Pandas --DataFrame 文件处理
一. csv文件读写操作
"""csv文件读取 """ #sep间隔符号是逗号,默认也是逗号 #head()是默认读取前5条的数据 #默认读取所有列,如果只读只指几列数据,使用usecols df=pd.read_csv("doc/companyinfo.csv",sep=",",usecols=["姓名","电话号码"]) print(df.head())#默认索引是0,1,2,3,4,这里我们改成时间作用为索引 df=pd.read_csv("doc/companyinfo.csv",sep=",",usecols=["姓名","电话号码","时间"],index_col="时间") print(df.head())
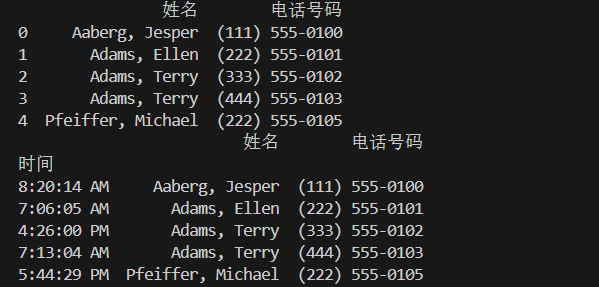
"""csv文件写入 """ #将读取到的三列数据写入新的文件 df=pd.read_csv("doc/companyinfo.csv",sep=",",usecols=["姓名","电话号码","时间"],index_col="时间") df.to_csv("doc/newcompanyinfo.csv")
二. Excel 文件读写操作
"""excel文件读取 """ #默认读取第一个sheet,索引从0开始 df=pd.read_excel("doc/stock.xlsx",sheet_name=1) print(df.head())

#写入 df=pd.read_excel("doc/stock.xlsx",sheet_name=1,usecols=["时间2","成交量2"]) df.to_excel("doc/newstock.xlsx")
作者:花阴偷移
出处:https://www.cnblogs.com/MrHSR/
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。