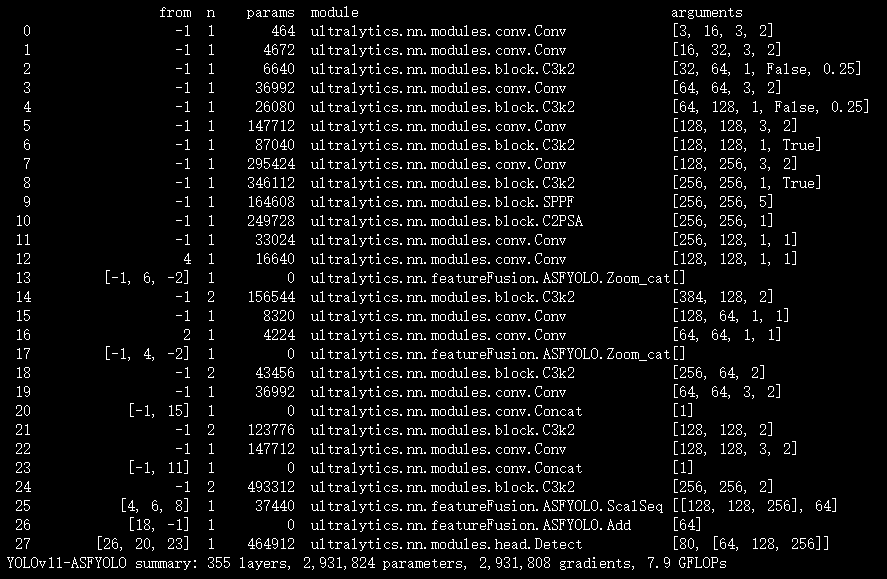
# 前言
本文介绍了基于注意力尺度序列融合的ASF - YOLO模型在YOLOv11中的结合应用。ASF - YOLO旨在实现准确快速的细胞实例分割,结合空间和尺度特征,引入SSFF模块增强多尺度信息提取能力,TFE模块融合不同尺度特征图,CPAM整合前两者以关注信息丰富通道和小物体。我们将ASF - YOLO相关模块集成进YOLOv11,替代原有的部分特征融合模块,实现更高效的特征提取与融合。实验证明,YOLOv11 - ASFYOLO在细胞实例分割任务中表现出色,展现了该模型在深度学习中的广泛应用前景。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总-CSDN博客
专栏链接: YOLOv11改进专栏
@
- 介绍
- 摘要
- 文章链接
- 基本原理
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
我们提出了一种新颖的基于注意力尺度序列融合的YOLO框架(ASF-YOLO),该框架结合了空间和尺度特征,用于准确且快速的细胞实例分割。在YOLO分割框架的基础上,我们采用了尺度序列特征融合(SSFF)模块来增强网络的多尺度信息提取能力,并使用三重特征编码器(TFE)模块来融合不同尺度的特征图以增加细节信息。我们进一步引入了通道和位置注意力机制(CPAM)来整合SSFF和TFE模块,专注于信息丰富的通道和与空间位置相关的小物体,从而提高检测和分割性能。在两个细胞数据集上的实验验证表明,所提出的ASF-YOLO模型具有显著的分割精度和速度。在2018年数据科学竞赛数据集上,它达到了0.91的box mAP,0.887的mask mAP,以及47.3 FPS的推理速度,性能优于最先进的方法。源代码可在此处获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
ASF-YOLO是一种基于You Only Look Once (YOLO)框架的创新模型,旨在实现准确和快速的细胞实例分割。该模型结合了空间和尺度特征,通过引入Scale Sequence Feature Fusion (SSFF)模块和Triple Feature Encoder (TFE)模块来增强网络的多尺度信息提取能力和融合不同尺度特征图以增加详细信息。此外,还引入了Channel and Position Attention Mechanism (CPAM)来整合SSFF和TFE模块,重点关注信息丰富的通道和与空间位置相关的小物体,以提高检测和分割性能。
ASF-YOLO的整体架构包括以下主要组件:
-
SSFF模块:用于有效融合来自多个尺度图像的全局或高级语义信息,捕获不同细胞类型的各种大小和形状的不同空间尺度。在SSFF中,从骨干网络提取的P3、P4和P5特征图被归一化到相同大小,上采样,然后堆叠在一起作为三维卷积的输入,以结合多尺度特征。
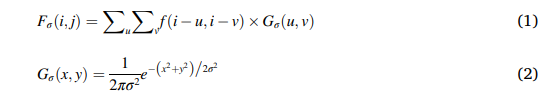
-
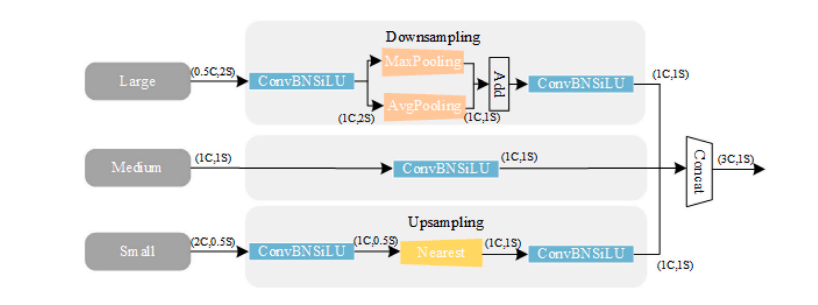
TFE模块:用于增强密集细胞的小物体检测,通过在空间维度上拼接三种不同尺寸(大、中、小)的特征,捕获有关小物体的详细信息。TFE模块的详细特征信息然后通过PANet结构集成到每个特征分支中。
-
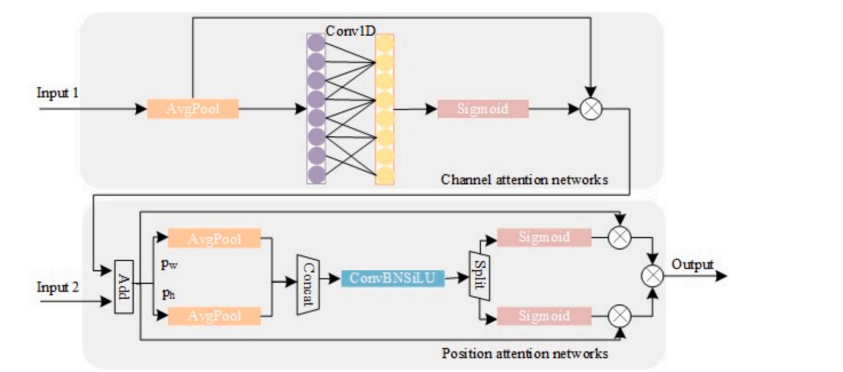
CPAM:基于CSPDarkNet骨干网络和YOLO头部,结合了Channel and Position Attention Mechanism (CPAM)。CPAM专注于信息丰富的通道和与空间位置相关的小物体,以改善检测和分割性能。
核心代码
class Zoom_cat(nn.Module):def __init__(self, in_dim):super().__init__()#self.conv_l_post_down = Conv(in_dim, 2*in_dim, 3, 1, 1)def forward(self, x):"""l,m,s表示大中小三个尺度,最终会被整合到m这个尺度上"""l, m, s = x[0], x[1], x[2]tgt_size = m.shape[2:]l = F.adaptive_max_pool2d(l, tgt_size) + F.adaptive_avg_pool2d(l, tgt_size)#l = self.conv_l_post_down(l)# m = self.conv_m(m)# s = self.conv_s_pre_up(s)s = F.interpolate(s, m.shape[2:], mode='nearest')# s = self.conv_s_post_up(s)lms = torch.cat([l, m, s], dim=1)return lms
class ScalSeq(nn.Module):def __init__(self, channel):super(ScalSeq, self).__init__()self.conv1 = Conv(512, channel,1)self.conv2 = Conv(1024, channel,1)self.conv3d = nn.Conv3d(channel,channel,kernel_size=(1,1,1))self.bn = nn.BatchNorm3d(channel)self.act = nn.LeakyReLU(0.1)self.pool_3d = nn.MaxPool3d(kernel_size=(3,1,1))def forward(self, x):p3, p4, p5 = x[0],x[1],x[2]p4_2 = self.conv1(p4)p4_2 = F.interpolate(p4_2, p3.size()[2:], mode='nearest')p5_2 = self.conv2(p5)p5_2 = F.interpolate(p5_2, p3.size()[2:], mode='nearest')p3_3d = torch.unsqueeze(p3, -3)p4_3d = torch.unsqueeze(p4_2, -3)p5_3d = torch.unsqueeze(p5_2, -3)combine = torch.cat([p3_3d,p4_3d,p5_3d],dim = 2)conv_3d = self.conv3d(combine)bn = self.bn(conv_3d)act = self.act(bn)x = self.pool_3d(act)x = torch.squeeze(x, 2)return x
class Add(nn.Module):# Concatenate a list of tensors along dimensiondef __init__(self, ch = 256):super().__init__()def forward(self, x):input1,input2 = x[0],x[1]x = input1 + input2return x
class channel_att(nn.Module):def __init__(self, channel, b=1, gamma=2):super(channel_att, self).__init__()kernel_size = int(abs((math.log(channel, 2) + b) / gamma))kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid()def forward(self, x):y = self.avg_pool(x)y = y.squeeze(-1)y = y.transpose(-1, -2)y = self.conv(y).transpose(-1, -2).unsqueeze(-1)y = self.sigmoid(y)return x * y.expand_as(x)
class local_att(nn.Module):def __init__(self, channel, reduction=16):super(local_att, self).__init__()self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel//reduction, kernel_size=1, stride=1, bias=False)self.relu = nn.ReLU()self.bn = nn.BatchNorm2d(channel//reduction)self.F_h = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)self.F_w = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)self.sigmoid_h = nn.Sigmoid()self.sigmoid_w = nn.Sigmoid()def forward(self, x):_, _, h, w = x.size()x_h = torch.mean(x, dim = 3, keepdim = True).permute(0, 1, 3, 2)x_w = torch.mean(x, dim = 2, keepdim = True)x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3))))x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h, w], 3)s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))out = x * s_h.expand_as(x) * s_w.expand_as(x)return out
class attention_model(nn.Module):# Concatenate a list of tensors along dimensiondef __init__(self, ch = 256):super().__init__()self.channel_att = channel_att(ch)self.local_att = local_att(ch)def forward(self, x):input1,input2 = x[0],x[1]input1 = self.channel_att(input1)x = input1 + input2x = self.local_att(x)return x
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-ASFYOLO.yaml')
# 修改为自己的数据集地址model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='SGD',amp=True,project='runs/train',name='ASFYOLO',)结果