前言
本文介绍了将自注意力和卷积技术相结合的ACmix模型及其在YOLO26中的结合应用。研究发现自注意力和卷积存在强烈基础关系,大部分计算使用相同操作,且第一阶段计算复杂度占主导。ACmix通过将传统卷积和自注意力模块操作统一,实现了两种技术的优雅整合,还采用深度卷积替代低效张量移位操作,提高了效率。我们将ACmix集成进YOLO26,大量实验表明,改进后的模型表现优于基线。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 前言
- 摘要
- 创新点
- 文章链接
- 基本原理
- 核心代码
- 实验脚本
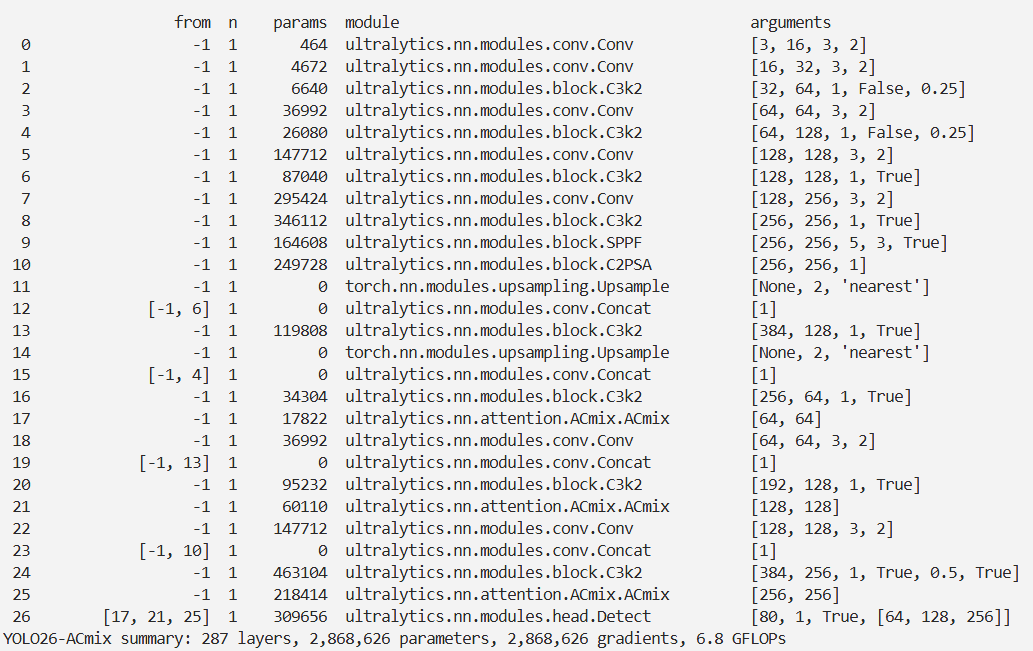
- 实验结果
摘要

卷积与自注意力作为两种强大的表示学习技术,传统上被视为彼此独立的并行方法。本研究揭示了二者之间存在的深刻内在联系,从计算视角分析表明,这两种范式的核心计算操作实际上具有高度一致性。具体而言,我们首先论证了传统k×k卷积可分解为k²个1×1卷积操作,辅以位移与求和运算;随后将自注意力模块中的查询、键和值投影过程解释为多个1×1卷积操作,继而计算注意力权重并进行值聚合。分析结果表明,两种模块的第一阶段均包含相似的计算操作。更为重要的是,相较于第二阶段,第一阶段在计算复杂度上占据主导地位(与通道数平方成正比)。这一关键发现自然引导出两种看似迥异范式的优雅整合方案——即一种同时兼具自注意力与卷积优势的混合模型(ACmix),该模型相比纯卷积或纯自注意力方法具有最低的计算开销。大量系统性实验验证表明,所提出的模型在图像识别及下游任务中相较于竞争性基线方法均取得了显著优越的性能表现。相关代码与预训练模型将发布于https://github.com/Panxuran/ACmix及https://gitee.com/mindspore/models平台。
创新点
-
发现共同操作:ACmix揭示了自注意力和卷积之间存在强烈的基础关系,指出它们的大部分计算实际上使用相同的操作。通过将传统卷积分解为多个1×1卷积,并将自注意力模块中的查询、键和值的投影解释为多个1×1卷积,ACmix发现了这两种技术之间的共同操作。
-
阶段性计算复杂度:ACmix强调了自注意力和卷积模块中第一阶段的计算复杂度较高,这一观察自然地导致了这两种看似不同范式的优雅整合。通过最小化计算开销,ACmix实现了自注意力和卷积的有效融合。
-
轻量级移位和聚合:为了提高效率,ACmix采用深度卷积替代低效的张量移位操作,实现了轻量级的移位操作。这种创新的方法改善了模型的实际效率,同时保持了数据的局部性。
-
模块化设计:ACmix采用了模块化的设计,将自注意力和卷积技术结合在一起,同时保持了模块之间的独立性。这种设计使得ACmix能够充分利用两种技术的优势,同时避免了昂贵的重复投影操作。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
ACmix是一种将自注意力(self-attention)和卷积(convolution)技术相结合的模型,旨在实现更高效的表示学习。
-
阶段I:
- 输入特征首先通过三个1×1卷积进行投影,然后被分成N个部分,每个部分包含3×N个特征图。
- 对于自注意力路径,将中间特征分成N组,每组包含三个特征片段,分别来自三个1×1卷积。这三个特征图分别用作查询(queries)、键(keys)和值(values),遵循传统的多头自注意力模块。
- 对于卷积路径,采用轻量级全连接层生成k^2个特征图。通过移位和聚合生成的特征图,以卷积方式处理输入特征,并从本地感受野中收集信息。
- 最后,两个路径的输出相加,其强度由两个可学习的标量控制:F_out = αF_att + βF_conv。
-
改进的移位和求和:
- 在卷积路径中,中间特征遵循传统卷积模块中进行的移位和求和操作。为了提高效率,采用固定卷积核的深度卷积来替代低效的张量移位操作。
- 通过深度卷积的固定卷积核,实现了轻量级的移位操作,避免了数据局部性的破坏,并更容易实现向量化。
-
阶段II:
- ACmix在第二阶段引入了额外的计算开销,包括一个轻量级全连接层和一个组卷积。这些计算复杂度与通道大小C成线性关系,相对于第一阶段来说较小。
- 通过轻量级全连接层和组卷积,实现了卷积路径中的特征生成和聚合,进一步提高了模型的灵活性和性能。

核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import time# 位置编码函数
def position(H, W, is_cuda=True):# 根据是否使用 CUDA 设备生成横向和纵向的位置编码if is_cuda:loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)else:loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)return loc# 步幅函数,按给定步幅下采样输入张量
def stride(x, stride):b, c, h, w = x.shapereturn x[:, :, ::stride, ::stride]# 初始化张量值为 0.5
def init_rate_half(tensor):if tensor is not None:tensor.data.fill_(0.5)# 初始化张量值为 0
def init_rate_0(tensor):if tensor is not None:tensor.data.fill_(0.)# ACmix 模块类定义
class ACmix(nn.Module):def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):super(ACmix, self).__init__()self.in_planes = in_planesself.out_planes = out_planesself.head = headself.kernel_att = kernel_attself.kernel_conv = kernel_convself.stride = strideself.dilation = dilationself.rate1 = torch.nn.Parameter(torch.Tensor(1))self.rate2 = torch.nn.Parameter(torch.Tensor(1))self.head_dim = self.out_planes // self.head# 定义三个 1x1 卷积层,用于生成查询、键、值self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)self.softmax = torch.nn.Softmax(dim=1)# 定义全连接层和深度卷积层self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)self.reset_parameters()def reset_parameters(self):# 初始化参数init_rate_half(self.rate1)init_rate_half(self.rate2)kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)for i in range(self.kernel_conv * self.kernel_conv):kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)self.dep_conv.bias = init_rate_0(self.dep_conv.bias)def forward(self, x):# 通过卷积层生成查询、键和值q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)scaling = float(self.head_dim) ** -0.5b, c, h, w = q.shapeh_out, w_out = h//self.stride, w//self.stride# 位置编码pe = self.conv_p(position(h, w, x.is_cuda).to(x.dtype))q_att = q.view(b*self.head, self.head_dim, h, w) * scalingk_att = k.view(b*self.head, self.head_dim, h, w)v_att = v.view(b*self.head, self.head_dim, h, w)if self.stride > 1:q_att = stride(q_att, self.stride)q_pe = stride(pe, self.stride)else:q_pe = pe# 展开键和位置编码unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 计算注意力权重att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) att = self.softmax(att)# 应用注意力权重到值out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)# 卷积部分f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])out_conv = self.dep_conv(f_conv)# 返回注意力和卷积的加权结果return self.rate1 * out_att + self.rate2 * out_conv
实验脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-ACmix.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD',amp=True,project='runs/train',name='yolo26-ACmix',)实验结果