# 前言
本文介绍了鲁棒特征下采样模块(RFD)与 YOLO26的结合,以解决遥感图像分析难题。RFD 包含浅层 SRFD 和深层 DRFD 两个版本,SRFD 用于替代主流骨干网络的浅层下采样层,有效提取和保留关键特征;DRFD 处理网络深层特征图,保留丰富语义信息。将现有主流主干网络的下采样层替换为 RFD 模块后,在多个公共遥感图像数据集上实验表明,在分类、检测和分割任务中性能显著提升。我们将 RFD 代码集成进 YOLO26,替换原下采样模块,实验脚本显示其在图像分析上有良好应用前景。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 介绍
- 摘要
- 文章链接
- 基本原理
- 1. 浅层鲁棒特征下采样(SRFD)
- 2. 深层鲁棒特征下采样(DRFD)
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
遥感(RS)图像因分辨率较低、目标较小且特征稀疏等特性,为计算机视觉(CV)领域带来了独特挑战。尽管主流主干网络在传统视觉任务中表现卓越,但其采用的卷积下采样操作往往导致遥感图像中小目标信息的严重丢失,从而影响整体性能。针对此问题,本研究提出了鲁棒特征下采样模块(Robust Feature Downsampling,RFD),通过融合多种下采样技术提取的特征图,生成具有互补特性的高鲁棒性特征表示,有效克服了传统卷积下采样的局限性,为遥感图像分析提供了更准确可靠的解决方案。
研究中,我们设计了两种RFD变体:浅层RFD(Shallow RFD,SRFD)和深层RFD(Deep RFD,DRFD),分别适用于特征提取的不同阶段,以增强特征表示的鲁棒性。通过将主流主干网络中的下采样层替换为RFD模块,并在多个公共遥感数据集上进行广泛实验验证,结果表明该方法在多种视觉任务中均取得显著性能提升。在NWPU-RESISC45分类数据集上,RFD模块无需额外预训练数据即实现了平均1.5%的性能提升,达到了当前最先进水平。此外,在DOTA目标检测数据集和iSAID实例分割数据集上,借助NWPU-RESISC45预训练,RFD模块相较基线方法实现了2%-7%的性能提升,充分证明了该模块在增强遥感视觉任务性能方面的显著价值。研究相关代码已开源于https://github.com/lwCVer/RFD。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
1. 浅层鲁棒特征下采样(SRFD)
SRFD模块用于替代主流骨干网络的浅层下采样层(例如,ResNet的stem层)。SRFD旨在从原始像素图像中有效地提取和保留关键特征,同时过滤掉冗余信息。
- 原理:在输入图像上应用7×7卷积,步幅为1,以强化局部特征并过滤掉不必要的信息。这个过程称为特征增强层,将通道数从3增加到1/4C。
- 下采样方法:
- 切分-拼接下采样:将特征图切分成四个矩阵(如图所示),每个矩阵通过选择相邻像素点的方式减少特征图的尺寸,同时保留原始数据特性。然后将这些切分后的特征拼接在一起,并使用1×1卷积减小通道数。
- 深度卷积下采样:应用分组卷积和深度卷积进行下采样,将特征尺寸减半,同时融合局部特征信息,以提高特征融合效果并减少计算量 。
2. 深层鲁棒特征下采样(DRFD)
DRFD模块用于处理网络中更深层次的特征图,专注于保留丰富的语义信息,以避免下采样过程中丢失关键特征。
- 原理:从SRFD改进而来,DRFD在特征提取过程的中后阶段进行处理。它采用三种下采样方法,并结合了激活函数(如GELU)来提高下采样效果:
- 深度卷积下采样(Dconv):对输入特征进行GELU激活并使用深度可分离卷积来减少特征尺寸。
- 切分-拼接下采样(Dcut):保留输入特征的原始信息。
- 最大池化下采样(Dmax):通过最大池化选择矩形区域内的最大值,保留重要的细节特征。
- 最终,将这三种下采样后的特征拼接并用1×1卷积减少通道数 。
核心代码
class SRFD(nn.Module):def __init__(self, in_channels=3, out_channels=96):super().__init__()out_c14 = int(out_channels / 4) # out_channels / 4out_c12 = int(out_channels / 2) # out_channels / 2# 7x7 convolution with stride 1 for feature reinforcement, Channels from 3 to 1/4C.self.conv_init = nn.Conv2d(in_channels, out_c14, kernel_size=7, stride=1, padding=3)# original size to 2x downsampling layerself.conv_1 = nn.Conv2d(out_c14, out_c12, kernel_size=3, stride=1, padding=1, groups=out_c14)self.conv_x1 = nn.Conv2d(out_c12, out_c12, kernel_size=3, stride=2, padding=1, groups=out_c12)self.batch_norm_x1 = nn.BatchNorm2d(out_c12)self.cut_c = Cut(out_c14, out_c12)self.fusion1 = nn.Conv2d(out_channels, out_c12, kernel_size=1, stride=1)# 2x to 4x downsampling layerself.conv_2 = nn.Conv2d(out_c12, out_channels, kernel_size=3, stride=1, padding=1, groups=out_c12)self.conv_x2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=2, padding=1, groups=out_channels)self.batch_norm_x2 = nn.BatchNorm2d(out_channels)self.max_m = nn.MaxPool2d(kernel_size=2, stride=2)self.batch_norm_m = nn.BatchNorm2d(out_channels)self.cut_r = Cut(out_c12, out_channels)self.fusion2 = nn.Conv2d(out_channels * 3, out_channels, kernel_size=1, stride=1)def forward(self, x):# 7x7 convolution with stride 1 for feature reinforcement, Channels from 3 to 1/4C.x = self.conv_init(x) # x = [B, C/4, H, W]# original size to 2x downsampling layerc = x # c = [B, C/4, H, W]# CutDc = self.cut_c(c) # c = [B, C, H/2, W/2] --> [B, C/2, H/2, W/2]# ConvDx = self.conv_1(x) # x = [B, C/4, H, W] --> [B, C/2, H/2, W/2]x = self.conv_x1(x) # x = [B, C/2, H/2, W/2]x = self.batch_norm_x1(x)# Concat + convx = torch.cat([x, c], dim=1) # x = [B, C, H/2, W/2]x = self.fusion1(x) # x = [B, C, H/2, W/2] --> [B, C/2, H/2, W/2]# 2x to 4x downsampling layerr = x # r = [B, C/2, H/2, W/2]x = self.conv_2(x) # x = [B, C/2, H/2, W/2] --> [B, C, H/2, W/2]m = x # m = [B, C, H/2, W/2]# ConvDx = self.conv_x2(x) # x = [B, C, H/4, W/4]x = self.batch_norm_x2(x)# MaxDm = self.max_m(m) # m = [B, C, H/4, W/4]m = self.batch_norm_m(m)# CutDr = self.cut_r(r) # r = [B, C, H/4, W/4]# Concat + convx = torch.cat([x, r, m], dim=1) # x = [B, C*3, H/4, W/4]x = self.fusion2(x) # x = [B, C*3, H/4, W/4] --> [B, C, H/4, W/4]return x # x = [B, C, H/4, W/4]# Deep feature downsampling
class DRFD(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.cut_c = Cut(in_channels=in_channels, out_channels=out_channels)self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, groups=in_channels)self.conv_x = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=2, padding=1, groups=out_channels)self.act_x = nn.GELU()self.batch_norm_x = nn.BatchNorm2d(out_channels)self.batch_norm_m = nn.BatchNorm2d(out_channels)self.max_m = nn.MaxPool2d(kernel_size=2, stride=2)self.fusion = nn.Conv2d(3 * out_channels, out_channels, kernel_size=1, stride=1)def forward(self, x): # input: x = [B, C, H, W]c = x # c = [B, C, H, W]x = self.conv(x) # x = [B, C, H, W] --> [B, 2C, H, W]m = x # m = [B, 2C, H, W]# CutDc = self.cut_c(c) # c = [B, C, H, W] --> [B, 2C, H/2, W/2]# ConvDx = self.conv_x(x) # x = [B, 2C, H, W] --> [B, 2C, H/2, W/2]x = self.act_x(x)x = self.batch_norm_x(x)# MaxDm = self.max_m(m) # m = [B, 2C, H/2, W/2]m = self.batch_norm_m(m)# Concat + convx = torch.cat([c, x, m], dim=1) # x = [B, 6C, H/2, W/2]x = self.fusion(x) # x = [B, 6C, H/2, W/2] --> [B, 2C, H/2, W/2]return x # x = [B, 2C, H/2, W/2]
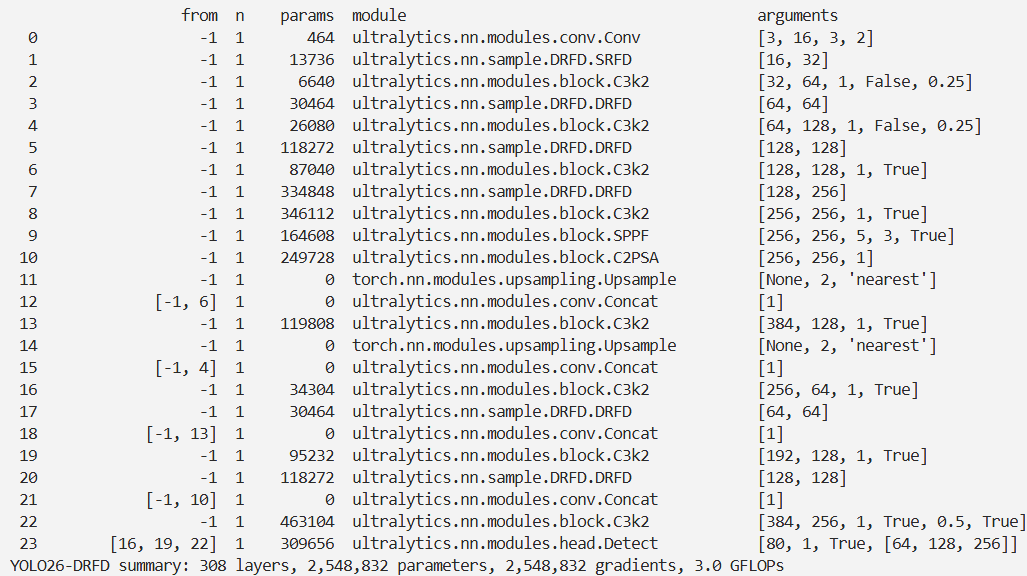
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-DRFD.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD', # optimizer='SGD',amp=False,project='runs/train',name='yolo26-DRFD',)结果