# 前言
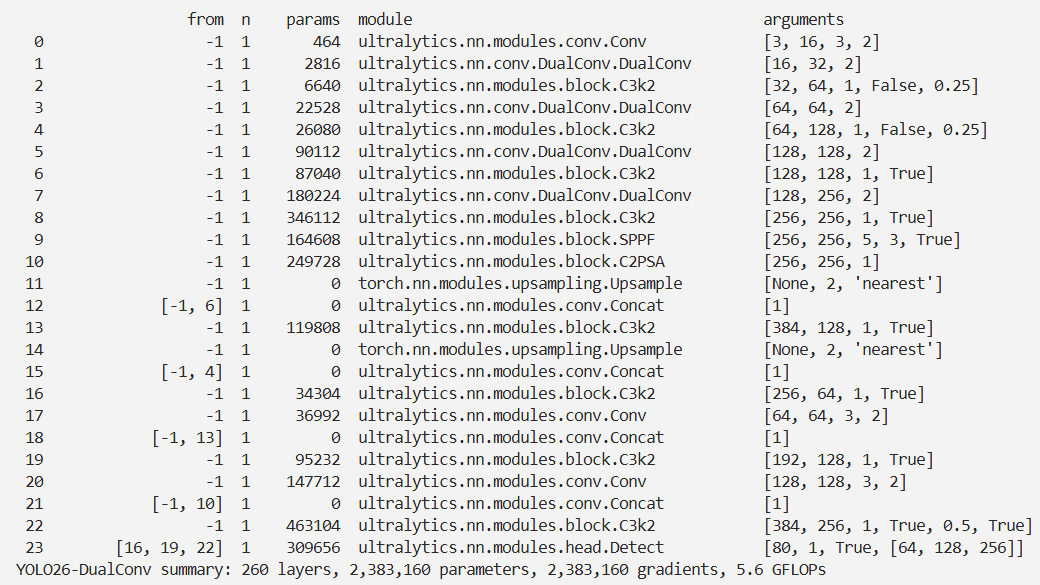
本文介绍了一种用于构建轻量级深度神经网络的双卷积核(DualConv)方法及其在YOLO26中的结合。DualConv结合$3 \times 3$和$1 \times 1$卷积核同时处理输入特征图通道,利用组卷积技术排列卷积滤波器。$3 \times 3$卷积核提取细粒度特征,$1 \times 1$卷积核压缩参数,组卷积减少计算量。该方法可应用于多种CNN模型。我们将DualConv集成进YOLO26,实验表明它显著减少了计算成本和参数数量,提升了YOLO-V3检测速度和准确性,在部分数据集上还提高了分类准确率。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 介绍
- 摘要
- 文章链接
- 基本原理
- 双重卷积核结构 :
- 组卷积技术 :
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
CNN架构通常对内存和计算资源的要求较高,这使得它们在硬件资源有限的嵌入式系统中难以实现。我们提出了一种用于构建轻量级深度神经网络的双卷积核(DualConv)方法。DualConv结合了$3 \times 3$和$1 \times 1$的卷积核,同时处理相同的输入特征图通道,并利用组卷积技术高效地排列卷积滤波器。DualConv可以应用于任何CNN模型,例如用于图像分类的VGG-16和ResNet-50,用于目标检测的YOLO和R-CNN,或用于语义分割的FCN。在本文中,我们广泛测试了DualConv在分类任务中的表现,因为这些网络架构构成了许多其他任务的骨干。我们还测试了DualConv在YOLO-V3上的图像检测性能。实验结果表明,结合我们的结构创新,DualConv显著减少了深度神经网络的计算成本和参数数量,同时在某些情况下,令人惊讶地实现了比原始模型稍高的准确性。我们使用DualConv进一步减少了轻量级MobileNetV2的参数数量54%,在CIFAR-100数据集上仅下降了0.68%的准确性。当参数数量不是问题时,DualConv在相同数据集上将MobileNetV1的准确性提高了4.11%。此外,DualConv显著提升了YOLO-V3的目标检测速度,并在PASCAL VOC数据集上将其准确性提高了4.4%。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
DualConv是一种创新的深度神经网络技术,旨在构建轻量级的深度神经网络。
双重卷积核结构 :
DualConv结合了3x3和1x1卷积核,同时处理相同的输入特征图通道。通过这种结合,DualConv能够在保持准确性的同时降低网络的计算成本和参数数量。
-
3x3卷积核的作用:
- 3x3卷积核通常用于捕获局部特征和空间信息,有助于提取输入特征图的细粒度特征。
- 在双重卷积核结构中,3x3卷积核负责处理输入特征图的通道维度,从而实现对特征的深度提取和表征。
-
1x1卷积核的作用:
- 1x1卷积核通常用于减少特征图的通道数量,降低计算成本和参数数量,同时有助于特征的融合和压缩。
- 在双重卷积核结构中,1x1卷积核与3x3卷积核结合使用,可以在保持准确性的同时实现参数的有效压缩和计算的高效性。
-
同时处理的优势:
- 双重卷积核结构使得3x3和1x1卷积核能够同时处理相同的输入特征图通道,从而加快计算速度,提高网络的效率和性能。
- 同时处理不同类型的卷积核有助于网络在不同尺度上捕获特征信息,并有效地融合这些信息,提高网络的表征能力和泛化能力。
-
参数减少与性能提升:
- 双重卷积核结构通过结合3x3和1x1卷积核,实现了在轻量级深度神经网络中提高准确性、降低计算成本和参数数量的目标。
- 这种结构的设计使得网络在保持高准确性的同时,具有更高的计算效率和更少的参数量,适合在资源受限的环境中部署和应用。
总的来说,双重卷积核结构的技术原理在于充分利用3x3和1x1卷积核的优势,同时处理输入特征图通道,实现了在深度神经网络中提高效率、准确性和泛化能力的目标。
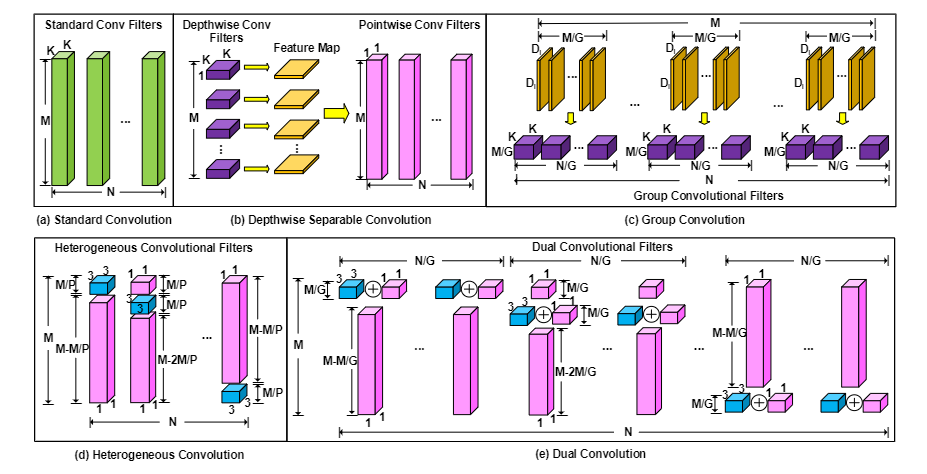
组卷积技术 :
DualConv利用组卷积技术有效地排列卷积滤波器,进一步提高了网络的效率。组卷积将输入特征图分成多个组,并对每个组应用卷积操作,从而减少了计算量。
组卷积技术是一种卷积神经网络中常用的技术
-
分组卷积的概念:
- 在传统的卷积操作中,所有的输入通道都会与所有的输出通道进行卷积操作。而在组卷积中,将输入通道和输出通道分成多个组,每个组内的通道之间进行卷积操作,最后将各组的输出进行拼接。
- 通过分组卷积,可以减少参数数量和计算量,提高计算效率,尤其适用于深度神经网络中参数较多的情况。
-
技术原理:
- 在组卷积中,首先将输入特征图分成多个组,每个组包含一定数量的通道。
- 对每个组内的通道进行卷积操作,得到各自的输出特征图。
- 最后将各组的输出特征图进行拼接,得到最终的输出特征图。
- 通过这种方式,实现了对输入特征图的分组处理,减少了参数数量和计算量,同时保持了网络的表征能力。
-
优势:
- 减少参数数量:组卷积可以将参数分组,每个组内共享参数,从而减少整体的参数数量。
- 提高计算效率:由于参数数量减少,计算量也相应减少,可以加快网络的训练和推理速度。
- 改善特征表征:组卷积可以帮助网络更好地学习特征表示,提高网络的泛化能力和性能。
-
应用:
- 组卷积技术广泛应用于各种深度神经网络结构中,如ShuffleNet等轻量级网络结构中,以提高网络的效率和性能。
- 在一些需要减少参数数量和计算量的场景下,组卷积技术也可以发挥重要作用,如移动端和嵌入式设备上的模型部署等。
核心代码
import torch.nn as nnclass DualConv(nn.Module):def __init__(self, in_channels, out_channels, stride, g=2):"""初始化 DualConv 类。:param in_channels: 输入通道数:param out_channels: 输出通道数:param stride: 卷积步幅:param g: 用于 DualConv 的分组卷积组数"""super(DualConv, self).__init__()# 分组卷积self.gc = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, groups=g, bias=False)# 逐点卷积self.pwc = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)def forward(self, input_data):"""定义 DualConv 如何处理输入图像或输入特征图。:param input_data: 输入图像或输入特征图:return: 返回输出特征图"""# 同时进行分组卷积和逐点卷积,然后将结果相加return self.gc(input_data) + self.pwc(input_data)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-DualConv.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD', # optimizer='SGD',amp=False,project='runs/train',name='yolo26-DualConv',)结果