零样本学习------稳健的语义特征能力----富含语义信息的训练数据集----使用SOS数据集(主要关注语义重要区域内的低频特征)
密集预测任务-----处理高频细节--------擅长密集预测的与训练模型----使用COS模型(善于识别勾勒伪装对象边缘至关重要的高频特征)
SOS数据集 + COS模型,有利于零样本COS方法。
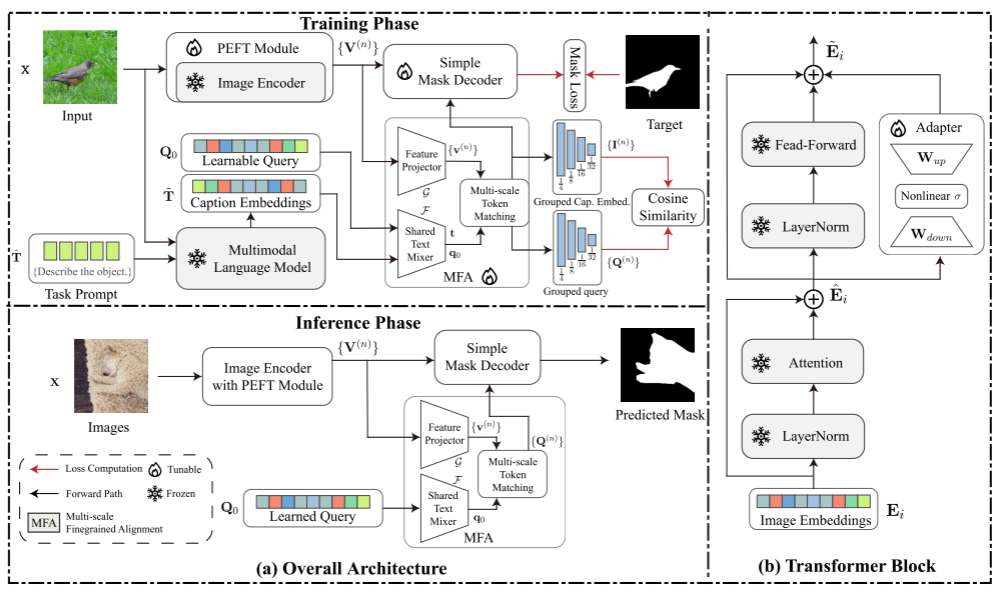
一、总体思路
我们的图像编码器,
先使用MIM(掩码图像建模)(一种自监督学习方法)进行预训练(MIM在捕捉高频细节方面有优势,提高模型在识别微小、复杂对象边界的精度(提高细节分辨率)),
再使用SOS数据集进行进一步改进(SOS数据通过细粒度对齐强调可辩别的语义对比(增强感知范围))。
上面提到了“SOS数据通过细粒度对齐强调可辩别的语义对比”,所以我们整合了M-LLM来提供细粒度对齐的caption(优化模型以捕获密集预测任务的复杂语义特征)。
MIM预先训练的图像编码器生成视觉嵌入,M-LLM在图像旁边处理prompt生成文本嵌入。
视觉嵌入与文本嵌入接着被对齐。
二、相关工作
问:论文中提出,ZSCOD(零样本伪装目标检测)和OVCOS(开放词汇伪装目标分割)仍依赖COS数据集进行微调?
答:
1、因为ZSCOD和OVCOS必须用COS数据微调以适配伪装任务特性,通过COS数据微调来 “锚定伪装任务特性”。
2、ZSCOD/OVCOS 需要 COS 数据微调,本质是通过标注样本让模型 “学习伪装任务的规则”(如 “目标与背景无明显边界”)。
3、若仅用 SOS 数据集(目标与背景差异显著)训练,模型会默认 “目标与背景有明显边界”,面对伪装场景时会因 “找不到清晰边界” 而失效。
4、而GenSAM不依赖COS数据集,是因为它复用了SAM强大的通用分割能力(通过SA-1B数据集 上千万张图像和分割标注训练过,已具备 识别伪装目标边缘 的能力,无需通过COS数据微调来学习“边缘捕捉”)+ 提示工程引导(如BLIP通过 大规模文本-图像数据 训练过,能理解“伪装目标”的语义概念,不需要再通过COS数据集微调来学习“伪装”)。
三、方法
1、PEFT部分
输入一张图片X,被块嵌入分割成块,并投影成图像嵌入E。
最初的Transformer块这样实现(i表示第i层):
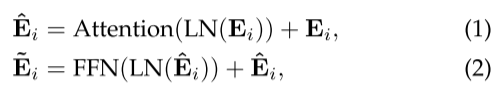
第i层得到的输出E将作为第i+1层的输入E。
改进:
使用并行Adapter,“输入 -> 下采样(Wdown降维) -> ReLU激活 -> 上采样(Wup升维)”。与传统Adapter相比,移除了层归一化LN,增加了偏置项(更精准地学习“通道级别的形状偏向特征”)。


将Adapter注入到Transformer块的前馈网络FFN分支中,保留分支(能保留MIM预训练学到的基础特征),加入Adapter(让Adapter专注学习SOS数据集的语义信息)。
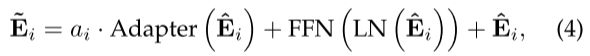
2、多尺度特征变化(简单特征金字塔SFP)
多尺度特征能覆盖不同尺寸的伪装目标 —— 低分辨率特征(如HW/32^2)适合捕捉大尺寸伪装目标的全局轮廓,高分辨率特征(如(H W/4^2))适合定位小尺寸伪装目标的局部细节(如昆虫的触角、鳞片)。
这些多尺度特征后续会与 M-LLM 生成的文本嵌入通过 MFA(多尺度细粒度对齐)模块对齐,为精准分割提供 “视觉细节 + 语义信息” 的双重支撑。
3、M-LLM生成caption嵌入
输入图片X,任务提示T,M-LLM得到对应caption嵌入。
4、MFA多尺度细粒度对齐
MFA包含三部分:特征投影仪、文本混合器、多尺度token匹配
多尺度图像嵌入 输入进特征投影仪得到多尺度图像token
输入进特征投影仪得到多尺度图像token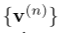 ,
,
caption嵌入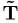 和可学习查询
和可学习查询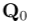 输入进文本混合器,得到文本token
输入进文本混合器,得到文本token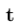 和查询token
和查询token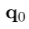 。
。

图像token、文本token、查询token输入进MFA得到:image-grouped caption embeddings 和image-grouped queries
和image-grouped queries 。
。
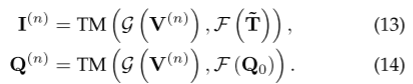
详细讲一下对齐的操作(计算相似度---归一化----稀疏化):
(1)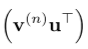 得到相似度矩阵;
得到相似度矩阵;
(2)相似度矩阵中的数值范围差异较大,所以进行归一化;
(3)稀疏化。

5、文本混合器与特征投影器








6、推理阶段使用查询Q替换掉M-LLM。和损失函数
训练阶段掩码解码器的输入是I(N),推理阶段换成Q(N)。
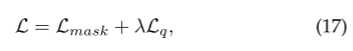
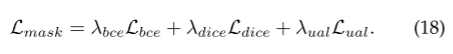
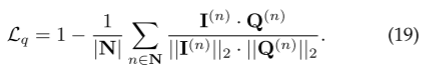
四、实验
1、零样本设置:
(1)EVA提前用MIM预训练,提前用SOS数据集预训练(5个):VST、SINet-V2、CRNet、EVP-Segformer、EVP-EVA02-L
(2)不训练,直接用COS数据集检测成果(4个):CAMO、COD10K、CHAMELEON、NC4K
在零样本策略和弱监督方法中均有很好效果(table 1):

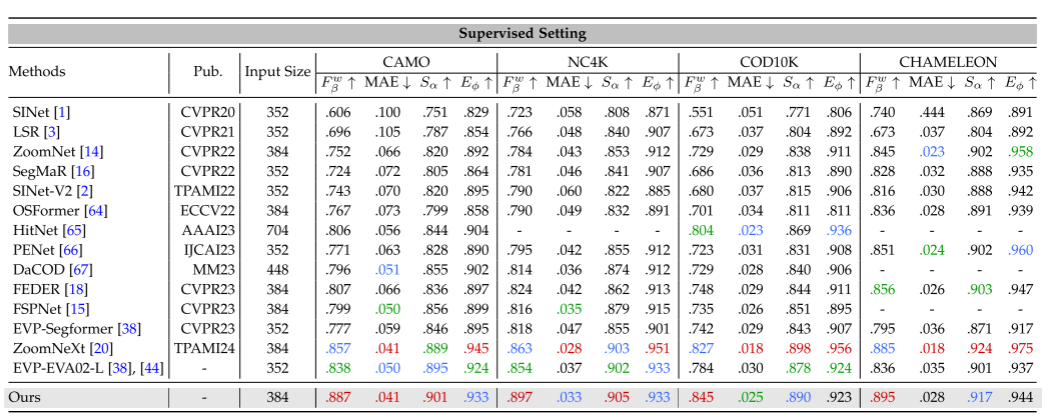
2、监督学习设置:
用COS数据集进行训练。效果很好。
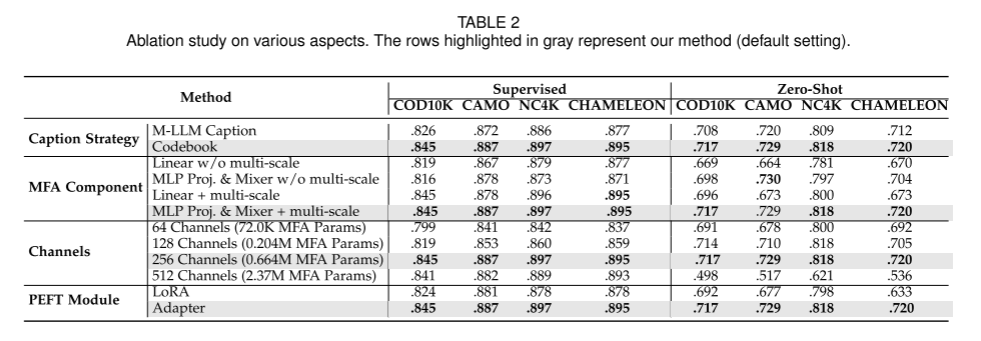
3、消融实验。
(1)推理阶段:码本 > M-LLM生成caption
(2)文本混合器中:线性投影仪、线性 + 多尺度 、MLP投影仪、MLP + 多尺度
(3)MFA模块中:特征投影仪 和 文本混合器 的频道
(4)PEFT的实现:Adapter > LoRA
(5)任务prompt(table 3)
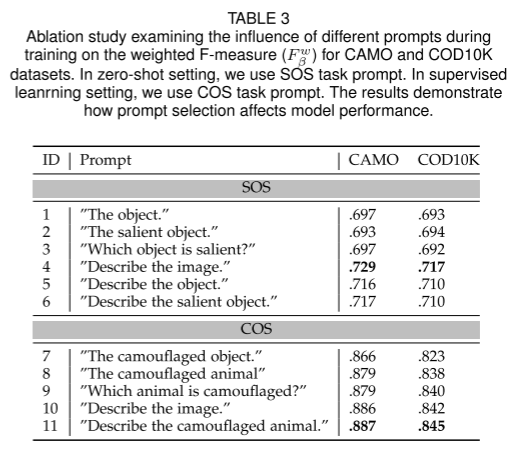
我们发现:“伪装动物” > “伪装物体”。所以通过指定伪装对象并详细描述,码本能够学习针对这些特定对象量身定做的更有效地表示,从而提高模型性能。