影刀RPA新手教程:零基础入门完全指南——从下载安装到独立开发
影刀RPA新手教程:零基础入门完全指南——从下载安装到独立开发小红书采集器
第一次听说影刀RPA是在一个运营群里,有人发了个截图:早上9点脚本跑起来,11点数据已经全采完写进Excel了,人在睡觉。我当时的反应是"这是什么东西"。
然后花了几天时间把整个流程走了一遍,发现门槛没有想象中高。不需要会Python,不需要懂前端,只要能用鼠标点界面,就能开始做东西。
这篇文章就是当时我希望自己能读到的那种:不绕弯子,直接告诉你每一步怎么做,坑在哪,优先学什么。
一、安装:10分钟搞定环境
去 www.yingdao.com 下载客户端,选Windows版,社区版免费,够用。
装好之后还要装浏览器插件,这一步很多人忘掉,后面捕获网页元素会报错。打开Chrome,进扩展程序页,搜"影刀",装上就行。Edge也一样。
装好之后界面分四块:
- 左边是指令区,所有操作指令在这里找
- 中间是流程编辑区,拖指令在这里搭
- 右边是属性区,选中指令后在这里填参数
- 下面是日志区,运行时的输出、报错都在这里
第一次打开感觉信息很多,别慌,用多了自然熟。
二、元素定位:这是最值得花时间的部分
我第一周大部分时间都卡在元素定位上。理解透了,后面基本顺了。
影刀定位网页元素有四种方式,要一起掌握,缺一不可。
直接捕获
点界面上的"捕获新元素",鼠标移到页面上的目标位置,点击,就抓到了。这是最简单的方式,适合稳定不变的元素。
捕获时可以加三种限制条件:文本内容(比如"加入购物车"这几个字)、元素属性(class或id)、层级关系(哪个父元素的第几个子元素)。
XPath定位
遇到捕获不稳定的元素,就上XPath。6种写法要会:
//div[@class='price'] # 精确属性匹配 //div[contains(@class,'item')] # 模糊匹配class //ul[@id='list']/li[3] # 取第3个li //div[@class='row']//span # 取所有后代span //span[text()='确认'] # 按文本匹配 //div[@class='child']/parent::div # 向上找父元素文本匹配是XPath最大的优势,CSS选择器做不到这件事。
CSS选择器
语法比XPath简洁,性能也好一些,8种常用写法:
.item-price/* class选择 */#submit-btn/* id选择 */.order > .price/* 直接子元素 */.order .price/* 所有后代 */li:nth-child(2)/* 第2个li */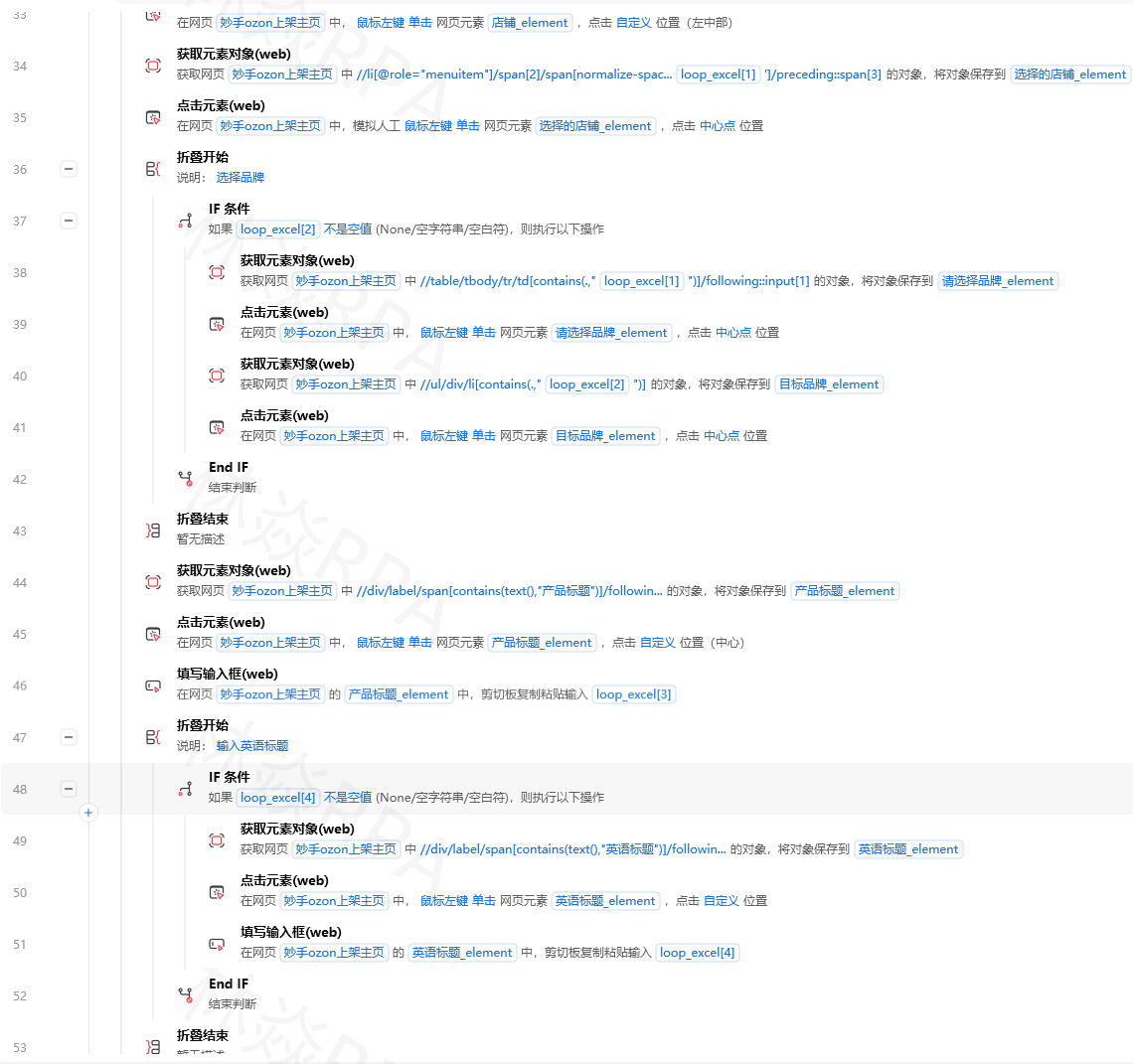[data-id='001']/* 属性匹配 */div.active.selected/* 多class */input[type='text']/* 属性值匹配 */选哪个?简单场景用CSS,需要文本匹配或向上查父节点就上XPath。
正则表达式
配合元素属性用,三个核心场景:属性值包含动态ID时用.*通配、多个关键词都要匹配时用(A|B)、配合全局变量动态替换时用变量名填正则位置。
三、变量与数据:跑通采集器的基础
数字:加减乘除直接用,取整用int()包一下。
字符串:用方括号取索引text[0]取第一个字符,用+拼接。文本操作指令集(提取文本、替换文本)比Python的字符串方法用起来更直接。
列表:追加用"追加元素到列表"指令,取值用下标,遍历用ForEach循环。
拼多多店群自动化报活动上架!
字典:键不存在时有两个处理方案——一是用.get('key', 默认值)指定缺省值,二是先用in判断键是否存在再取值。不处理的话会直接报错KeyError。
JSON:这是采集数据时必须会的链路:
HTTP请求返回字符串 → 用"文本转换为JSON"指令转成字典 → 按字典方式取值 → 用"JSON转换为文本"转回字符串写入Excel
四、流程控制:让程序跑起来
采集器的骨架就是循环加判断。
For次数循环:跑固定次数,翻多少页就设多少次。
相似元素循环:网页批量采集的核心。捕获一组相似元素(比如商品列表里的所有商品行),影刀会自动识别出几个,然后逐个循环处理。
ForEach列表循环:有一个列表,遍历每个元素处理。配合Excel读取一起用特别顺。
While条件循环 + 无限循环:不知道循环几次、要条件满足才停的场景。比如翻页翻到没有"下一页"为止。
If判断:条件为真执行A分支,否则执行B分支。多条件用"且/或"组合。
Try-Catch异常处理:Try里放主逻辑,Catch里放报错时的备用操作,Finally里放不管成不成功都要执行的收尾动作。
五、网页自动化:采集器的核心技能
等待策略(三种,会被坑别说我没提醒)
固定等待:等N秒,傻等,能用但不优雅。
等待元素出现:等到某个元素出现了再继续,适合页面加载慢的情况。
等待元素消失:等加载动画消失,然后开始操作。
推荐:用等待元素出现/消失替代固定等待,稳定性好很多。
弹窗处理
网页上的弹窗是新手第一个经典坑。标准5步流程:
- 等待弹窗出现(等待元素出现)
- 判断弹窗类型(确认弹窗/警告弹窗/自定义弹窗)
- 如果是浏览器原生弹窗,用"处理对话框"指令
- 如果是页面内自定义弹窗,直接捕获按钮点击
- 等待弹窗消失后再继续
还有一种"盲点弹窗"——流程跑到一半突然出来个弹窗,程序卡死。处理方法:在大循环外套一层Try-Catch,Catch里放"处理弹窗"逻辑,兜底用。
翻页
知道总页数:For次数循环,循环里点"下一页"按钮。
不知道总页数(最常见场景):查看"下一页"按钮的源码,最后一页时这个按钮的class属性会多一个disabled。在无限循环里判断这个属性,有disabled就退出循环。
//a[contains(@class,'next-btn')] # 通用匹配,能找到disabled状态和正常状态懒加载处理
以聚水潭为例,一页有50条订单,但网页代码里只加载了屏幕内的16条。往下滚,前面的就消失。
官方文档给的解法是index去重法:在循环里维护一个"记录列表",每次拿当前可见元素的index属性,判断是否在记录列表里。没有就采集并记录,有就跳过。同时每次循环后滚动鼠标,直到记录列表长度达到50为止。
iframe处理
遇到iframe里的元素捕获不到:先用"切换到iframe"指令切进去,操作完再用"跳出iframe"回到主页面。
六、数据处理:让采集到的数据落地
Excel读写
打开Excel:用"启动Excel"或"获取当前激活的Excel"。
读取:用"循环Excel内容"指令,每次循环项是一行,是个列表,取第一列用loop_item[0],取第二列用loop_item[1]。
写入:用"在单元格写入内容",指定行列坐标写入数据。
保存:操作完别忘了"保存Excel",不然数据没写进去。
常见报错有几个必须记:
Can not convert Array to String:循环Excel时没取具体列,把整行列表当字符串用了日期少8小时:时区问题,写入前加timedelta(hours=8)修正AttributeError: 'NoneType':Excel对象是None,没有用启动或获取指令赋值
JSON解析
HTTP接口返回的数据通常是JSON字符串,用"文本转换为JSON"转成字典后,按data['key']取值。
七、鼠标键盘操作
模拟模式 vs 驱动模式
默认模拟模式,操作在后台跑,不影响你用电脑。驱动模式更稳定,需要安装虚拟键盘驱动(在设置里找),但运行时会占用鼠标键盘。
图像识别
当元素捕获实在捕不到,上图像识别:截一张目标区域的图,然后用以下指令:
wait_appear:等待图像出现click:点击图像中心hover:悬停dblclick:双击
图像识别有一个锚点参数,9个位置(上中下 × 左中右),配合偏移量可以点图像旁边的位置。
八、进阶:HTTP请求和Python协同
HTTP请求
GET请求:设URL,选GET,直接发。返回值存到变量,转JSON后取需要的字段。
POST请求:多一个请求体参数,用字典格式填{"key": "value"}。需要鉴权的话在Headers里加Authorization: Bearer {token}。
Python协同
影刀支持调用Python代码块。定义方式:
defmain(args):data=args['input_value']result=data.strip().replace(' ','_')return{'output':result}跨模块调用需要在函数文件开头from . import package。
第三方库安装:在影刀设置里找Python环境路径,然后到命令行pip install requests即可,之后在代码里import requests正常用。
OCR文字识别
流程:截图 → OCR识别指令 → 从结果里提取文本。影刀内置验证码识别服务,支持纯数字、纯英文、数英混合、缺口识别等多种类型,按次收费,新用户有试用额度。
ADB手机自动化
连接手机:手机开USB调试,用"连接手机"指令,连接名自定义。
操作:session.click(x, y)点坐标,session.swipe(x1, y1, x2, y2)滑动,session.find_by_xpath('//')找元素,session.screenshot('D:\\')截图。
九、平台实战:以小红书采集器为例
TEMU店群矩阵自动化运营核价报活动
整个案例的主线:搜索关键词 → 翻页 → 采集每篇笔记的标题、作者、点赞数 → 写入Excel。
流程骨架:
打开浏览器 → 访问小红书搜索页 → 无限循环(翻页) → 等待页面加载完成 → 相似元素循环(每条笔记) → 获取标题文本 → 获取作者名文本 → 获取点赞数文本 → 追加到数据列表 → 检查下一页按钮是否disabled → 是则退出循环 → 点击下一页 → 将数据列表写入Excel → 保存Excel元素定位时,小红书笔记卡片的XPath参考:
//div[contains(@class,'note-item')] # 笔记卡片 //a[@class='title']/span # 标题 //span[@class='author']/span # 作者名 //span[contains(@class,'like-wrapper')] # 点赞数区域十、系统联动:流程跑完自动通知
飞书消息通知
流程跑完自动发消息,用飞书机器人:
- 飞书群里创建机器人,复制webhook地址
- 影刀里用HTTP请求(POST),URL填webhook,Body填消息内容(飞书卡片消息是JSON格式)
飞书多维表格
读写飞书多维表格比Excel更适合多人协作场景。影刀有专门的飞书指令集,支持读取记录、创建记录、更新记录。
邮件发送
用SMTP发邮件:配置发件服务器(smtp.qq.com:465 / smtp.163.com:465),填发件人、收件人、主题、正文,带附件时指定文件路径。
定时任务
流程写好后,在影刀调度中心创建计划任务,设置每天/每周/每月/指定时间自动运行,不需要人守着。
十一、工程化:让流程能长期稳定跑
子流程封装
把重复用到的逻辑(比如登录、翻页、写Excel)封装成子流程。好处:主流程清爽,改一处所有调用处都更新。
创建方式:新建一个应用作为子流程,定义输入输出参数,在主流程里用"调用子流程"指令调用。
调试
出问题不要靠猜,打断点一行行排查:
- 在报错指令前打断点(橙色点)
- 运行到断点暂停时,看左下角"调试变量"面板查看所有变量当前值和类型
- 单步调试一条条往下跑
- 找到异常变量后针对性修复
这是调试文档里的真实案例:AttributeError: 'NoneType' object has no attribute 'get_active_sheet'——Excel对象是None,意味着没有用启动Excel指令给变量赋值。
命名规范
- 流程名:动词+对象,比如"采集小红书笔记"
- 变量名:功能描述,比如
current_page、data_list - 子流程名:动词+对象+参数特征,比如"写入Excel_单行"
版本选择
社区版免费,适合个人学习和简单任务。创业版支持多机器人和更多指令。企业版支持调度中心、多用户、权限管理。学习阶段社区版够用。
十二、常见报错速查
| 报错 | 原因 | 解决方案 |
|---|---|---|
| 元素未找到 | 页面未加载完/动态属性/iframe | 加等待指令/修改XPath/切iframe |
| XPath语法错误 | 引号嵌套/节点名拼错 | 用双引号包单引号,或单引号包双引号 |
| Can not convert Array to String | 循环Excel时取了整行而非某列 | 改为loop_item[0]取具体列 |
| Excel日期少8小时 | UTC时区问题 | 写入前加8小时 |
| 无限循环跑不停 | 退出条件判断错了 | 打断点看条件变量的实际值 |
| 弹窗拦截后续操作 | 没处理突发弹窗 | 在循环外套Try-Catch,Catch里处理弹窗 |
如果想要一个系统的学习资源汇总,可以看 home.linyan.cloud,里面整理了影刀RPA的学习路径和常用指令清单。
#影刀RPA #RPA教程 #零基础入门 #网页自动化 #数据采集
作者:林焱