前言
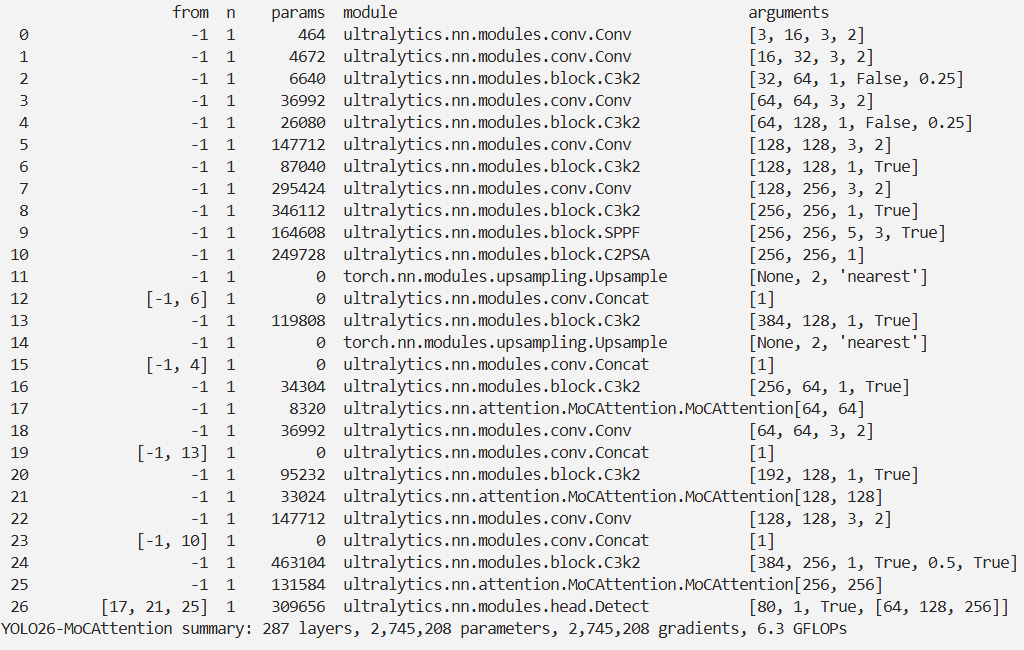
本文介绍了将蒙特卡洛注意力(MCAttn)模块与YOLO26相结合的方法。MCAttn是尺度可变注意力网络(SvANet)的核心创新模块,模拟蒙特卡洛随机采样逻辑,从多尺度池化张量中随机选特征,按关联概率加权融合生成注意力图,兼顾局部细节与全局上下文。我们将MCAttn模块引入YOLO26,对相关代码进行修改和注册,并配置了YOLO26 - MoCAttention.yaml文件。实验脚本显示,该结合方式应用于目标检测任务。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@
- 前言
- 介绍
- 摘要
- 文章链接
- 基本原理
- null
- 核心原理与数学表达
- 1. 核心思想
- 2. 数学公式
- 工作流程与结构细节
- 1. 模块定位
- 2. 具体步骤
- 关键优势
- 1. 跨尺度特征捕捉
- 2. 泛化性强
- 3. 轻量化设计
- 核心代码
- 实验
- 脚本
- 结果
介绍

摘要
摘要——早期检测与准确诊断能够预测恶性疾病转化风险,进而提高有效治疗的概率。具有微小感染区域的轻微症状是不祥预警,在疾病早期诊断中至关重要。卷积神经网络(CNNs)等深度学习算法已被用于自然目标或医疗目标分割,取得了良好效果。然而,由于CNNs中卷积和池化操作会导致信息丢失与压缩伪影,图像中小面积医疗目标的分析仍面临挑战。随着网络深度增加,这些丢失和缺陷愈发显著,对小医疗目标的影响尤为突出。为应对这些挑战,本文提出一种新型尺度可变注意力网络(SvANet),用于医学图像中小尺度目标的精准分割。该网络整合了蒙特卡洛注意力(Monte Carlo attention)、尺度可变注意力(scale-variant attention)与视觉Transformer(vision transformer),通过融合跨尺度特征、减轻压缩伪影,提升小医疗目标的辨识度。定量实验结果表明,SvANet性能优异:在KiTS23、ISIC 2018、ATLAS、PolypGen、TissueNet、FIVES和SpermHealth数据集上,对占图像面积不足1%的肾肿瘤、皮肤病变、肝肿瘤、息肉、手术切除细胞、视网膜血管和精子进行分割时,平均Dice系数分别达到96.12%、96.11%、89.79%、84.15%、80.25%、73.05%和72.58%。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
MCAttn(Monte Carlo Attention)是SvANet的核心创新模块之一,专为解决小医疗目标分割中“跨尺度特征捕捉不足”和“细节信息丢失”问题设计,通过蒙特卡洛随机采样机制生成多尺度注意力图,同时兼顾局部细节与全局上下文,显著提升小/超小医疗目标的辨识度。
核心原理与数学表达
1. 核心思想
模拟蒙特卡洛随机采样逻辑,从多个尺度的池化张量中随机选择特征,通过概率加权融合,生成兼具泛化性和细节捕捉能力的注意力图,避免单一尺度的特征偏见。
2. 数学公式
给定输入张量 ( x ),MCAttn的输出注意力图 ( A_m(x) ) 计算如下:
[ A_m(x) = \sum_{i=1}^n P_1(x,i) \cdot f(x,i) ]
- ( n=3 ):固定采用3种池化尺度(1×1、2×2、3×3),覆盖局部到全局特征;
- ( f(x,i) ):第 ( i ) 种尺度的平均池化函数;
- ( P_1(x,i) ):关联概率,满足 ( \sum_{i=1}^3 P_1(x,i)=1 ) 和 ( \prod_{i=1}^3 P_1(x,i)=0 ),确保随机采样的泛化性,避免单一尺度主导。
工作流程与结构细节
1. 模块定位
MCAttn集成于 MCBottleneck(蒙特卡洛注意力瓶颈模块) 中,每个编码器阶段均包含MCBottleneck,结构链为:
3×3卷积 → 1×1卷积 → MCAttn → 1×1卷积 → AssemFormer
MCBottleneck作为“信息压缩-扩展”节点,MCAttn负责在压缩阶段保留小目标关键特征。
2. 具体步骤
- 多尺度池化:对输入张量 ( x ) 分别进行1×1、2×2、3×3池化,得到3种尺度的特征张量;
- 概率采样:根据关联概率 ( P_1(x,i) ) 随机选择1种尺度的池化结果,生成初始注意力图;
- 特征校准:将注意力图与输入张量进行逐元素乘积(Hadamard product),强化小目标特征、抑制背景噪声;
- 跨尺度融合:通过随机采样的随机性,间接融合3种尺度的特征信息,兼顾局部细节(小尺度池化)和全局上下文(大尺度池化)。
关键优势
1. 跨尺度特征捕捉
相比SE(仅通道注意力)、CBAM(通道+空间单尺度)、CoorAttn(坐标感知单尺度),MCAttn通过3种尺度随机采样,天然具备跨尺度关联能力,对超小目标(如占比<1%的精子、视网膜血管)的稀疏区域识别更精准。
2. 泛化性强
关联概率 ( P_1(x,i) ) 的约束条件(求和为1、乘积为0)确保注意力图不依赖固定尺度,适配不同模态(CT、MRI、显微镜图像)和不同形态的小医疗目标(肿瘤、细胞、血管)。
3. 轻量化设计
参数数量仅2.77M(与SE相同),远低于复杂注意力机制,且不显著增加计算量,保证SvANet的实时推理能力(46.91 FPS)。
核心代码
class MoCAttention(nn.Module):# Monte carlo attentiondef __init__(self,InChannels: int,HidChannels: int=None,SqueezeFactor: int=4,PoolRes: list=[1, 2, 3],Act: Callable[..., nn.Module]=nn.ReLU,ScaleAct: Callable[..., nn.Module]=nn.Sigmoid,MoCOrder: bool=True,**kwargs: Any,) -> None:super().__init__()if HidChannels is None:HidChannels = max(makeDivisible(InChannels // SqueezeFactor, 8), 32)AllPoolRes = PoolRes + [1] if 1 not in PoolRes else PoolResfor k in AllPoolRes:Pooling = AdaptiveAvgPool2d(k)setMethod(self, 'Pool%d' % k, Pooling)self.SELayer = nn.Sequential(BaseConv2d(InChannels, HidChannels, 1, ActLayer=Act),BaseConv2d(HidChannels, InChannels, 1, ActLayer=ScaleAct),)self.PoolRes = PoolResself.MoCOrder = MoCOrderdef monteCarloSample(self, x: Tensor) -> Tensor:if self.training:PoolKeep = np.random.choice(self.PoolRes)x1 = shuffleTensor(x)[0] if self.MoCOrder else xAttnMap: Tensor = callMethod(self, 'Pool%d' % PoolKeep)(x1)if AttnMap.shape[-1] > 1:AttnMap = AttnMap.flatten(2)AttnMap = AttnMap[:, :, torch.randperm(AttnMap.shape[-1])[0]]AttnMap = AttnMap[:, :, None, None] # squeeze twiceelse:AttnMap: Tensor = callMethod(self, 'Pool%d' % 1)(x)return AttnMapdef forward(self, x: Tensor) -> Tensor:AttnMap = self.monteCarloSample(x)return x * self.SELayer(AttnMap)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('./ultralytics/cfg/models/26/yolo26-MoCAttention.yaml')
# 修改为自己的数据集地址model.train(data='./ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='MuSGD',amp=True,project='runs/train',name='yolo26-MoCAttention',)结果