影刀RPA初学者必读:5个最常见误区与正确做法
影刀RPA初学者必读:5个最常见误区与正确做法
作者:林焱
很多人学影刀RPA,上来就开始拖指令、拼流程,结果做出来的东西一运行就报错,改来改去越改越乱。这篇文章专门聊聊新手最容易踩的5个坑,以及每个坑对应的正确做法。不是泛泛而谈的"注意细节",而是实战中真的会让人翻车的具体问题。
误区一:上来就拖指令,不画流程图
这是90%的新手都会犯的错误——拿到需求,打开影刀编辑器,直接开始拖指令。拖到一半发现逻辑不对,又删掉重来,反反复复浪费大量时间。
错误示范
领导说:“帮我做一个自动采集京东商品价格的流程”。你马上打开编辑器:
- 拖一个"打开网页"
- 拖一个"输入文本"
- 拖一个"点击元素"
- 发现要翻页,又加循环
- 发现要保存数据,又加Excel操作
- 循环嵌套搞混了,删掉重来
正确做法
先画流程图,再写代码。不需要什么专业工具,拿张纸或在飞书文档里画个简单的流程图就行:
开始 ↓ 打开京东搜索页 ↓ 输入关键词 → 点击搜索 ↓ 循环:遍历商品列表 ├── 采集:商品名、价格、评论数 ├── 写入Excel当前行 └── 行号+1 ↓ 判断:是否还有下一页? ├── 是 → 点击下一页 → 回到循环 └── 否 → 保存Excel → 结束画完流程图,你会立刻发现几个问题:
- 循环的边界条件是什么?(按页数还是按"下一页"按钮是否存在)
- 数据写Excel从第几行开始?
- 下一页按钮加载慢怎么办?
这些问题在画图阶段就能发现,比拖完指令再改效率高10倍。
实战建议
踩坑经验:我之前带过一个新人,做电商采集流程,直接拖指令搞了2天没搞完。后来让他先画流程图,1小时就理清了逻辑,半天写完代码。流程图是给大脑用的,不是给别人看的。
误区二:硬编码一切,不会用变量
很多新手把所有值直接写在指令里——网址、文件路径、关键词、等待时间。一旦需求变了,改一个地方就要改十几个指令。
错误示范
# 所有值都硬编码打开网页("https://search.jd.com/Search?keyword=手机")等待(3)输入文本("#key","手机")# 又写了一遍"手机"[video(video-5LFRfAnn-1781724193012)(type-csdn)(url-https://live.csdn.net/v/embed/525000)(image-https://v-blog.csdnimg.cn/asset/23da3fe1f67a47106d725406cfde9a97/cover/Cover0.jpg)(title-拼多多店群自动化上架方案)]点击元素("button.button")# ...如果要把"手机"改成"笔记本",要改好几个地方正确做法
把会变的东西全部抽成变量,放在流程开头初始化:
# 在流程最开头定义所有配置变量keyword="手机"# 搜索关键词url=f"https://search.jd.com/Search?keyword={keyword}"max_page=5# 最大采集页数wait_time=3# 页面等待时间output_file="D:/采集结果/京东价格.xlsx"# 后续所有指令只引用变量打开网页(url)等待(wait_time)输入文本("#key",keyword)点击元素("button.button")# 以后改需求,只改开头的变量就行更进一步,可以把这些变量放到一个配置文件里(JSON或YAML),流程启动时读取。这样连代码都不用改,只改配置文件就行。
配置文件示例
{"keyword":"手机","max_page":5,"wait_time":3,"output_file":"D:/采集结果/京东价格.xlsx","headless":false}importjson# 读取配置withopen("config.json","r",encoding="utf-8")asf:config=json.load(f)keyword=config["keyword"]max_page=config["max_page"]真正跑到几十个流程后,你会发现配置和代码分离是维护效率的关键。不然改个路径就要重新打开编辑器找半天。
误区三:不做异常处理,流程一崩就完蛋
新手写流程,只考虑"正常情况"——网页正常加载、元素正常出现、数据正常返回。一旦某个环节出问题,整个流程直接崩溃,之前采集的数据也丢了。
错误示范
# 没有任何异常处理打开网页(url)点击元素("#login-btn")# 如果按钮没加载出来呢?输入文本("#username",user)# 如果输入框定位变了呢?获取文本(".price")# 如果价格元素被遮挡了呢?写入Excel(price)# 如果文件被占用了呢?正确做法
每个可能出错的地方都要有兜底方案。影刀RPA提供了Try-Catch指令,也有"元素是否存在"的判断指令:
# 完善的异常处理try:打开网页(url)# 检查元素是否出现,而不是直接点击if元素是否存在("#login-btn",timeout=10):点击元素("#login-btn")else:记录日志("登录按钮未找到,尝试备选方案")if元素是否存在(".btn-login"):点击元素(".btn-login")else:记录日志("所有登录按钮方案失败,跳过本次")continue# 获取数据时也要容错price_text=获取文本(".price")ifprice_text=="":price_text="价格缺失"写入Excel(price_text)exceptExceptionase:记录日志(f"采集失败:{str(e)}")截图保存(f"D:/错误截图/{当前时间}.png")# 继续下一个,而不是直接崩溃关键原则
网络操作必有超时:打开网页、点击元素都设timeout
数据操作必判空:获取文本后先判断是否为空
文件操作必检查:写入文件前检查目录是否存在
异常必记录:出错了要截图+写日志,方便排查
流程不能直接死:出错了要有恢复或跳过机制
误区四:一个流程搞定所有事
新手最容易犯的设计错误——把所有逻辑塞进一个巨大的流程里。采集数据、清洗数据、写入Excel、发邮件、发通知……全在一条线上。
这种流程的问题:
- 难以调试:报错了不知道是哪个环节的问题
- 难以复用:采集逻辑想给别的流程用,但搬不动
- 难以维护:改一个地方可能影响其他环节
- 难以并发:只能一个一个跑,不能分开提速
正确做法
拆成子流程,每个子流程只做一件事:
主流程:电商采集系统 ├── 子流程1:搜索与翻页(只负责打开页面和翻页) ├── 子流程2:数据采集(只负责从页面提取数据) ├── 子流程3:数据清洗(只负责处理脏数据) ├── 子流程4:数据存储(只负责写入Excel/数据库) └── 子流程5:通知推送(只负责发邮件/消息通知)子流程设计示例
子流程2:数据采集
# 输入参数:无(从当前页面采集)# 输出参数:items_list(采集到的商品列表)def采集当前页数据():items_list=[]商品元素列表=获取元素列表(".gl-item")for商品元素in商品元素列表:item={"名称":获取文本(商品元素,".p-name em"),"价格":获取文本(商品元素,".p-price strong i"),"评论":获取文本(商品元素,".p-commit strong a"),"链接":获取属性(商品元素,".p-name a","href")}items_list.append(item)returnitems_list这样做的好处:
- 采集逻辑可以单独测试,不用跑完整流程
- 换一个电商网站,只需要改"搜索与翻页"和"数据采集"两个子流程
- 数据存储从Excel换成数据库,只改"数据存储"子流程
真正在企业里跑的流程,拆分粒度是第一优先级。能拆多细拆多细,不要图省事。
误区五:不写注释不记日志,出了问题靠猜
这是最隐蔽的误区。流程写完了,当下能跑,就不管了。过了两周,流程报错了,打开一看——完全忘了当时为什么这么写。
错误示范
# 没有注释的代码a=获取文本(".p1")b=a.split("¥")[1]c=float(b)写入Excel(c)两周后你看到这段代码:a是什么?b是什么?为什么要split?如果价格没有¥符号怎么办?全都不知道。
正确做法
每一步操作都写清楚注释和日志:
# 获取商品价格文本,格式示例:"¥2999.00"raw_price=获取文本(".p1")# 提取数值部分:去掉¥符号# 注意:部分商品价格可能显示"暂无报价",需要特殊处理if"¥"inraw_price:price_str=raw_price.split("¥")[1]try:price_value=float(price_str)exceptValueError:记录日志(f"价格转换失败,原始值:{raw_price}")price_value=0.0else:记录日志(f"未找到价格符号,原始值:{raw_price}")price_value=0.0# 写入Excel第{row}行,价格列写入Excel(row,3,price_value)记录日志(f"已写入第{row}行价格:{price_value}")日志系统的最佳实践
TEMU店群如何管理运营?
importloggingfromdatetimeimportdatetime# 配置日志log_file=f"D:/logs/采集_{datetime.now().strftime('%Y%m%d')}.log"logging.basicConfig(filename=log_file,level=logging.INFO,format="%(asctime)s - %(levelname)s - %(message)s")# 关键节点记录日志logging.info(f"开始采集,关键词:{keyword},目标页数:{max_page}")logging.info(f"第{page}页采集完成,获取{len(items)}条数据")logging.warning(f"第{page}页翻页失败,尝试重新加载")logging.error(f"Excel写入失败:{str(e)},数据已缓存到临时文件")什么级别写日志?
| 级别 | 什么时候用 | 示例 |
|---|---|---|
| INFO | 正常流程节点 | “开始采集”、“翻页成功” |
| WARNING | 非致命异常 | “元素未找到,使用默认值”、“页面加载超时,重试” |
| ERROR | 致命错误 | “登录失败”、“文件写入失败” |
| DEBUG | 调试信息 | “当前变量值:xxx”(上线前删除) |
额外补充:新手常犯的小错误清单
除了上面5个大误区,还有这些小坑也值得注意:
1. 等待时间写死
# 错误:固定等3秒,可能多等也可能不够等待(3)# 正确:智能等待元素出现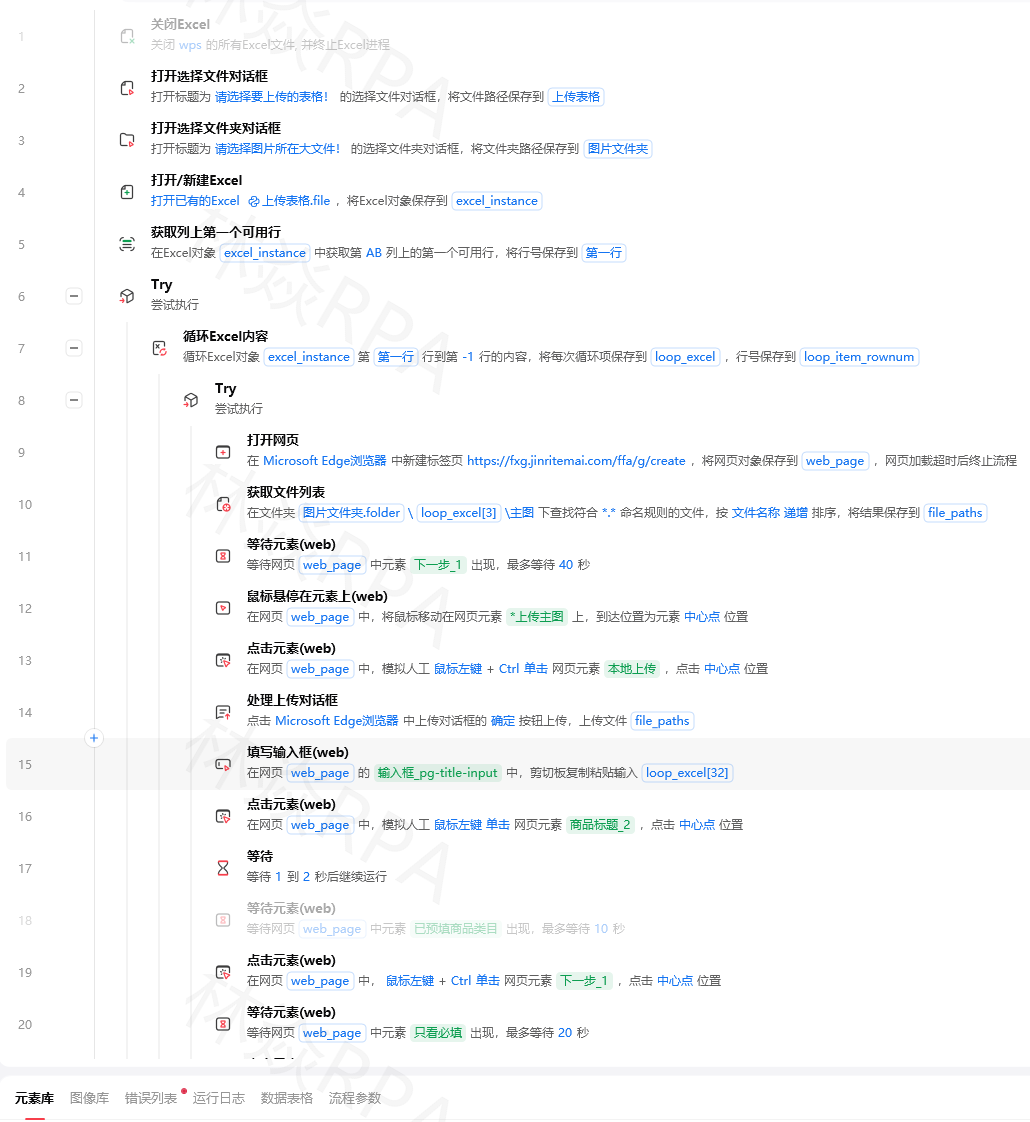等待元素出现("#result",timeout=10)2. 元素选择器太脆弱
# 错误:依赖XPath的绝对路径,页面稍微改版就失效点击元素("/html/body/div[3]/div[2]/ul/li[5]/a")# 正确:用CSS选择器或相对XPath,更稳定点击元素("a.product-link")点击元素("//ul[@class='product-list']/li[5]/a")3. 不处理弹窗
# 错误:没处理弹窗,后面的操作全部失效点击元素("#submit")# 正确:先检查弹窗,再继续操作点击元素("#submit")if元素是否存在(".dialog-confirm"):点击元素(".dialog-confirm .btn-ok")4. 文件路径用相对路径
# 错误:相对路径,换个目录运行就找不到文件打开文件("data/价格表.xlsx")# 正确:绝对路径或基于脚本目录的路径importos base_dir=os.path.dirname(os.path.abspath(__file__))打开文件(os.path.join(base_dir,"data","价格表.xlsx"))5. 循环不设上限
# 错误:万一翻页逻辑有bug,无限循环whileTrue:采集当前页()点击下一页()# 正确:设置安全阀page_count=0max_page=100# 安全上限whilepage_count<max_page:采集当前页()ifnot元素是否存在(".next-page"):break点击下一页()page_count+=1总结:新手的正确学习路径
| 阶段 | 应该做的事 | 不应该做的事 |
|---|---|---|
| 第一周 | 画流程图→写简单流程→学会变量 | 直接拖指令不管逻辑 |
| 第二周 | 加异常处理→加日志→拆子流程 | 一个流程塞所有逻辑 |
| 第三周 | 配置分离→函数封装→错误重试 | 硬编码一切 |
| 第四周 | 项目实战→性能优化→部署上线 | 只在编辑器里跑demo |
记住这5个原则:
- 先画图,再编码——逻辑比代码重要
- 用变量,别硬编码——需求一定会变
- 做异常处理——正常情况谁都会写,异常处理才是水平
- 拆子流程——一个流程只做一件事
- 写注释和日志——两周后的你会感谢现在的你
学影刀RPA不难,难的是写出能稳定运行的流程。把上面5个误区都避开,你已经超过80%的初学者了。
作者:林焱 | 如果觉得有帮助,欢迎点赞收藏,后续会分享更多影刀RPA实战经验