在大数据与物联网技术深度融合的今天,时序数据正以爆炸式增长的态势渗透到工业制造、智能运维、物联网监控等各个领域。据相关数据统计,时序数据在全球数据总量中的占比已超过60%,且年增长率保持在25%以上。面对如此庞大的数据规模,选择一款适配业务需求、性能卓越且成本可控的时序数据库,成为企业数字化转型过程中的关键决策。本文将从大数据视角出发,结合时序数据库的核心选型指标,通过与国外主流产品的对比分析,为大家解析Apache IoTDB为何能成为选型优选,并附上实操步骤与代码示例,助力企业快速落地。
目录
一、时序数据库选型的四大核心指标
1. 高吞吐量:应对海量数据写入的核心能力
2. 存储效率:控制大数据时代的存储成本
3. 兼容性:适配大数据生态的关键前提
4. 低运维成本:降低企业的技术投入门槛
二、主流时序数据库对比:IoTDB的差异化优势凸显
三、Apache IoTDB实操指南:从部署到数据查询全流程
1. 环境准备与部署安装
2. 数据写入与查询(Java SDK示例)
3. 可视化监控与管理
四、IoTDB为何是大数据场景的最优解?
一、时序数据库选型的四大核心指标
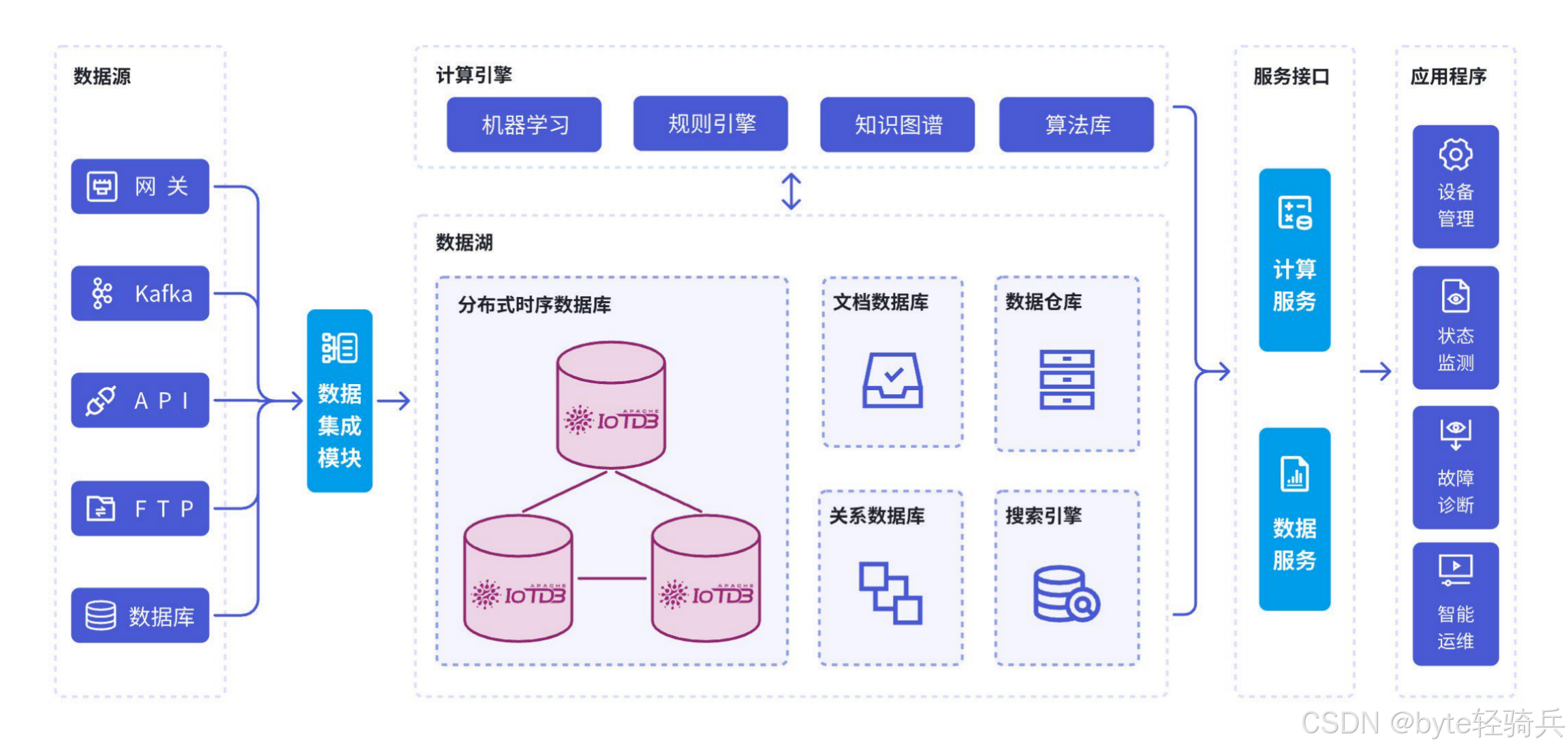
不同于传统关系型数据库,时序数据库的核心价值在于对“时间序列”数据的高效处理,尤其是在大数据场景下,其选型不能仅关注单一性能指标,而需从吞吐量、存储效率、兼容性及运维成本四个维度综合评估:
1. 高吞吐量:应对海量数据写入的核心能力
大数据场景下,时序数据通常具备“高并发、高写入”的特征,例如工业生产线的传感器每秒可产生数千条数据,智能城市的监控设备日均数据量可达TB级。此时,数据库的写入吞吐量直接决定了系统能否稳定承接业务压力。优秀的时序数据库需支持千万级/秒的写入能力,且在高并发场景下不会出现数据积压或写入失败的情况。
2. 存储效率:控制大数据时代的存储成本
时序数据的生命周期通常较长,部分工业数据需留存数年甚至十年以上用于追溯分析。若存储效率低下,将导致企业存储成本呈指数级增长。因此,选型时需重点关注数据库的压缩算法、分区策略及冷热数据分层存储能力,通过合理的存储优化将成本控制在可控范围。
3. 兼容性:适配大数据生态的关键前提
现代企业的数据分析体系往往基于Hadoop、Spark、Flink等大数据生态组件构建,时序数据库若无法与这些组件无缝集成,将大幅增加数据流转与分析的复杂度。理想的时序数据库应提供丰富的接口,支持与主流大数据工具的联动,实现数据采集、处理、分析的全流程打通。
4. 低运维成本:降低企业的技术投入门槛
对于多数企业而言,专业的数据库运维人员储备有限。时序数据库的部署复杂度、监控能力、故障恢复效率等运维相关特性,直接影响企业的技术投入成本。具备自动化部署、可视化监控、一键故障恢复的数据库,能显著降低运维门槛,更适合企业规模化应用。
二、主流时序数据库对比:IoTDB的差异化优势凸显
目前市场上的时序数据库种类繁多,其中国外主流产品如InfluxDB、Prometheus、TimescaleDB等占据了一定的市场份额。但在大数据场景下,这些产品的局限性逐渐显现,而Apache IoTDB凭借对国内业务场景的深度适配,展现出明显的差异化优势。以下从核心指标维度进行详细对比:
选型指标 | Apache IoTDB | InfluxDB(国外) | Prometheus(国外) |
|---|---|---|---|
写入吞吐量 | 支持千万级/秒写入,采用LSM树+时间分区优化,高并发场景下性能稳定 | 百万级/秒写入,高并发时易出现写入延迟,需额外部署集群扩容 | 十万级/秒写入,主要适配监控场景,海量数据写入能力不足 |
存储效率 | 自研时序压缩算法,压缩比可达1:20~1:50,支持冷热数据自动分层存储 | 压缩比1:10~1:20,冷数据存储需依赖第三方组件,成本较高 | 无专门压缩优化,存储体积较大,不适合长周期数据留存 |
兼容性 | 完美适配Hadoop、Spark、Flink等大数据生态,提供JDBC/ODBC接口及Python/Java SDK | 与大数据生态集成需自定义开发适配器,兼容性较弱 | 主要与Grafana联动,与大数据组件集成能力有限 |
运维成本 | 提供可视化管理界面,支持一键部署、自动备份与故障恢复,中文社区支持完善 | 开源版功能受限,企业版收费高昂,中文技术支持不足 | 配置复杂,需手动搭建监控与告警体系,运维门槛较高 |
从对比结果可以看出,Apache IoTDB在大数据场景下的综合表现更为出色。尤其是其自研的时序数据处理引擎,不仅解决了国外产品在高并发写入与存储成本上的痛点,更通过与国内大数据生态的深度融合,降低了企业的技术落地难度。此外,作为Apache顶级开源项目,IoTDB拥有活跃的中文社区,企业在使用过程中遇到问题能快速获得解决方案,进一步降低了运维风险。
三、Apache IoTDB实操指南:从部署到数据查询全流程
为帮助大家快速上手Apache IoTDB,本文将以Linux系统为例,为大家详细介绍从部署安装到数据写入、查询的全流程操作,并附上核心代码示例。
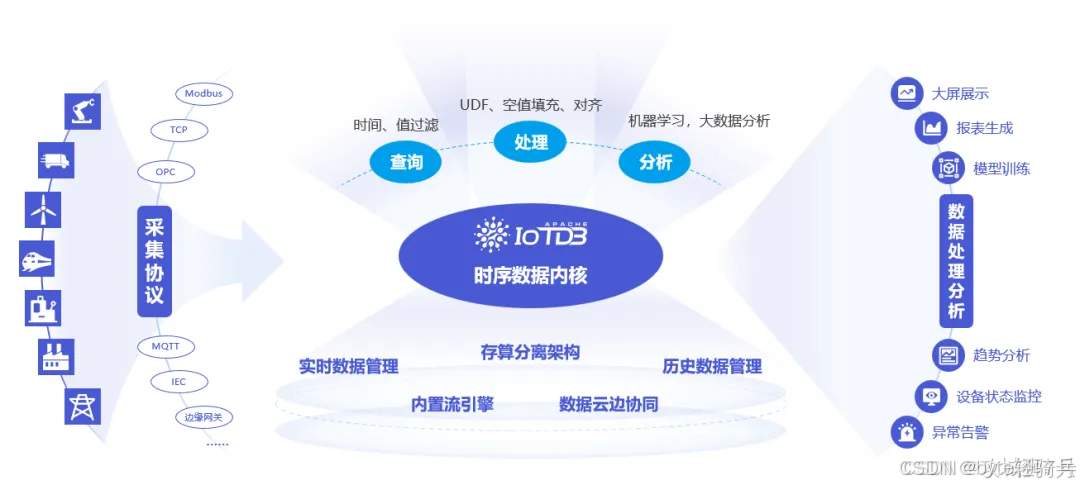
1. 环境准备与部署安装
Apache IoTDB支持单机与集群部署,本次以单机部署为例,环境要求为JDK 1.8及以上版本。
步骤1:下载IoTDB安装包
通过官方下载链接获取最新版本的安装包,下载链接:https://iotdb.apache.org/zh/Download/
使用wget命令直接下载(以1.2.0版本为例):
# 下载安装包
wget https://archive.apache.org/dist/iotdb/1.2.0/apache-iotdb-1.2.0-all-bin.tar.gz
# 解压安装包
tar -zxvf apache-iotdb-1.2.0-all-bin.tar.gz
# 进入安装目录
cd apache-iotdb-1.2.0-all-bin步骤2:配置与启动服务
修改配置文件(根据实际需求调整内存分配等参数):
# 编辑配置文件
vim conf/iotdb-engine.properties
# 核心配置参数(可根据服务器配置调整)
system_memory_size=8G # 系统内存分配
page_size=64KB # 页大小
chunk_size=64MB # 块大小启动IoTDB服务:
# 启动服务
sbin/start-server.sh
# 验证服务是否启动成功
jps | grep IoTDB若出现“IoTDBServer”进程,则表示服务启动成功。
2. 数据写入与查询(Java SDK示例)
Apache IoTDB提供了多种编程语言的SDK,本次以Java SDK为例,实现设备数据的写入与查询操作。首先在Maven项目中引入依赖:
org.apache.iotdb iotdb-jdbc 1.2.0
步骤1:数据写入代码实现
模拟工业传感器数据写入,包含设备编号、温度、湿度三个字段:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Random;
public class IoTDBDataWriter {// 数据库连接信息private static final String URL = "jdbc:iotdb://localhost:6667/";private static final String USER = "root";private static final String PASSWORD = "root";public static void main(String[] args) {// 注册驱动try {Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");} catch (ClassNotFoundException e) {e.printStackTrace();return;}// 连接数据库并写入数据try (Connection connection = DriverManager.getConnection(URL, USER, PASSWORD)) {// 创建表结构(设备路径:root.industrial.factory1.device1)String createSql = "CREATE TIMESERIES root.industrial.factory1.device1.temperature WITH DATATYPE=FLOAT, ENCODING=PLAIN";String createSql2 = "CREATE TIMESERIES root.industrial.factory1.device1.humidity WITH DATATYPE=FLOAT, ENCODING=PLAIN";try (PreparedStatement ps = connection.prepareStatement(createSql)) {ps.execute();}try (PreparedStatement ps = connection.prepareStatement(createSql2)) {ps.execute();}// 批量写入数据(1000条模拟数据)String insertSql = "INSERT INTO root.industrial.factory1.device1(timestamp, temperature, humidity) VALUES (?, ?, ?)";try (PreparedStatement ps = connection.prepareStatement(insertSql)) {Random random = new Random();long timestamp = System.currentTimeMillis();for (int i = 0; i < 1000; i++) {ps.setLong(1, timestamp + i * 1000); // 时间戳(毫秒级)ps.setFloat(2, 25 + random.nextFloat() * 10); // 温度:25-35℃ps.setFloat(3, 40 + random.nextFloat() * 20); // 湿度:40-60%ps.addBatch();// 每100条执行一次批量插入if ((i + 1) % 100 == 0) {ps.executeBatch();ps.clearBatch();}}ps.executeBatch();System.out.println("数据写入成功!");}} catch (SQLException e) {e.printStackTrace();}}
}步骤2:数据查询代码实现
查询指定时间范围内的设备数据,并对温度数据进行平均值统计:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class IoTDBDataQuery {private static final String URL = "jdbc:iotdb://localhost:6667/";private static final String USER = "root";private static final String PASSWORD = "root";public static void main(String[] args) {try {Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");} catch (ClassNotFoundException e) {e.printStackTrace();return;}try (Connection connection = DriverManager.getConnection(URL, USER, PASSWORD)) {// 查询最近100条数据String querySql = "SELECT temperature, humidity FROM root.industrial.factory1.device1 ORDER BY time DESC LIMIT 100";try (PreparedStatement ps = connection.prepareStatement(querySql);ResultSet rs = ps.executeQuery()) {System.out.println("最近100条设备数据:");System.out.println("时间戳\t\t\t温度(℃)\t湿度(%)");while (rs.next()) {long timestamp = rs.getLong("time");float temperature = rs.getFloat("temperature");float humidity = rs.getFloat("humidity");System.out.printf("%d\t%.2f\t%.2f%n", timestamp, temperature, humidity);}}// 统计最近1小时的平均温度long oneHourAgo = System.currentTimeMillis() - 3600 * 1000;String aggSql = "SELECT AVG(temperature) AS avg_temp FROM root.industrial.factory1.device1 WHERE time >= ?";try (PreparedStatement ps = connection.prepareStatement(aggSql)) {ps.setLong(1, oneHourAgo);try (ResultSet rs = ps.executeQuery()) {if (rs.next()) {float avgTemp = rs.getFloat("avg_temp");System.out.printf("%n最近1小时平均温度:%.2f℃%n", avgTemp);}}}} catch (SQLException e) {e.printStackTrace();}}
}3. 可视化监控与管理
IoTDB提供了Web可视化管理界面(IoTDB Workbench),通过浏览器访问http://localhost:8080即可进入。在界面中可实现表结构管理、数据查询、性能监控等操作,无需编写代码即可完成日常运维工作,极大降低了操作门槛。
四、IoTDB为何是大数据场景的最优解?
综合以上分析,Apache IoTDB在时序数据库选型中的核心优势可总结为三点:其一,性能卓越,通过自研的存储与写入引擎,完美适配大数据场景下的高并发、海量数据处理需求;其二,生态兼容,与国内主流大数据组件无缝集成,降低企业数据流转与分析成本;其三,开源可控,中文社区支持完善,运维成本低,且不存在国外产品的技术壁垒与合规风险。
对于有更高性能与定制化需求的企业,还可了解IoTDB的企业版服务,其在开源版本基础上提供了更专业的技术支持、性能优化及定制化开发服务,企业版官网链接:https://timecho.com。
在数字化转型的浪潮中,时序数据的价值不断凸显,选择一款合适的时序数据库成为企业提升核心竞争力的关键。Apache IoTDB以其出色的性能、完善的生态及较低的运维成本,无疑是大数据场景下的优选方案。相信随着开源社区的不断发展,IoTDB将在更多领域展现其独特的价值。