深入解析:【2B篇】阿里通义 Qwen3-VL 新增 2B、32B 两个模型尺寸,手机也能轻松运行
认识Qwen3-VL——通义千问系列迄今为止最强大的视觉语言模型。
这一代实现了全方位升级:更卓越的文本理解与生成、更深度的视觉感知与推理、更长的上下文处理能力、增强的空间与视频动态理解,以及更强大的智能体交互功能。
提供从边缘设备到云端均可扩展的Dense和MoE架构,并配备指令微调版与推理增强的Thinking版本,支持灵活按需部署。
核心升级:
视觉智能体:可操作PC/移动端图形界面——识别元素、理解功能、调用工具、完成任务。
视觉编程增强:根据图像/视频生成Draw.io图表/HTML/CSS/JS代码。
高级空间感知:判断物体位置、视角与遮挡关系,提供更强的2D空间定位能力,并支持3D空间推理与具身智能。
长上下文与视频理解:原生支持256K上下文窗口,可扩展至1M;完整记忆并二级索引处理书籍和数小时长视频内容。
增强多模态推理:擅长STEM/数学领域——因果分析与基于证据的逻辑应答。
升级版视觉识别:经过更广域、更高质量的预训练,实现"万物识别"——名人、动漫、商品、地标、动植物等。
扩展OCR能力:支持32种语言(原19种);在弱光、模糊、倾斜场景下表现稳健;对生僻字/古籍术语识别更优;提升长文档结构解析能力。
媲美纯文本大模型的理解力:文本-视觉无缝融合,实现无损统一理解。
模型架构更新:

交错式多维鲁棒位置嵌入(Interleaved-MRoPE):通过鲁棒的位置编码在时间、宽度和高度维度实现全频段分配,从而增强长时视频推理能力。
深度堆叠(DeepStack):融合多层级视觉Transformer特征,捕捉细粒度细节并锐化图像-文本对齐。
文本-时间戳对齐:突破T-RoPE限制,实现基于精确时间戳的事件定位,强化视频时序建模能力。
模型性能
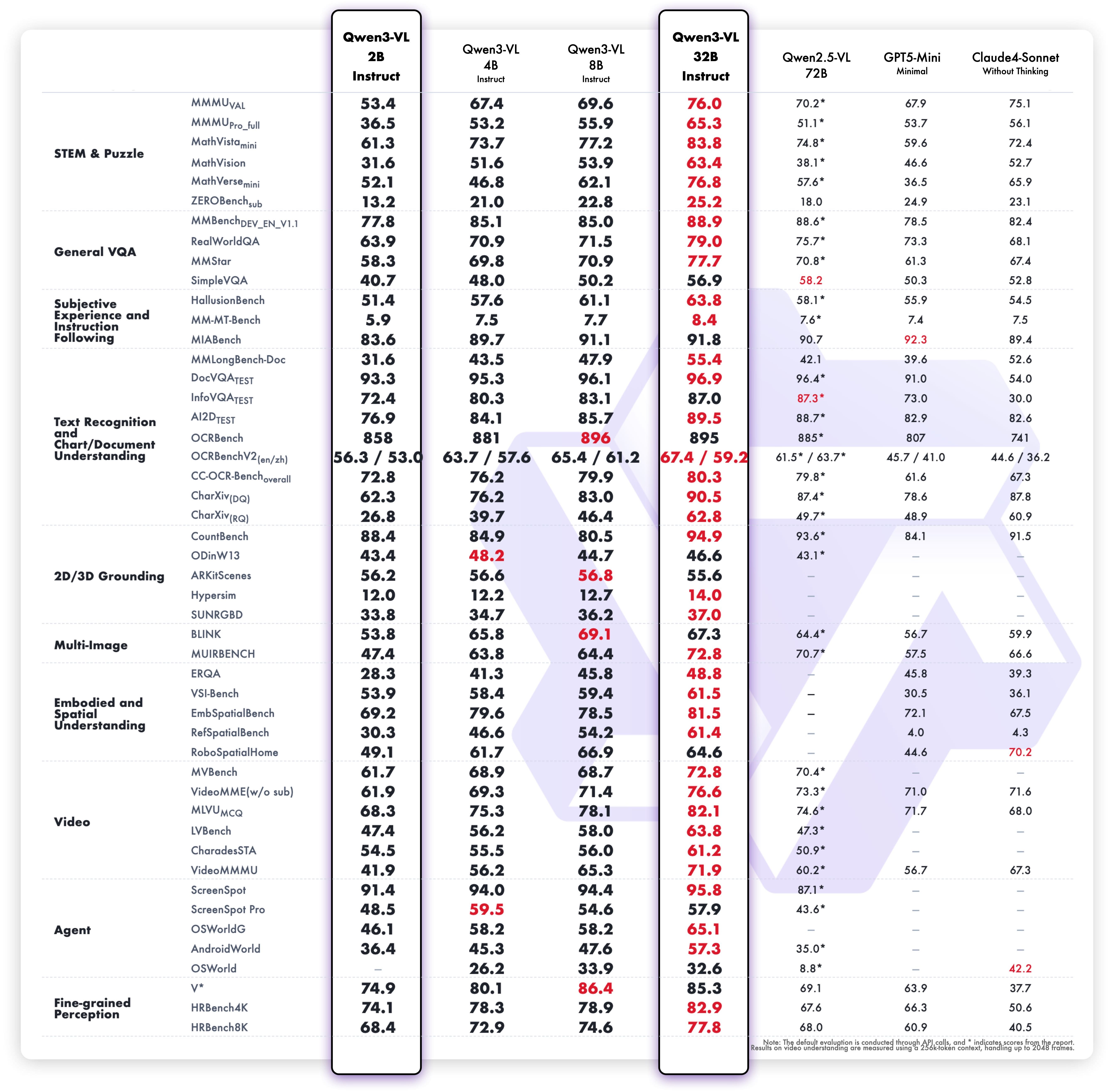
Qwen3-VL-2B-Instruct
多模态性能
纯文本表现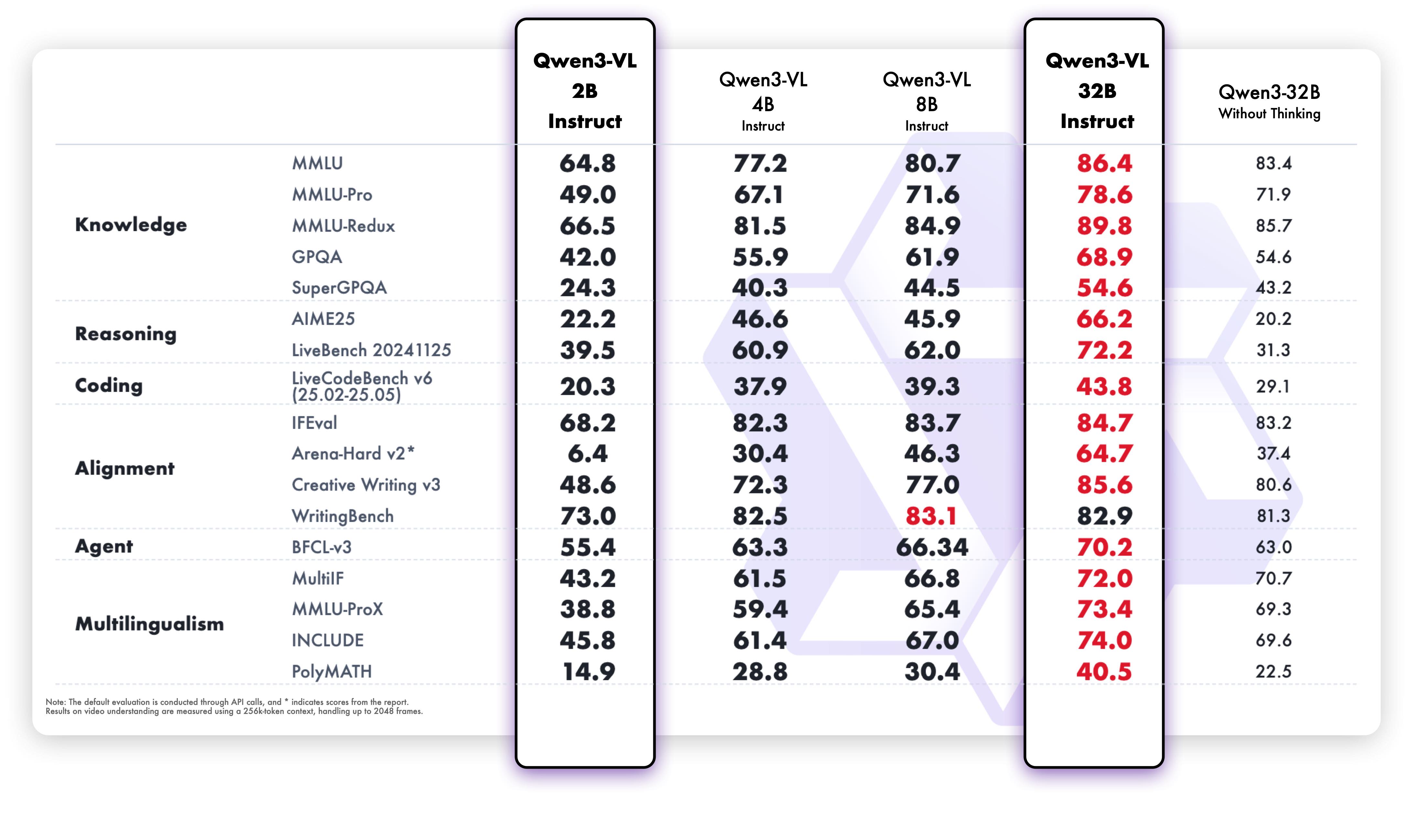
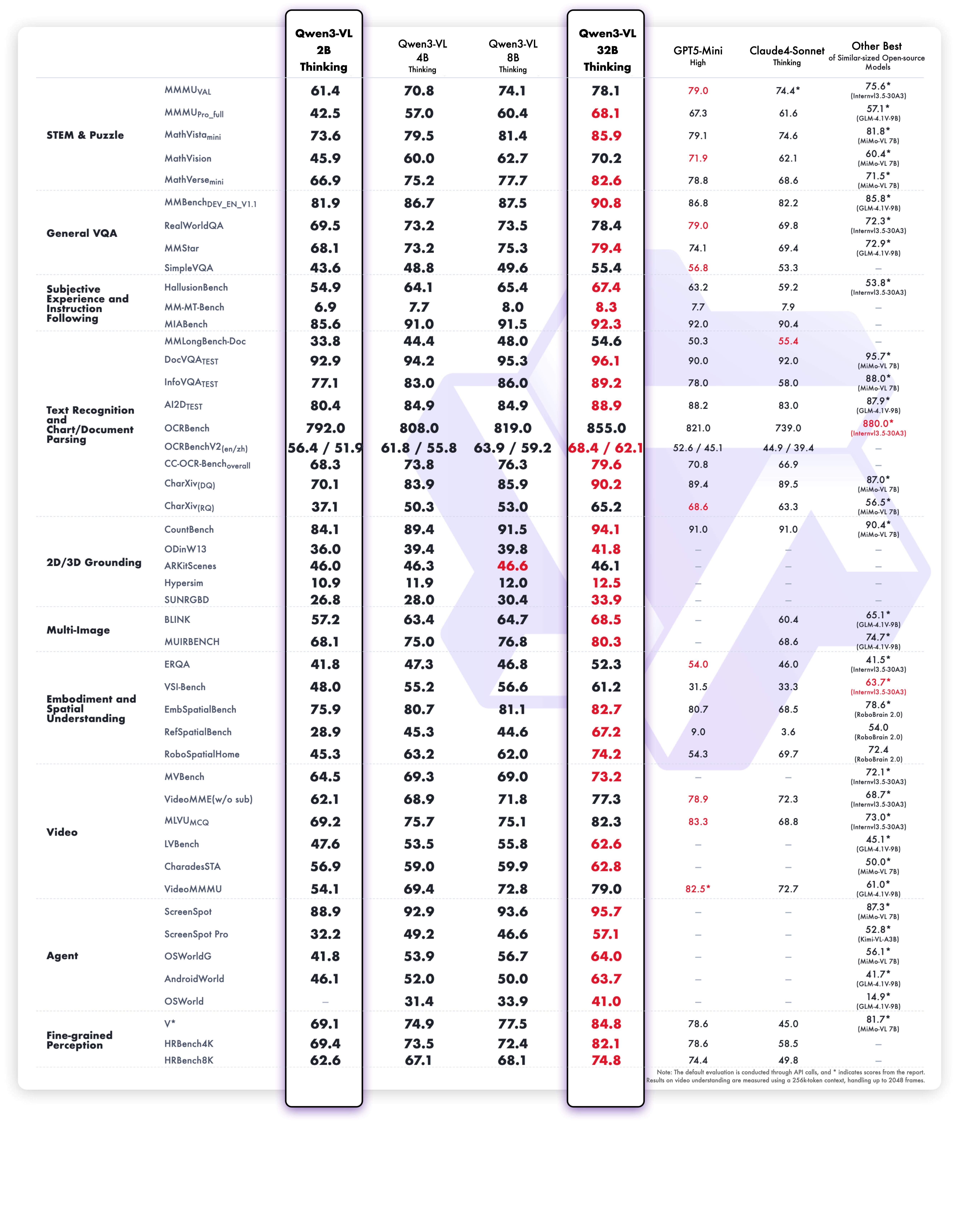
Qwen3-VL-2B-Thinking
多模态性能
纯文本性能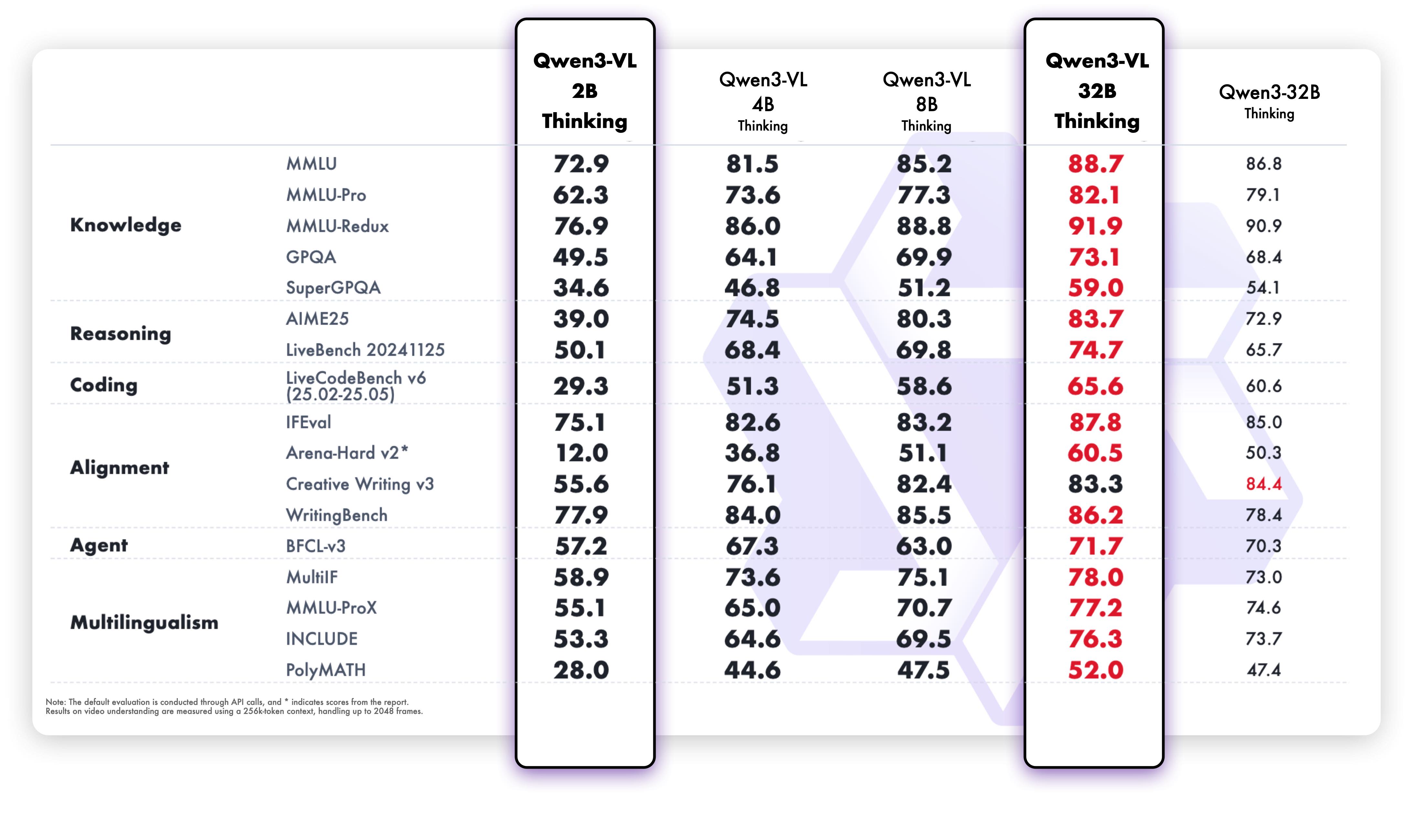
快速入门
以下提供简单示例,展示如何使用Qwen3-VL模型配合魔搭社区和Transformers库。
Qwen3-VL的代码已集成至最新版Hugging Face transformers库,建议您通过以下命令从源码安装:
pip install git+https://github.com/huggingface/transformers
# pip install transformers==4.57.0 # currently, V4.57.0 is not released使用 Transformers 进行聊天
以下代码片段展示了如何使用 transformers 与聊天模型交互:
Qwen3-VL-2B-Instruct
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
# default: Load the model on the available device(s)
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-2B-Instruct", dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen3VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen3-VL-2B-Instruct",
# dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-2B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)Qwen3-VL-2B-Thinking
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
# default: Load the model on the available device(s)
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-2B-Thinking", dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen3VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen3-VL-2B-Thinking",
# dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-2B-Thinking")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)生成超参数
VL
export greedy='false'
export top_p=0.8
export top_k=20
export temperature=0.7
export repetition_penalty=1.0
export presence_penalty=1.5
export out_seq_length=16384Text
export greedy='false'
export top_p=1.0
export top_k=40
export repetition_penalty=1.0
export presence_penalty=2.0
export temperature=1.0
export out_seq_length=32768