一、实时数据库与关系型资料的核心差异
关系型数据库:如 MySQL, PostgreSQL等...
核心目标:保证数据的绝对一致性(ACID)、完整性和可靠性。
设计学记录和查询这些状态变化的“单一事实来源”。它追求“结果正确”,即使牺牲一些速度。就是:数据是“状态”,数据库
典型操作:增删改查(CRUD)、复杂关联查询、事务处理。
数据库结构:实时数据库通常采用键值对、时间序列等简洁的数据结构,便于快速存取实时素材。这种结构能够高效地处理不断更新的高效变化的数据及具有时间限制的事务处理。
实时数据库:如 OSIsoft PI, Aveva eDNA, Wonderware Historian,以及新兴的时序数据库 InfluxDB, TDengine。
核心目标:确定在极短的时间内(毫秒/微秒级)完成数据的读写。
设计学:数据是随时间快速变化的“流”,数据库是捕捉和重现这个过程的“黑匣子”。它追求“速度确定性和超高吞吐”,允许在极端情况下牺牲一些非关键数据或暂时的一致性。
数据库结构:关系数据库则支持麻烦的数据结构,如表、视图、索引等,为繁琐查询和操作提供了坚实的基础。它以二维表格对数据进行存储和访问,通过关系连接来处理数据之间的关联。
典型操作:高速写入(插入)、按时间窗口查询。
二、全景对比:八大核心区别
| 特性维度 | 实时数据库 | 关系型数据库 |
|---|---|---|
| 1. 数据模型 | 时间序列模型(时间戳,测点ID,值,质量码)。结构方便、扁平。就是。数据点 | 关系模型。内容存储在二维表中,通过主外键建立复杂关联。结构严谨。 |
| 2. 优先级 | 写优化> 读优化。首要任务是毫秒不丢地吞下海量实时数据。 | 读优化> 写优化。首要任务是承受灵活、准确、复杂的查询。 |
| 3. 一致性 | 最终一致性或弱一致性。为了速度,写入和复制可能存在微小延迟。 | 强一致性(ACID)。事务保证所有操作要么全成功,要么全失败,时刻保持数据一致。 |
| 4. 性能焦点 | 超高的写入吞吐量和时间确定性。每秒处理数十万甚至上百万数据点。 | 困难的查询能力和事务处理能力。SQL功能强大,但高并发写入压力大。 |
| 5. 查询语言 | 专用API或类SQL(侧重时间窗口、插值、聚合函数)。SELECT avg(temperature) FROM sensor WHERE time > now() - 1h | 标准SQL。支持多表JOIN、子查询、复杂事务等。 |
| 6. 存储机制 | 列式存储或混合存储,高效压缩时间序列数据。自动数据旋转(新数据覆盖旧数据)。 | 行式存储或混合存储,为随机访问优化。数据通常长期保存,需手动归档。 |
| 7. 扩展性 | 天生为水平扩展(分布式集群)设计,易于应对数据量增长。 | 传统上垂直扩展(升级硬件),现代分布式。 |
| 8. 典型场景 | 监控(SCADA)、物联网、金融行情、实验数据采集。 | ERP、CRM、电商交易、财务系统、内容管理系统。 |
三、数据存储与压缩:高效与完整的区分
高效存储:追求以最小的空间和最快的速度处理数据,“性能”就是核心。
完整存储:追求不丢失任何数据,并确保其绝对准确和可追溯,核心是“可靠性”。
数据处理速度:(毫秒与秒的差距)实时数据库应用内存数据库技术,这使得它们允许在毫秒级别内响应查询和事务处理。实时数据库的读写速度能达到500000条记录/秒,远超关系数据库的3000条记录/秒。
| 维度 | 高效存储 | 完整存储 |
|---|---|---|
| 核心目标 | 性能与成本:最大化吞吐、最小化延迟、降低存储成本。 | 可靠与合规:确保资料零丢失、强一致性、满足审计追溯要求。 |
| 设计理念 | 用计算换空间,用概率换速度。接受一定的精度或冗余损失来换取效率。 | 用空间换可靠,用速度换安全。不惜成本确保数据“原汁原味”和操作可回滚。 |
| 典型技术手段 | 数据压缩(行/列/字典压缩)、编码(如Delta, Gorilla)、近似计算(如HyperLogLog)、数据分片、利用廉价的存储介质。 | 写前日志、多副本冗余、备份与归档、校验和、完整的事务日志。 |
| 主导适用场景 | 实时/时序数据库、大数据分析、监控日志、IoT数据流。 | 关系型数据库(核心交易系统)、金融账务、医疗记录、法律证据存储。 |
| 潜在代价 | 数据精度可能受损;查询可能变复杂;数据恢复可能较慢。 | 存储成本高;写入延迟可能增加;硬件资源消耗更大。 |
- 实时数据处理链的分层策略图:
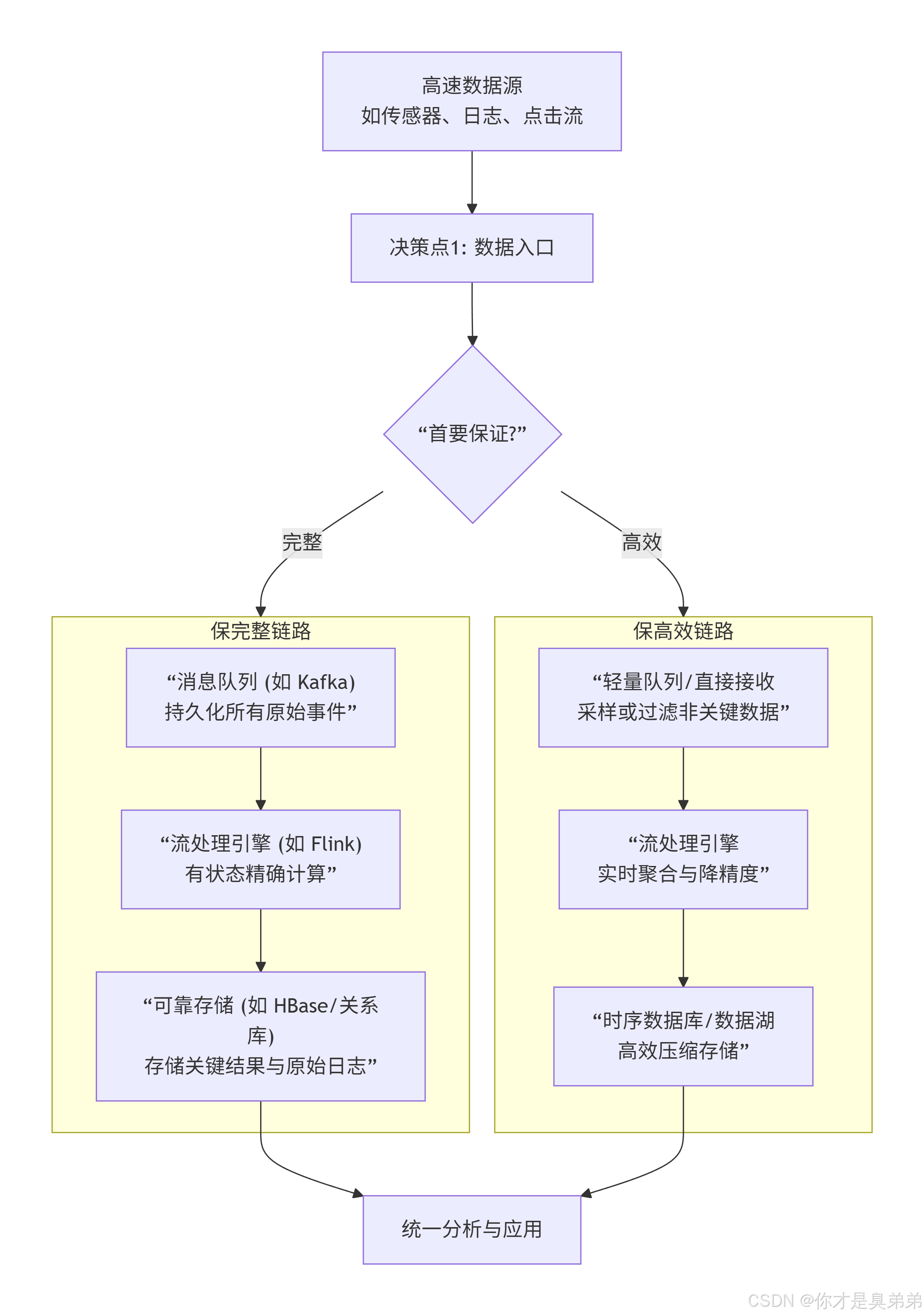
第一层:素材入口的决策(重点:完整 vs 吞吐)
侧重完整:利用帮助持久化日志的消息队列(如Apache Kafka)。它能将海量原始数据完整地、顺序地持久化一段时间,是“数据保险库”,为后续处理和故障恢复提供基础。
侧重高效:使用更轻量的接入层,或直接在队列层进行采样、过滤,仅允许关键数据进入下游,以减轻平台压力。
第二层:实时计算与处理的决策(重点:精确 vs 延迟)
侧重完整:使用支持精确一次(Exactly-Once)语义的流处理引擎(如Apache Flink)。它通过状态快照和检查点机制,保证计算结果的绝对准确,即使故障恢复也无数据丢失或重复。
侧重高效:使用近似算法(如计算百分位数、基数估计)或在内存中进行聚合,牺牲少许精度以换取极低的处理延迟。
第三层:存储与查询的决策(重点:保真 vs 成本)
侧重完整:将关键的结果数据或不可变的原始事件存入关系数据库或支持事务的存储中,用于对账、审计和精准查询。
侧重高效:将明细数据写入经深度压缩的时序数据库(如InfluxDB、TDengine)或数据湖(如 Iceberg),用于长期趋势分析和批量查询,成本低廉。
四、如何选择?
选择实时数据库(时序数据库):
数据主要是带时间戳的指标或事件。
追加。就是写入频率极高,且主要
查询大多基于时间范围,并伴随聚合(如:过去5分钟的平均值)。
需要极高的数据压缩率以节省成本。
选择关系型数据库:
数据关系复杂,需要多表关联查询。
业务逻辑依赖严格的事务保证(如金融交易)。
数据结构多变数,数据结构性强,需要复杂的查询和分析
面向“业务实体”(如用户、订单、产品)的CRUD操作。就是系统