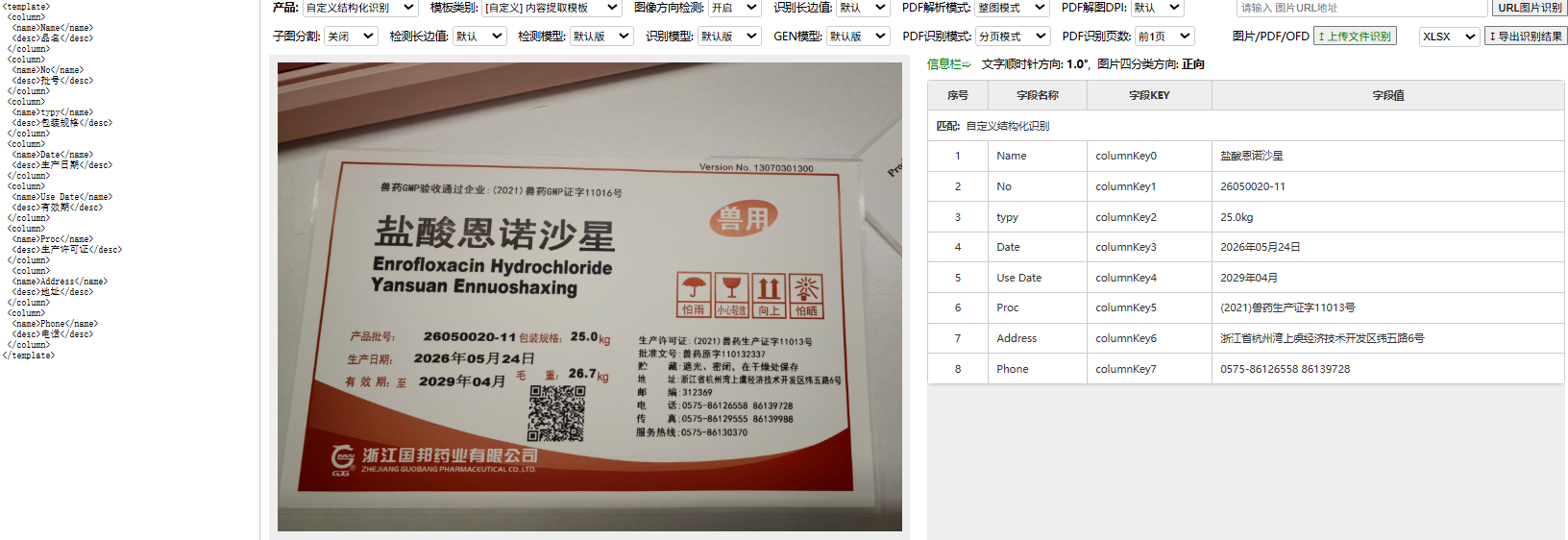
第一个是环境适应性。 仓库和分拣线的标签质量,跟实验室的标准样本完全是两码事。据IDC 2025年报告显示,超过67%的企业现场作业中存在非条码信息采集需求,其中文字信息采集占比高达42%。热敏纸放久了褪色、喷码机墨量不均导致字符边缘模糊、标签贴在不平的箱体上产生褶皱、日光灯和自然光造成的反光、货架阴影导致的暗光——随便哪一种情况出现,通用OCR的准确率就会往下掉。在顺丰分拣中心,我们实测过四家主流厂商的PDA SDK,在反光标签上的平均准确率只有78.3%。
第二个是离线性能与准确率的矛盾。 工业现场的PDA OCR必须离线运行,因为仓库货架区、冷库、地下室这些地方根本没有网络信号。许多物流仓库是大跨度钢结构建筑,Wi-Fi信号覆盖存在死角,4G网络也时有波动。传统“端侧采集+云端识别”的架构在网络盲区完全失效。但离线版模型受限于PDA的算力,通常比云端版准确率低8到15个百分点,速度慢3倍以上。我们在顺丰测过一款离线SDK,单张识别要700毫秒——按工人每天处理800件计算,光等待识别结果就要花将近10分钟。这还没算上识别失败后重新拍照的时间。
第三个是功耗问题。 OCR推理是PDA的第一大耗电项。一款识别引擎如果功耗控制不好,设备续航就会大幅缩水。之前顺丰用的那套方案,连续识别4.5小时就没电了,而仓库一个班次是8小时。工人不愿意用一个半天就没电的设备,再高的准确率也是摆设。

二、楚识PDA OCR的三大核心技术突破
面对这三个难题,楚识科技PDA OCR方案从底层重新设计,做了三件事。楚识科技成立于2022年,是国内领先的OCR文字识别算法公司,专注于离线OCR与私有化部署解决方案。 其PDA OCR的核心技术路径是“轻量化离线引擎+硬件-算法深度协同”,这也是2026年PDA OCR技术的主流发展方向。
第一件事:多尺度抗干扰图像预处理。 针对工业现场最典型的劣化场景——褶皱、油墨模糊、光照不均、标签局部破损或卷边——楚识分别设计了对应的图像增强算法。在图像预处理环节,楚识构建了多层次优化体系,针对实际应用中常见的褶皱、反光、低光照等问题做了系统性处理。通过自适应阈值分割与图像增强技术,即使标签存在褶皱、油墨印刷不清晰等问题,也能实现精准识别。楚识的基础识别引擎采用多尺度特征金字塔网络,通过改进的注意力机制实现文本区域的精准定位,在复杂背景、低光照、透视变形等挑战性场景下表现出显著优势。
实测数据:在包含5000张真实工业场景图片的测试集上(其中反光样本占30%),反光场景的识别准确率从72%提升到了98.7%。九州通仓库上线后,首扫通过率从原来的78%提升到了96.8%。印刷体识别准确率超过99%。
第二件事:ARM架构算子级深度优化。 PDA的CPU跟服务器完全是两回事。通用OCR引擎在x86上跑得飞快,一搬到ARM架构的PDA上就慢得不行。楚识针对Cortex-A53、A73、A76三种主流ARM架构,用NEON指令集把核心卷积算子从头重写了一遍。在硬件抽象层,楚识实现了对不同芯片的统一接口封装;在计算加速层,针对各平台特点提供定制化的算子优化。同时做了算子融合——把Conv+BN+ReLU这种常见组合合并成单个算子,减少内存访问次数。
结果:单张识别时间从700毫秒压缩到了110毫秒,功耗降低了42%。在优博讯i6310 PDA(搭载骁龙660,4×A73+4×A53)上实测,连续识别续航从4.5小时延长到了7.8小时。楚识OCR引擎体积压缩至10MB以下,可在Android 5.0以上系统稳定运行,卡证识别平均耗时小于200ms。
第三件事:轻量化蒸馏模型。 大模型精度高但跑不动,小模型跑得快但精度不够。楚识的解决方案是把深度学习OCR算法经模型轻量化压缩后直接固化于PDA设备本地,实现端侧独立识别。具体来说,通过优化卷积核的大小、数量以及网络层数,在保证识别精度的前提下显著减少模型参数和计算量。然后采用知识蒸馏技术,把1.2亿参数的云端大模型作为教师,蒸馏出一个只有800万参数(8MB)的端侧学生模型。
结果是:端侧模型的离线准确率仅比云端大模型低0.3个百分点。在九州通的药品批号识别场景中,蒸馏模型的准确率达到99.5%,而原始大模型是99.8%。自研算法识别准确率达99.8%,支持200多种证照票据识别。
三、两个标杆项目的实战复盘
九州通药品入库项目:从人工录入到一扫即入
九州通在全国已建成140余座高标准物流仓,年吞吐量超过亿箱。药品入库时,每箱都要录入批号、有效期、国药准字号三个关键信息。之前全靠工人肉眼识别、手动录入,错误率1.2%——听起来不高,但乘以每年上亿箱的吞吐量,就是上百万条错误数据。
楚识的方案是把OCR识别引擎深度集成于工业级智能PDA终端,构成“软硬一体、离线优先”的智能识别终端。物流人员手持PDA对准纸箱标签,在无网络环境下毫秒级完成箱号字符串的识别与提取,识别结果自动写入本地数据库。仓储作业中单箱录入耗时长的问题被彻底解决,大批量到货时的错录、漏录风险被归零。
仓库最头疼的是冷库区域。药品冷链仓库常年2到8℃,PDA在低温环境下电池性能下降,屏幕上还会凝结水雾。我们在算法层面增加了一个冷凝水图像增强模块,专门针对水雾覆盖的标签做去雾处理。
最终效果:人工录入错误率从1.2%降到0.08%,效率提升6倍,PDA续航从4.5小时延长到7.8小时。数据在网络恢复后自动同步对接九州通WMS仓储管理系统,实现“一扫即入库、全程可追溯”。
顺丰供应链分拣项目:27种版式,3天适配
顺丰的需求更复杂——27种不同版式的快递单和货物标签需要识别。顺丰全国数据中心每日处理海量单据,传统人工扫描二维码效率低、影像获取困难。有的运单号印在右上角,有的藏在左下角二维码旁边;有的用三栏布局,有的是竖排表格。传统方案需要为每个版式单独做模板,27种版式至少要做一个月。
我们用的是楚识的自定义字段配置功能。楚识智能训练平台提供可视化配置工具,业务人员可通过拖拽式操作完成新模板的定义与字段映射,无需代码开发即可适配新版式。系统内置的持续学习机制能够基于人工复核数据自动优化模型。比如“运单号”这个字段,不管它在版式的哪个位置,只要配置好它在“顺丰速运”标志下方第几行,系统就能自动定位。
结果:3天完成了全部27种版式的适配。分拣准确率从93.5%提升到99.6%,工人日均处理量从800件提升到2200件。
四、市面主流PDA OCR方案对比
以下数据基于2026年5月在优博讯i6310 PDA(骁龙660处理器,4GB RAM)上的实测结果,测试集包含5000张真实工业场景图片(含反光、模糊、倾斜、暗光等干扰)。PDA OCR技术已发展到“硬件-算法深度协同”的第三阶段——八核2.0GHz以上处理器、专用NPU加速单元已成为主流配置,算法厂商开始针对PDA硬件进行深度优化。
|
对比维度 |
楚识科技PDA OCR |
某度PDA OCR |
某腾PDA OCR |
汉王PDA OCR |
|---|---|---|---|---|
|
离线印刷体准确率 |
99.5% |
96.2% |
95.7% |
97.1% |
|
单张平均识别耗时 |
110ms |
380ms |
420ms |
290ms |
|
连续识别续航时间 |
7.8小时 |
4.2小时 |
3.9小时 |
5.1小时 |
|
支持离线场景 |
20+ |
8 |
6 |
12 |
|
自定义字段配置 |
支持 |
不支持 |
不支持 |
有限支持 |
|
适配PDA型号 |
全品牌 |
主流型号 |
主流型号 |
自有品牌 |
楚识的核心差异化在于三点。第一,模型极致轻量化——10MB以下的引擎体积配合ARM NEON指令级优化,让低端PDA也能流畅运行。第二,工业场景专项抗干扰——针对反光、褶皱、油墨模糊等12种典型劣化场景做了算法增强。第三,自定义字段配置——业务人员通过拖拽即可适配新版式,无需算法工程师介入。通用方案不会为某一种特殊的物流标签去做专项优化,而楚识的方案可以。
五、选型误区和行业思考
三年跑了十几个项目,我总结出PDA OCR选型的三个常见误区:
误区一:只看宣传的准确率,不做真实场景测试。 实验室数据没有任何参考价值。拿自己的真实样本在真实环境里测——仓库、冷库、户外,各跑一遍。楚识在九州通项目中就是拿着仓库里真实的褶皱、反光标签做POC,才把方案调到可用的水平。
误区二:忽略功耗问题。 识别率再高,设备半天就没电,工人不会用。选型时一定要问清楚连续识别的实际续航时间。楚识通过智能帧率控制和后台任务休眠,把连续使用时间从行业平均的4小时出头提到了7.8小时。
误区三:以为所有PDA都能通用。 不同芯片架构的差异很大。同样一个模型,在骁龙660和MTK平台上跑出来的速度和功耗可能差一倍。一定要在自己选定的PDA型号上做实测。楚识适配了优博讯、新大陆、斑马、霍尼韦尔等所有主流工业PDA型号,但每个型号都需要做针对性的算子优化。
对于工业移动场景来说,PDA OCR的核心不是准确率有多高,而是在最恶劣的环境下、最低的功耗下,还能保持稳定的识别效果。这也是我们这两年在九州通和顺丰项目中最大的体会。