在跨语言开发,尤其是涉及Java与C++的JNI(Java Native Interface)项目中,开发者常常会遇到一个令人困惑的现象:代码在Debug模式下运行完美,一旦切换到Release模式,却返回了诡异的NaN(Not a Number)值。这不仅仅是JNI特有的问题,更是C++编程中一个经典的“未定义行为”陷阱。本文将深入剖析这一现象背后的技术原理,从栈内存生命周期、编译器优化策略到浮点数表示,为你揭示问题的本质,并提供系统性的解决方案和最佳实践。
一、现象直击:Debug正常与Release异常的鲜明对比
问题的典型场景是这样的:一个用于坐标计算的JNI函数,在Android或桌面应用的开发阶段表现良好。然而,当项目构建为Release版本后,Java层接收到的坐标值中开始频繁出现 NaNInfinity

摘要:
在 Android NDK / JNI 开发中,经常会遇到这样一种“诡异”问题:Debug 模式下运行完全正常,而 Release 模式却出现 NaN、Infinity 甚至随机结果。
本文通过一次真实的 JNI 坐标转换案例,深入分析了该问题的根本原因——C++ 返回局部栈内存指针所导致的未定义行为(Undefined Behavior)。
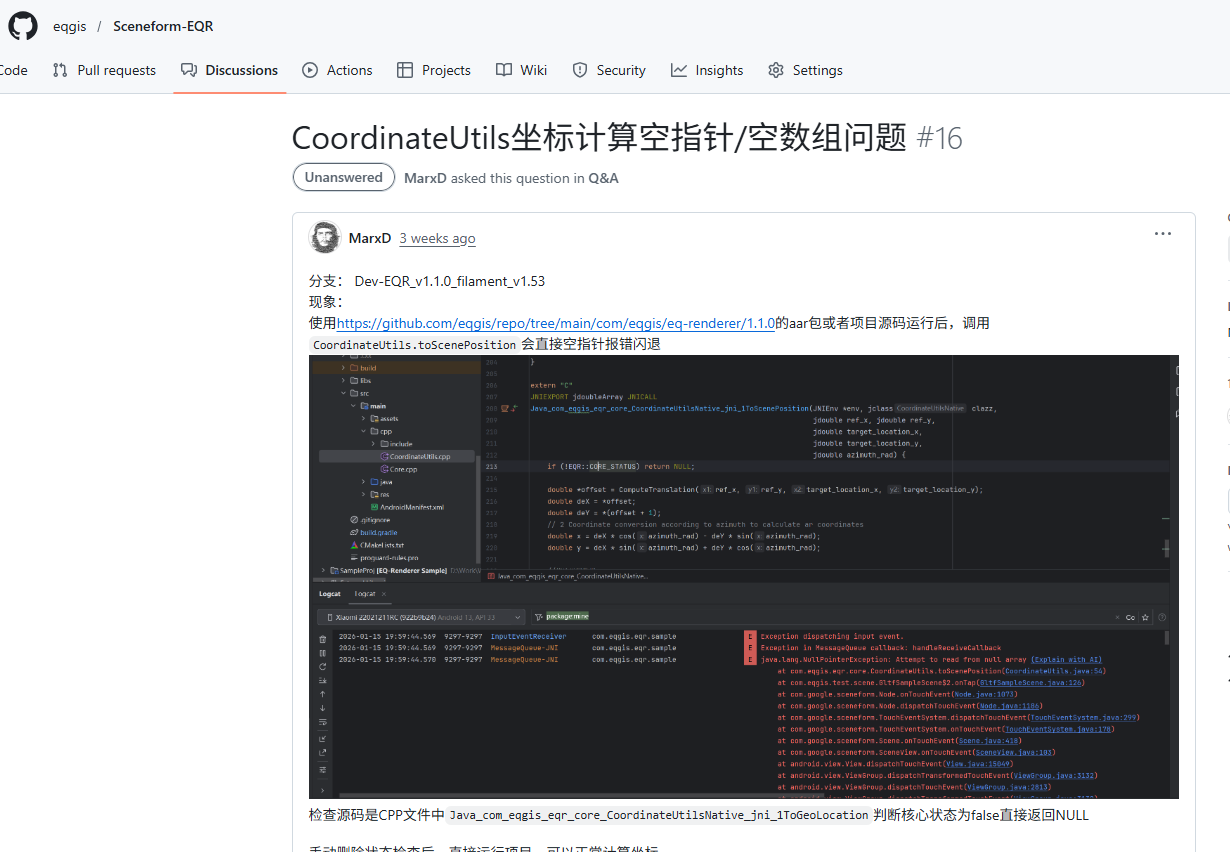
让我们先看看问题代码的核心部分。出问题的方法签名可能如下所示,它试图通过JNI返回一个指向浮点数组的指针:
JNIEXPORT void JNICALL
Java_com_eqgis_eqr_core_CoordinateUtilsNative_jni_1ToScenePosition(
JNIEnv *env, jclass clazz,
jdouble ref_x, jdouble ref_y,
jdouble target_location_x,
jdouble target_location_y,
jdouble azimuth_rad,
jdoubleArray outJNIArray)
{
double *offset = ComputeTranslation(ref_x, ref_y,
target_location_x,
target_location_y);
double deX = *offset;
double deY = *(offset + 1);
double x = deX * cos(azimuth_rad) - deY * sin(azimuth_rad);
double y = deX * sin(azimuth_rad) + deY * cos(azimuth_rad);
double outArray[] = {x, y};
env->SetDoubleArrayRegion(outJNIArray, 0, 2, outArray);
}在Debug构建下,一切似乎都正常:

但在Release构建下,灾难发生了:

二、根源剖析:一个隐藏的栈内存指针返回陷阱
问题的根源通常锁定在一个“看起来完全正确”的辅助函数上。这个函数负责计算并返回一个指向结果的指针。
double * ComputeTranslation(double x1, double y1,
double x2, double y2)
{
double res[2] = {0, 0};
...
res[0] = flagX * x;
res[1] = flagY * y;
return res;
}⚠️ 致命错误就隐藏在这里:函数返回了局部变量 resres
double res[2];当函数 ComputeTranslationres
这是典型的 Undefined Behavior(未定义行为)
这意味着,后续对这块内存的读取行为是完全不可预测的,属于C++标准定义的“未定义行为(Undefined Behavior, UB)”。
[AFFILIATE_SLOT_1]三、编译器优化的“魔术”:为何Debug与Release结果不同?
这是最让开发者困惑的部分。要解开谜团,需要理解两种构建模式下的编译器行为差异。
- Debug模式:编译器优化选项(如
-O0)被关闭或降至最低。栈内存的管理相对“保守”和“缓慢”,局部变量占用的内存在函数返回后可能不会立即被覆盖。因此,非法指针偶尔还能“侥幸”读到原先的数据,给人一种程序正确的假象。 - Release模式:编译器开启了高级优化(如
-O2 / -O3*offset
“你返回这个指针是非法的,那我随便优化”
那么,为什么随机值常常表现为NaN呢?在IEEE 754浮点数标准中,特定的位模式(例如指数位全为1,尾数位非零)被定义为NaN。当未初始化的内存或寄存器残留值恰好符合这个模式时,读取到的浮点数就是 NaN / InfNaN + x = NaNsin(NaN) = NaN
本文为以下问题的解决记录。由于问题较为典型,故梳理备忘。
https://github.com/eqgis/Sceneform-EQR/discussions/16
四、正解与最佳实践:安全的数据返回策略
解决这个问题的核心在于避免返回指向局部栈内存的指针。正确的做法是使用值语义或动态内存。
方案一:使用结构体/对象值返回(推荐)
这是最安全、最清晰的方式。定义一个结构体来封装需要返回的数据。
struct Vec2 {
double x;
double y;
};
Vec2 ComputeTranslation(double x1, double y1,
double x2, double y2)
{
Vec2 res{0.0, 0.0};
...
res.x = flagX * x;
res.y = flagY * y;
return res;
}调用方直接接收一个结构体副本,内存管理清晰无误:
Vec2 offset = ComputeTranslation(...);
double deX = offset.x;
double deY = offset.y;方案二:通过指针参数输出
由调用者分配内存(可以在栈上,也可以在堆上),并将指针传入函数进行填充。这是C语言中常见的模式。
方案三:返回动态分配的内存(需谨慎管理生命周期)
使用 new 或 malloc 在堆上分配内存并返回。但务必在JNI的Java侧或合适的时机调用对应的释放函数(delete 或 free),否则会导致内存泄漏。对于JNI,这通常意味着需要在Native侧提供专门的释放函数。
[AFFILIATE_SLOT_2]未定义行为从来不是“偶尔才错”,而是“早晚会炸”。
五、系统性防御:如何避免类似内存陷阱
这类问题并非JNI独有,在纯C++、乃至通过FFI与其他语言(如Rust、Go、Python的C扩展)交互时都会遇到。以下是一些普适性的防御策略:
- 黄金法则:永远不要返回局部自动变量的地址或引用。这是代码审查时需要重点检查的条目。
- 优先选择值语义:对于小型数据结构,直接返回值副本。现代编译器的返回值优化(RVO/NRVO)效率很高,不必担心性能损耗。
- 善用智能指针和容器:在C++中,使用
std::vector、std::array或std::unique_ptr来管理数据生命周期,可以大幅减少手动内存管理错误。 - 理解不同语言的内存模型:Java、Go、Python等语言有垃圾回收器,而C++、Rust是手动/半自动管理。在边界处传递数据时,必须明确所有权和生命周期。例如,从Go调用C函数时,同样需要注意C函数不能返回指向Go栈内存的指针。
- 不要依赖Debug模式的结果:Debug模式只是一个调试辅助工具,其行为不能证明代码的正确性。它只能说明“在当前未优化的环境下,未定义行为恰好没有表现出问题”。
“在当前编译条件下恰好没炸”
下面是一些错误和正确做法的代码对比:
return &localVar;
return localArray;struct / std::array / std::pair六、总结与延伸思考
| 问题 | 结论 |
|---|---|
| Debug 正常 | 不代表代码正确 |
| Release 出 NaN | 典型 UB 表现 |
| 根因 | 返回栈内存指针 |
| JNI 是否有问题 | 没有 |
| 正确解法 | 返回结构体 / 值语义 |
本次NaN陷阱的排查,深刻地揭示了底层编程中的一个关键原则:未定义行为是程序中最危险的“定时炸弹”。它在不同编译器、不同优化等级、不同运行环境下可能表现出截然不同的症状,使得问题难以复现和定位。
C++ 中,最危险的 Bug 往往不是“复杂算法”,
而是“看起来理所当然的代码”。
作为开发者,当遇到Debug与Release行为不一致的诡异问题时,应第一时间将排查重点指向“未定义行为”。熟练使用如AddressSanitizer(ASan)、UndefinedBehaviorSanitizer(UBSan)等工具,可以在问题发生前就将其捕获。同时,建立对内存生命周期和编译器优化行为的深刻理解,是写出健壮、跨平台、跨构建模式代码的基石。这不仅适用于C++和JNI,对于任何涉及系统级编程或语言边界交互的场景(如JavaScript的WebAssembly模块、TypeScript的Node.js本地插件)都具有重要的借鉴意义。