书生大模型强化学习 RL 实践(Internlm2.5-1.8B swift GRPO gsm8k) - 教程
任务来源:
书生大模型强化学习 RL 实践(Internlm2.5-1.8B swift GRPO gsm8k) - 飞书云文档
任务要求:
复现本文档,RL 前和 RL 后有涨点
0、说明
本文展示了一个在 gsm8k 数据集上使用 ms-swift 框架,对 Internlm2.5-1.8B 模型进行 GRPO 微调的复现文档。
- reward funcs 使用 swift 框架自带的
accuracy和一个自定义的box_reward。 - 使用了 gsm8k 训练集的 4000/7473 条样本,训练 2 epoch。
- gsm8k 测试集 的 accuracy 从 19.86% 提升到 34.50%。
- 如有疑问,欢迎在书生班级群以及大佬群内交流。
1、原理讲解
1.1 PPO(Proximal Policy Optimization)
- 提出:OpenAI (2017)
- 核心思想:基于 Actor-Critic 架构的强化学习,通过裁剪机制稳定策略更新。
- 关键组件:
- 策略裁剪损失( LCLIPLCLIP ):限制新旧策略差异,防止过大幅度更新。
- 价值函数损失( LVFLVF ):训练 Critic 网络准确估计状态价值。
- 熵正则项( SS ):鼓励探索,避免早熟收敛。
- 优点:通用性强、训练稳定。
- 缺点:需维护多个模型(策略、价值、奖励、参考),计算开销大。
1.2 DPO(Direct Preference Optimization)
- 提出:Stanford (2023)
- 核心思想:将偏好优化转化为监督学习问题,无需显式奖励模型或 RL 训练。
- 关键公式:
LDPO=−E[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))]LDPO=−E[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
- 优点:训练简单高效,仅需 SFT 模型和偏好数据。
- 缺点:依赖高质量偏好对,对任务形式敏感。
1.3 GRPO(Group Relative Policy Optimization)
- 提出:DeepSeek (2024)
- 核心思想:在 PPO 框架下,用组内相对优势替代价值网络,适用于有明确评判标准的任务(如数学推理)。
- 流程:
- 对同一指令生成 GG 个回答;
- 用奖励打分后,计算组内均值 rˉrˉ 和标准差 σrσr ;
- 归一化优势: Ai=(ri−rˉ)/σrAi=(ri−rˉ)/σr ;
- 代入 PPO 裁剪损失更新策略。
- 优点:省去 Critic 模型,显存占用低,适合推理类任务。
- 缺点:依赖可靠奖励信号,通用性弱于 PPO。
总结对比
| 方法 | 模型数量 | 是否需要 RM | 是否需要 Critic | 适用场景 | 效率 |
|---|---|---|---|---|---|
| PPO | 4(策略、Critic、RM、参考) | 是 | 是 | 通用对齐、复杂任务 | 低 |
| DPO | 2(策略、参考) | 否 | 否 | 通用对话偏好对齐 | 高 |
| GRPO | 2(策略、参考/RM) | 是(或规则) | 否 | 数学/代码推理等 | 中高 |
2.
2.1 机器环境
- CUDA 12.6
- A100(50% 显存使用)
2.2 创建 conda 环境
如果你已经有了 ms-swift 环境,可以尝试先跑一下试试,安装缺失的包;
或者新建一个 ms-swift 环境(如下):
conda create -n ms-swift python=3.10 -y
conda activate ms-swiftpip install uv
uv pip install -U \ms-swift \torch==2.8.0 \torchvision \torchaudio \transformers==4.57.1 \modelscope>=1.23 \"peft>=0.11,<0.19" \trl==0.23.1 \deepspeed==0.17.6 \vllm==0.11.0 \lmdeploy==0.10.2 \evalscope>=1.0 \gradio==5.32.1 \math_verify==0.5.2 \-i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simplemkdir gsm8k_rl
cd ./gsm8k_rl2.3 GRPO
数据集处理
开发机的 share 目录下已经有 gsm8k 数据集,不需要我们再进行下载。
/share/datasets/gsm8k_datas/先把数据集处理成用于grpo训练的格式data_pre.py
import re
from datasets import Dataset
import os
import json
SYSTEM_PROMPT = "You are a meticulous mathematical reasoning assistant."
def parse_gsm8k_final_number(raw_answer: str) -> str:s = "" if raw_answer is None else str(raw_answer).strip()try:tail = s.split("####")[-1].strip()m = re.search(r"(-?\d+(?:\.\d+)?(?:/\d+(?:\.\d+)?)?)", tail)return m.group(1) if m else tailexcept:print("ERROR")
def to_target_schema(ex):q = (ex.get("question") or "").strip()a = ex.get("answer")ans = parse_gsm8k_final_number(a)return {"messages": [{"role": "system", "content": SYSTEM_PROMPT},{"role": "user", "content":"Please reason step by step, and put your final answer within \\boxed{}\n" + q},],"solution": f"\\boxed{{{ans}}}",}
def load_split(split: str):path = f"/share/datasets/gsm8k_datas/main/{split}-00000-of-00001.parquet"ds = Dataset.from_parquet(path)out = ds.map(to_target_schema, remove_columns=ds.column_names)return out
train_ds = load_split("train")
test_ds = load_split("test")
def save_as_jsonl(dataset, save_path):os.makedirs(os.path.dirname(save_path), exist_ok=True)with open(save_path, "w", encoding="utf-8") as f:for item in dataset:f.write(json.dumps(item, ensure_ascii=False) + "\n")
train_out = "./data/train.jsonl"
test_out = "./data/test.jsonl"
save_as_jsonl(train_ds, train_out)
save_as_jsonl(test_ds, test_out)
print(f"Saved train set to: {train_out}")
print(f"Saved test set to: {test_out}")
数据处理后格式
{"messages": [{"role": "system","content": "You are a meticulous mathematical reasoning assistant."},{"role": "user","content": "Please reason step by step, and put your final answer within \\boxed{}\nNatalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"}],"solution": "\\boxed{72}"
}Eval 评测
使用vllm进行评测,Temperature 设置为0,测试脚本eval.py
import json
import os
from typing import List, Dict, Any
from tqdm import tqdm
from vllm import LLM, SamplingParams
from datasets import Dataset
class MathAccuracy:"""数学准确率评估器,使用math_verify包进行LaTeX解析和验证,参考swift accurary reward"""def __init__(self):import importlib.utilassert importlib.util.find_spec('math_verify') is not None, ("The math_verify package is required but not installed. ""Please install it using 'pip install math_verify'.")def __call__(self, completions: List[str], solution: List[str], **kwargs) -> List[float]:from latex2sympy2_extended import NormalizationConfigfrom math_verify import LatexExtractionConfig, parse, verifyrewards = []for content, sol in zip(completions, solution):gold_parsed = parse(sol, extraction_mode='first_match',extraction_config=[LatexExtractionConfig()])if len(gold_parsed) != 0:# 解析模型生成的答案answer_parsed = parse(content,extraction_config=[LatexExtractionConfig(normalization_config=NormalizationConfig(nits=False,malformed_operators=False,basic_latex=True,boxed=True,units=True,),# 确保优先尝试匹配boxed内容boxed_match_priority=0,try_extract_without_anchor=False,)],extraction_mode='first_match',)# 如果内容与标准答案匹配,奖励为1,否则为0reward = float(verify(answer_parsed, gold_parsed))else:# 如果标准答案无法解析,跳过该样本并奖励1reward = 1.0rewards.append(reward)return rewards
def load_dataset(data_path: str) -> Dataset:if not os.path.exists(data_path):raise FileNotFoundError(f"数据集文件不存在: {data_path}")# 读取JSONL文件data = []with open(data_path, 'r', encoding='utf-8') as f:for line in f:if line.strip():data.append(json.loads(line.strip()))# 转换为Dataset对象dataset = Dataset.from_list(data)print(f"加载了 {len(dataset)} 个样本")return dataset
def format_prompt(messages: List[Dict[str, str]], tokenizer) -> str:# 检查是否有 chat templateif hasattr(tokenizer, 'chat_template') and tokenizer.chat_template is not None:try:# 使用模型的chat template格式化消息prompt = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,)except Exception as e:# 如果模板应用失败,回退到原始格式print(f"警告: 应用chat template失败 ({e}),使用备用格式")prompt = _format_fallback(messages)else:# 没有chat template,使用原始消息格式prompt = _format_fallback(messages)return prompt
def _format_fallback(messages: List[Dict[str, str]]) -> str:"""备用格式化函数,当没有chat template时使用使用标准的 <|im_start|>{role}\n{content}<|im_end|> 格式"""prompt = ""for message in messages:role = message.get("role", "user")content = message.get("content", "")prompt += f"<|im_start|>{role}\n{content}<|im_end|>\n"# 添加assistant前缀,准备生成prompt += "<|im_start|>assistant\n"return prompt
def run_evaluation(model_path: str,data_path: str,output_path: str = None,tensor_parallel_size: int = 1,temperature: float = 0.0,max_tokens: int = 2048,batch_size: int = 32,seed: int = 42,
):dataset = load_dataset(data_path)prompts = []solutions = []for item in dataset:messages = item.get("messages", [])solution = item.get("solution", "")prompts.append(messages) # 先保存原始messagessolutions.append(solution)# 初始化vLLM模型llm = LLM(model=model_path,tensor_parallel_size=tensor_parallel_size,seed=seed,dtype="half",trust_remote_code=True,)# 获取模型的tokenizer用于应用chat templatetokenizer = llm.get_tokenizer()# 格式化提示词formatted_prompts = []for messages in prompts:prompt = format_prompt(messages, tokenizer)formatted_prompts.append(prompt)# 配置采样参数sampling_params = SamplingParams(temperature=temperature,max_tokens=max_tokens,stop=["<|endoftext|>", "<|im_end|>"],)# 分批生成答案print("inferring...")all_completions = []for i in tqdm(range(0, len(formatted_prompts), batch_size), desc="生成进度"):batch_prompts = formatted_prompts[i:i + batch_size]outputs = llm.generate(batch_prompts,sampling_params=sampling_params,use_tqdm=False,)for output in outputs:# 获取生成的文本generated_text = output.outputs[0].textall_completions.append(generated_text)# 评估答案准确率print("evaluating...")evaluator = MathAccuracy()rewards = evaluator(all_completions, solutions)# 计算统计信息correct_count = sum(rewards)total_count = len(rewards)accuracy = correct_count / total_count * 100print(f"\n========== 评估结果 ==========")print(f"总样本数: {total_count}")print(f"正确数: {correct_count}")print(f"准确率: {accuracy:.2f}%")print(f"================================\n")# 保存详细结果if output_path:os.makedirs(os.path.dirname(output_path), exist_ok=True)results = {"model_path": model_path,"data_path": data_path,"total_samples": total_count,"correct_count": correct_count,"accuracy": accuracy,"individual_results": []}for i, (prompt, completion, solution, reward) in enumerate(zip(formatted_prompts, all_completions, solutions, rewards)):results["individual_results"].append({"index": i,"prompt": prompt,"completion": completion,"solution": solution,"reward": reward,})with open(output_path, 'w', encoding='utf-8') as f:json.dump(results, f, ensure_ascii=False, indent=2)print(f"详细结果已保存到: {output_path}")# 保存简洁结果(便于快速查看)summary_path = output_path.replace('.json', '_summary.json') if output_path else Noneif summary_path:summary = {"model_path": model_path,"total_samples": total_count,"correct_count": correct_count,"accuracy": accuracy,}with open(summary_path, 'w', encoding='utf-8') as f:json.dump(summary, f, ensure_ascii=False, indent=2)print(f"简洁结果已保存到: {summary_path}")return accuracy
def main():"""主函数"""import argparseparser = argparse.ArgumentParser(description="GSM8K数学问题评估")parser.add_argument("--model_path", type=str,default="/root/gsm8k_rl/output/Qwen2.5-Math-1.5B/checkpoint-2000",help="模型路径或名称")parser.add_argument("--data_path", type=str,default="/root/gsm8k_rl/data/test.jsonl",help="数据集路径")parser.add_argument("--output_path", type=str,default="/root/gsm8k_rl/eval_results.json",help="输出结果路径")parser.add_argument("--tensor_parallel_size", type=int, default=1,help="张量并行大小")parser.add_argument("--temperature", type=float, default=0.0,help="采样温度(0表示贪婪解码)")parser.add_argument("--max_tokens", type=int, default=2048,help="最大生成长度")parser.add_argument("--batch_size", type=int, default=32,help="批处理大小")parser.add_argument("--seed", type=int, default=42,help="随机种子")args = parser.parse_args()# 运行评估accuracy = run_evaluation(model_path=args.model_path,data_path=args.data_path,output_path=args.output_path,tensor_parallel_size=args.tensor_parallel_size,temperature=args.temperature,max_tokens=args.max_tokens,batch_size=args.batch_size,seed=args.seed,)return accuracy
if __name__ == "__main__":main()测评base模型
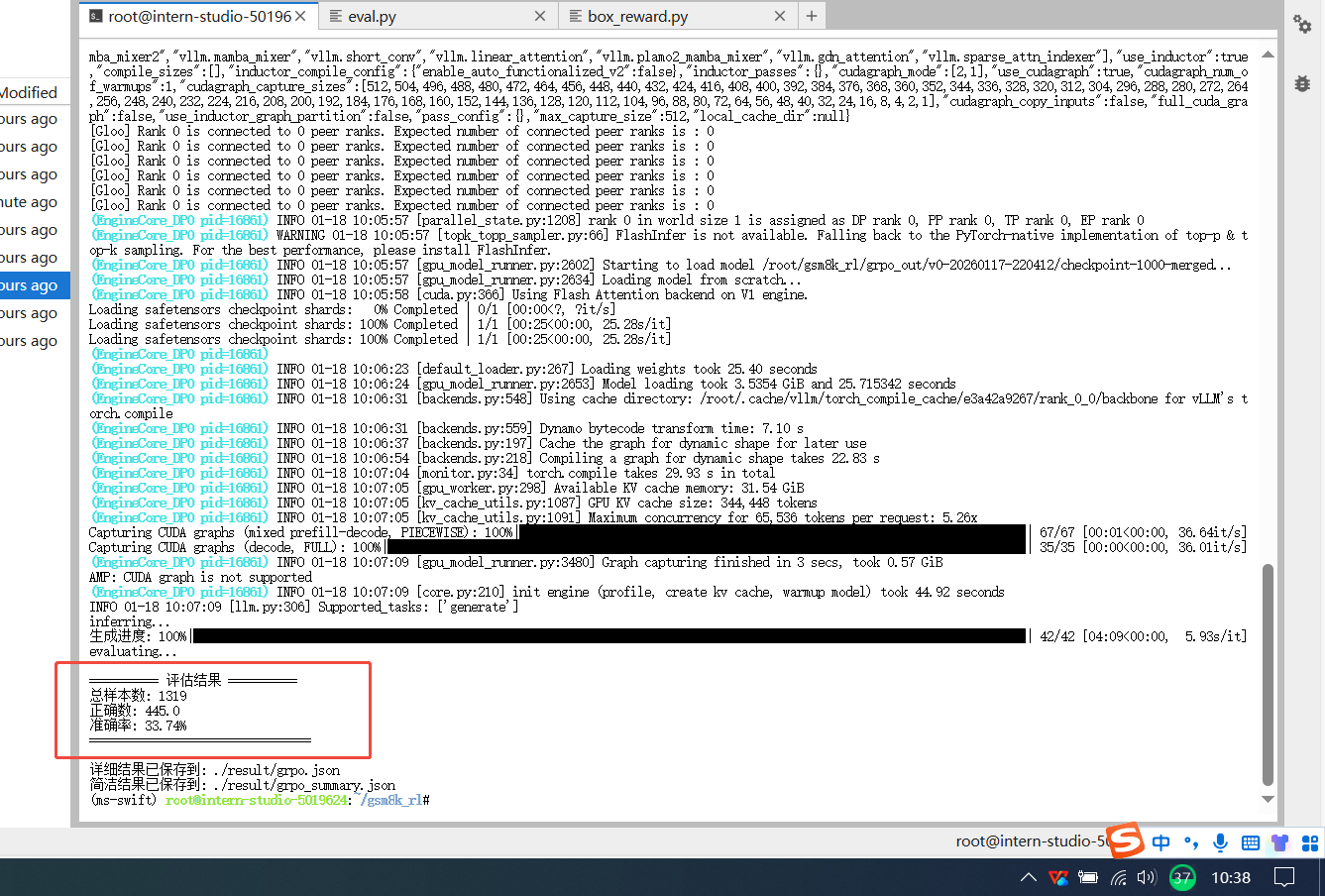
python eval.py \--model_path /share/new_models/Shanghai_AI_Laboratory/internlm2_5-1_8b \--data_path /root/gsm8k_rl/data/test.jsonl \--output_path ./result/base.json \--batch_size 32 \--max_tokens 1024测评结果如下
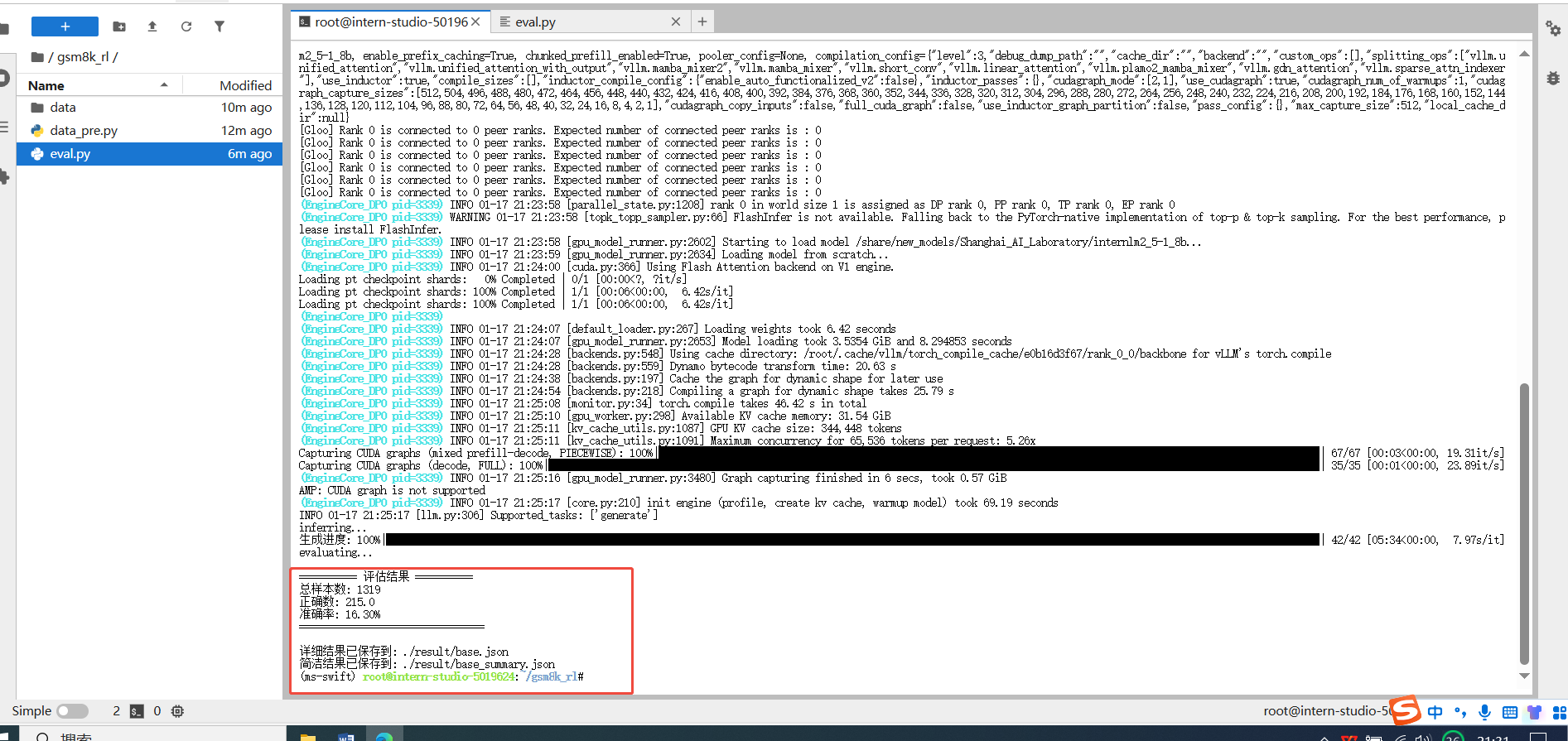
奖励函数
我们这里用了两个reward func,一个是accurary,另一个是box_reward
accurary
swift 自带,该函数将模型的生成结果与数据集中的 solution 列进行比较,计算准确率分数。如果生成结果与标准答案一致,则得分为 1.0;否则为 0.0。
box_reward
自定义的奖励,如果模型输出的slolution包裹在\boxed{}中 返回1,否则0
box_reward.py
import re
from typing import List
from swift.plugin import ORM, orms
class BoxedReward(ORM):"""Reward: check whether output contains \\boxed{...}"""def __call__(self, completions, **kwargs) -> List[float]:pattern = re.compile(r"\\boxed\s*\{.*?\}", re.DOTALL)return [1.0 if pattern.search(str(c)) else 0.0 for c in completions]
orms["box_reward"] = BoxedReward模型训练(epoch设置为1)
#!/bin/bash
set -e
LOG_DIR="./logs"
mkdir -p "$LOG_DIR"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
LOG_FILE="$LOG_DIR/[GRPO]internlm2_5-1_8b_${TIMESTAMP}.log"
export OMP_NUM_THREADS=1
export CUDA_VISIBLE_DEVICES=0
export MASTER_PORT=$((10000 + RANDOM % 50000))
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export VLLM_LOGGING_LEVEL=INFO
{echo "===== Training start: $(date) ====="echo "Log file: $LOG_FILE"echo "Using port: $MASTER_PORT"echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"echo "Enable vLLM: true"
} >> "$LOG_FILE"
nohup swift rlhf \--rlhf_type grpo \--model '/share/new_models/Shanghai_AI_Laboratory/internlm2_5-1_8b' \--dataset './data/train.jsonl#4000' \--external_plugins ./box_reward.py \--reward_funcs accuracy box_reward \--reward_weights 0.5 0.5 \--eval_steps 50 \--train_type lora \--target_modules all-linear \--max_completion_length 768 \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 4 \--learning_rate 5e-6 \--warmup_ratio 0.05 \--gradient_accumulation_steps 4 \--save_steps 50 \--save_total_limit 5 \--gradient_checkpointing_kwargs '{"use_reentrant": false}' \--logging_steps 5 \--max_length 2048 \--output_dir ./grpo_out \--dataset_num_proc 8 \--dataloader_num_workers 0 \--freeze_vit true \--log_completions true \--use_vllm true \--vllm_gpu_memory_utilization 0.50 \--vllm_max_model_len 2048 \--vllm_tensor_parallel_size 1 \--vllm_enforce_eager false \--vllm_mode colocate \> "$LOG_FILE" 2>&1 &
TRAIN_PID=$!
sleep 2
if kill -0 "$TRAIN_PID" 2>/dev/null; thenecho "Training started successfully with PID $TRAIN_PID"echo "To view logs in real-time, use:"echo "tail -f $LOG_FILE"echo ""echo "To stop training, use:"echo "kill -9 $TRAIN_PID"
elseecho "Failed to start training process"echo "Check log file for errors: $LOG_FILE"
fi注:如果代码太长运行不了,可以编辑粘贴成为run_grpo.sh文件运行
合并模型(注意换成你自己的lora adapter checkpoint路径)
swift export \--adapter "/root/gsm8k_rl/grpo_out/v0-20260117-220412/checkpoint-1000" \--merge_lora True完成模型合并
评测模型(注意换成自己merged后的模型路径)
python eval.py \--model_path /root/gsm8k_rl/grpo_out/v0-20260117-220412/checkpoint-1000-merged \--data_path /root/gsm8k_rl/data/test.jsonl \--output_path ./result/grpo.json \--batch_size 32 \--max_tokens 1024测评结果如下准确率从16%提升到34%,如果需要继续提高,可以在训练时适当增加epoch轮次