前言
本文介绍了实时检测Transformer(RT-DETR)及其核心AIFI模块在YOLO26中的结合应用。RT-DETR旨在解决YOLO速度和准确性受NMS负面影响、DETRs计算成本高的问题,通过设计高效混合编码器和解码器层数调整来提升性能。AIFI作为Transformer编码器层,通过构建2D正弦 - 余弦位置嵌入处理多尺度特征。我们将AIFI集成进YOLO26,实验表明,改进后的模型在COCO数据集上的速度和准确性超越了先进的YOLO模型,展现出良好的性能表现。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 前言
- 介绍
- 摘要
- 文章链接
- 基本原理
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
YOLO系列因其在速度和准确性之间的合理权衡,成为了实时目标检测中最受欢迎的框架。然而,我们观察到YOLO的速度和准确性受NMS(非极大值抑制)的负面影响。最近,基于Transformer的端到端检测器(DETRs)提供了一种消除NMS的替代方案,但其高计算成本限制了其实用性,并阻碍了其完全利用排除NMS的优势。在本文中,我们提出了实时检测Transformer(RT-DETR),据我们所知,这是第一个解决上述困境的实时端到端目标检测器。我们借鉴先进的DETR,分两步构建RT-DETR:首先,我们专注于在提高速度的同时保持准确性,然后在保持速度的同时提高准确性。具体而言,我们设计了一种高效的混合编码器,通过解耦内尺度交互和跨尺度融合来快速处理多尺度特征,从而提高速度。然后,我们提出了不确定性最小化查询选择,以向解码器提供高质量的初始查询,从而提高准确性。此外,RT-DETR通过调整解码器层数支持灵活的速度调节,以适应各种场景,而无需重新训练。我们的RT-DETR-R50/R101在COCO数据集上分别达到了53.1%和54.3%的AP,并在T4 GPU上达到了108 FPS和74 FPS,超越了之前先进的YOLOs在速度和准确性上的表现。此外,RT-DETR-R50在准确性上比DINO-R50高2.2% AP,且FPS高约21倍。经过Objects365的预训练后,RT-DETR-R50/R101分别达到了55.3%和56.2%的AP。项目页面:https://zhao-yian.github.io/RTDETR。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
核心代码
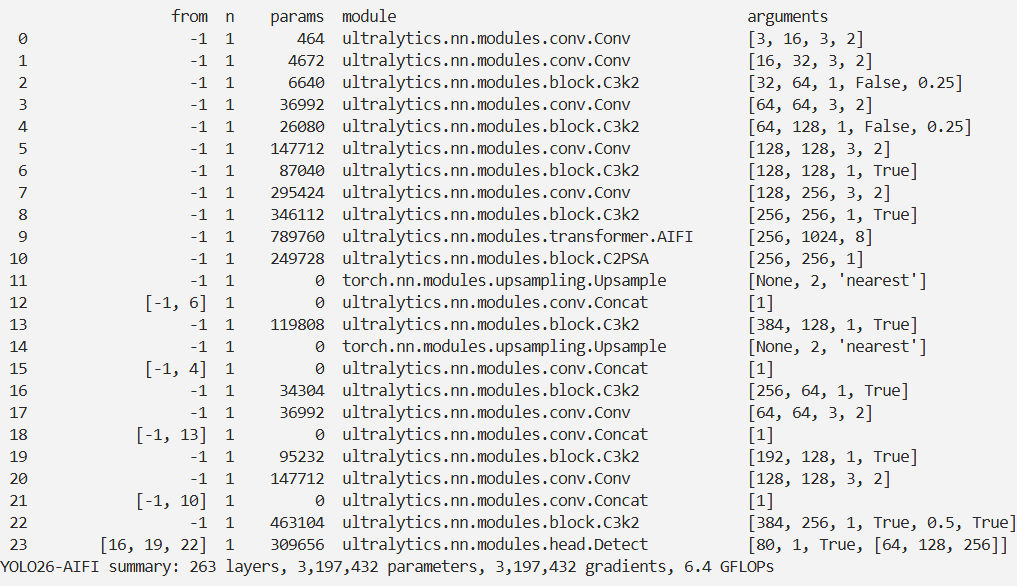
class AIFI(TransformerEncoderLayer):"""Defines the AIFI transformer layer."""def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):"""Initialize the AIFI instance with specified parameters."""super().__init__(c1, cm, num_heads, dropout, act, normalize_before)def forward(self, x):"""Forward pass for the AIFI transformer layer."""c, h, w = x.shape[1:]pos_embed = self.build_2d_sincos_position_embedding(w, h, c)# Flatten [B, C, H, W] to [B, HxW, C]x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()@staticmethoddef build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):"""Builds 2D sine-cosine position embedding."""grid_w = torch.arange(int(w), dtype=torch.float32)grid_h = torch.arange(int(h), dtype=torch.float32)grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing="ij")assert embed_dim % 4 == 0, "Embed dimension must be divisible by 4 for 2D sin-cos position embedding"pos_dim = embed_dim // 4omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dimomega = 1.0 / (temperature**omega)out_w = grid_w.flatten()[..., None] @ omega[None]out_h = grid_h.flatten()[..., None] @ omega[None]return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-AIFI.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD', # optimizer='SGD',amp=False,project='runs/train',name='yolo26-AIFI',)结果