DeepSeek-OCR:10倍光学压缩新范式 - 实践
前段时间DeepSeek的新作,OCR 新SOTA,除了测评效果好(96% accuracy in 9~10x compression),更加值得注意的是对当前的LLM的一种第一性原理探索(vision-text compression):回归人类本质,我们的阅读的输出其实是图像,图像作为输入的好处是可以一目十行,这对于当前以attention为主的LLM是一个很大的性能进步!
下面学习下具体的模型做法:
具体的模型架构如下图所示,分一个Encoder结构和一个MOE架构的Decoder,Encoder做抽取视觉特征/Tokenizer/Compression,Decoder做OCR任务。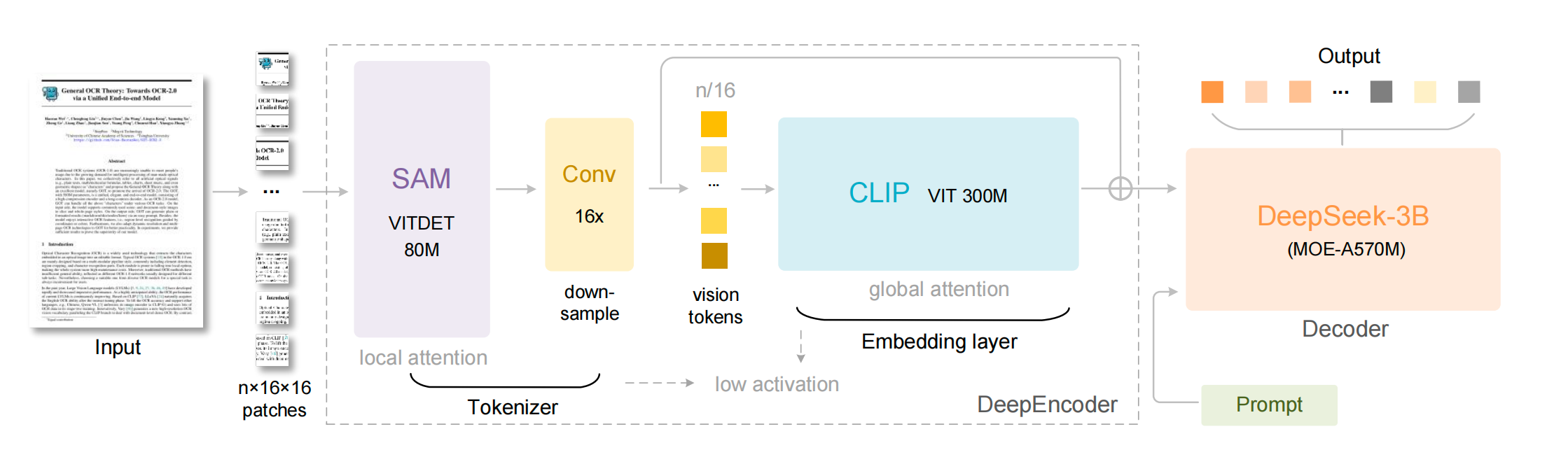
1. DeepEncoder:高分辨率输入 → 极少量视觉 tokens
DeepEncoder 是 DeepSeek-OCR 的关键创新,负责把高分辨率文档图片压缩成非常少的视觉 token,同时尽可能保留语义信息。它由三部分串联组成:
SAM-base → 16× Token Compressor → CLIP-Large如下图所示:
[High-res image]↓ SAM-base(局部注意力)4096 patch tokens↓ CNN 16× downsample256 latent tokens↓ CLIP-Large(全局注意力)1.1 SAM-base(80M):Window Attention 的高分辨率感知器
DeepEncoder 的第一部分是 SAM-base 的 Image Encoder。
SAM 的本质
SAM 的核心是一个 Vision Transformer(ViT-B),但它使用:
- Patch size = 16×16
- Window Attention(局部自注意力)
- Shifted Window 机制(跨窗口信息融合)
为什么选择 SAM?
因为 OCR 文档图像经常是:
✔ 极高分辨率(1024×1024 / 1280×1280 / PDF 渲染)
✔ 信息密度大(字符密集、布局复杂)
✔ 需要低激活(activation)以避免显存爆炸
Window Attention 的关键优点在于:
注意力只在每个窗口内部计算,不对整个 4096 tokens 全局自注意力。显存消耗从 N² 降到 (Window Size)² × NumWindows。
例如 1024×1024 图像:
patch = 16×16 → (64 × 64) = 4096 tokens
window = 16×16 tokens = 256 tokens
num windows = 16相比于全局 attention,显存消耗降低 16 倍以上,这是“低激活”的关键。
粗总结
SAM-base = 高分辨率输入 → 局部特征提取器 → 输出大量细粒度 patch token(4096)
但 SAM 的缺点是:
- 缺乏全局注意力
- 难以捕获跨页面的长距离语义
- token 数过多(4096)不能直接喂给 LLM
因此需要下一步压缩。
1.2 16× Token Compressor(两层 CNN):4096 → 256 Tokens
这是 DeepEncoder 的关键创新模块。
工作方式
使用 两层卷积(kernel=3, stride=2, padding=1):
Layer1: stride=2 → 空间分辨率减半(tokens ¼)
Layer2: stride=2 → 再减半(tokens 再 ¼)
总计:1/16举例
| 输入大小 | SAM 输出 | 压缩后 |
|---|---|---|
| 1024×1024 图 | 4096 | 256 |
为什么这么做?
CLIP-Large 使用 全局 attention,其计算复杂度是 N²。
如果直接给它 4096 tokens,会严重爆显存。
CNN 压缩模块把视觉 patch token 从 “密集局部” → “语义稀疏” 的 latent token。
这是整个 DeepEncoder 的核心亮点,使得:
- 高分辨率输入成为可能
- 全局语义编码负担可控
- 整体推理显存可接受
1.3 CLIP-Large(300M):全局语义建模
经过 CNN 压缩后的 256 tokens 会输入 CLIP-Large 的 Transformer 层。
CLIP-Large 的作用:
- 为全局 attention 提供框架,使不同区域 token 互相交流
- 注入大规模预训练的视觉语义知识
- 对 CNN 压缩后的 latent 表征进行更高层语义编码
最终输出
得到一组 final vision latent tokens:
- Tiny:64
- Small:100
- Base:256
- Large:400
- Gundam(Split High-res):600~800
这些 tokens 即是输入 Decoder 的视觉语义 embedding。
2. Decoder:Vision Token → 文字/结构输出的核心语言模型
DeepSeek-OCR 的 Decoder 选用了 DeepSeek-3B-MoE:
- 总参数:3B
- 激活参数:570M
- 专家数:64(每次 routing 6 个 + 2 shared)
- 12 层 Transformer
其职责是:
把 vision latent tokens 作为上下文 embedding,通过自回归方式生成完整的文本(OCR + Layout + HTML + SMILES + 几何结构)。
2.1 Decoder 的整体流程
Vision tokens(64/100/256/400/800)↓ 作为 context embedding
DeepSeek-3B-MoE Decoder(12 层 Transformer)↓ 自回归生成
Text tokens(600~1300+)Decoder 不是分类器,而是 生成模型:
✔ 生成 OCR 文本
✔ 生成包含坐标的 Markdown layout
✔ 生成 HTML table(表格)
✔ 生成 chart 结构化表数据
✔ 生成化学式(SMILES)
✔ 生成几何图形线段结构
非常灵活。
2.2 Decoder 的输入格式
Encoder 输出的视觉 latent tokens作为 Decoder 的 prefix:
[VIS_1] [VIS_2] ... [VIS_N] → 开始生成 prompt 可以指定模式:
- “Free OCR”
- “Convert the document to markdown”
- “Parse the figure”
- “Recognize chemistry formula”
- “结构化几何图”
2.3 DeepSeek-3B-MoE 内部结构
每层包含:
Multi-head Attention
↓
Router 选择 6 个 experts(+2 shared)
↓
FFN(专家执行)路由方式:
- Top-k Gating(GShard 机制)
- 每层只激活 8 个 FFN
MoE 的优势:
性能上:
- 拥有 3B 模型的表达能力
- 推理时实际仅用 570M 的 activations
成本上:
- 速度接近 1B~1.5B 模型
- 内存显著下降
适合 OCR 这种需要“语义恢复”能力的任务。
3. Encoder + Decoder:为什么能实现 10× 光学上下文压缩?
将整体链路串起来就能理解:
高分辨率图像(文本上千 token)↓ SAM-base(4096 tokens,局部感知)↓ CNN 16× 压缩(256 tokens)↓ CLIP-Large(语义编码)
→ 得到极少量视觉 latent tokens(64~800)↓ DeepSeek-3B-MoE(文本恢复)
生成 600~5000+ 文本 tokens本质上:
Encoder 做压缩(视觉 → 256 latent token)
Decoder 做恢复(256 latent → 1000+ text token)
实验表明:
- 10× 压缩 → 97% OCR 精度
- 20× 压缩 → 60% 可用精度
这种能力使模型具备“长文本光学压缩”的潜力。
4. 总结
DeepSeek-OCR 的核心创新不是单独的视觉模型或语言模型,而是 SAM(局部特征) + CNN(极限压缩) + CLIP(全局语义) + MoE LLM(结构化文本恢复) 的整体架构协同。
它展示了一种新的可能性:
用视觉作为压缩介质,把超长上下文通过图像编码压缩 10×~20×,再用 LLM 解码恢复——从而突破传统文本序列长度限制。