JeecgBoot AI专题研究 | JeecgBoot低代码知识库节点配置与RAG检索增强生成实战解析
大模型的"知识盲区"与 RAG 方案
大模型虽然拥有强大的语言理解和生成能力,但它的知识存在两个天然短板:一是训练数据有截止时间,无法掌握最新信息;二是对企业内部的私有数据一无所知。当用户提问涉及公司制度、产品文档、业务规则等内容时,通用大模型只能"编"一个看似合理实则可能完全错误的答案。
RAG(Retrieval-Augmented Generation,检索增强生成) 正是为解决这一问题而生的技术方案——先从知识库中检索与问题相关的内容片段,再将这些片段作为上下文传递给大模型,让模型"有据可依"地生成回答。
JeecgBoot低代码平台的知识库节点,就是 AI 工作流中实现 RAG 能力的核心组件。它负责接收上游传入的查询条件,从预配置的知识库中检索最相关的文档片段,并将结果输出给下游节点(通常是大模型节点)。
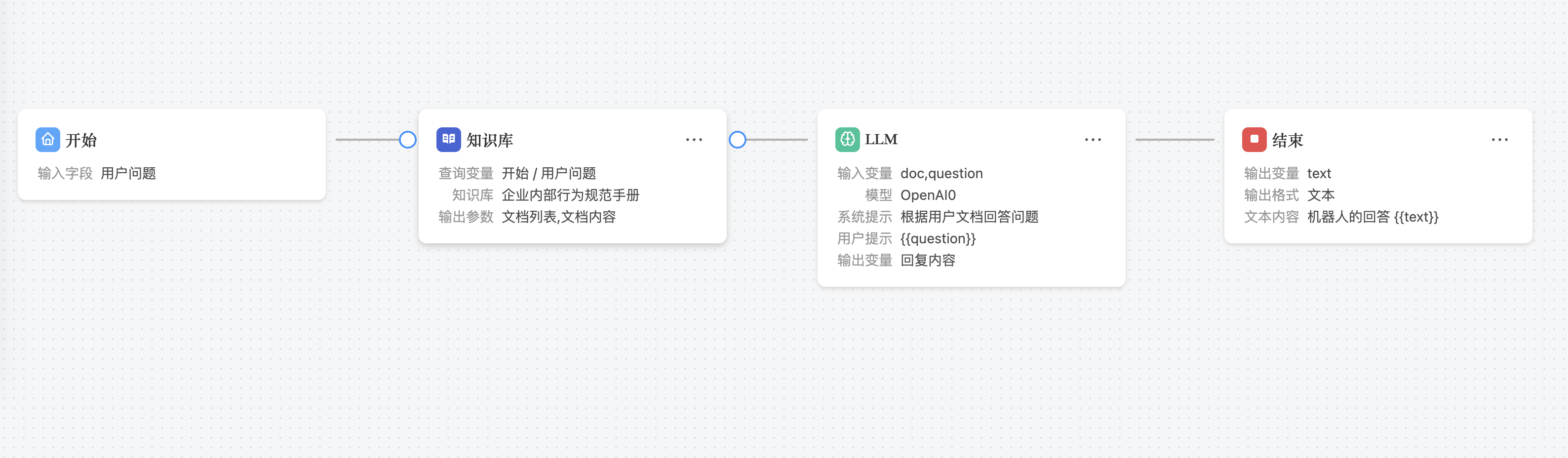
哪些场景适合使用知识库节点?
知识库节点的核心价值在于"让 AI 基于你的数据回答问题",以下是几类典型应用场景:
- 智能客服:基于产品 FAQ、操作手册构建问答系统,用户提问后自动从知识库中检索相关内容并生成精准回复
- 文档助手:将企业内部的技术文档、规范制度导入知识库,员工可以用自然语言提问,快速定位所需信息
- 合规审查:将法规条文、合规要求作为知识库,AI 在审查业务内容时自动检索相关条款作为判断依据
- 新人培训:将培训材料和常见问题整理为知识库,新员工可以随时向 AI 助手提问,获得基于内部知识的准确回答
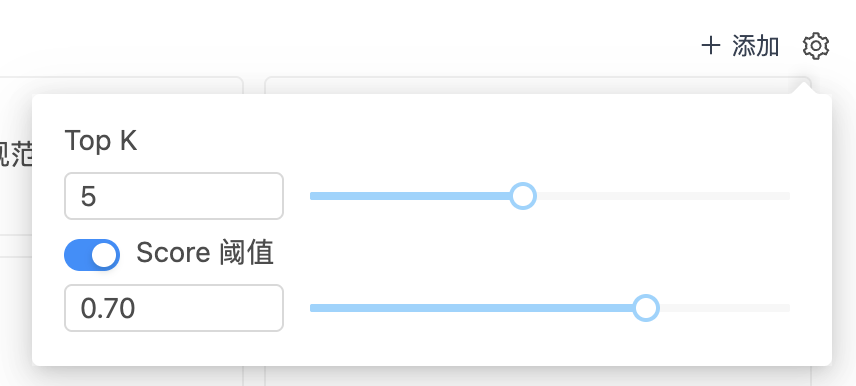
添加知识库节点
在流程画布中,点击前一节点下方的 + 图标,从节点列表中选择"知识库"即可完成添加。

节点配置详解
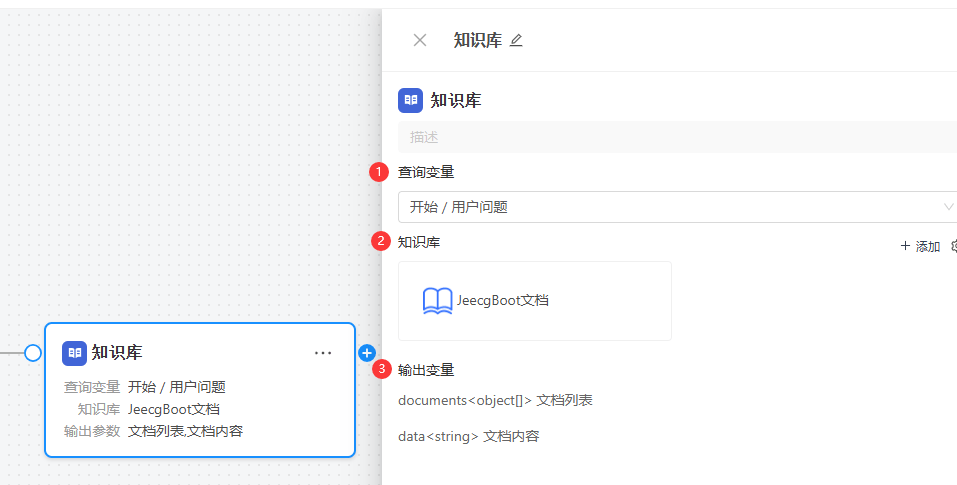
选中已添加的知识库节点后,右侧面板展示全部配置项,主要分为三个部分:
配置输入变量
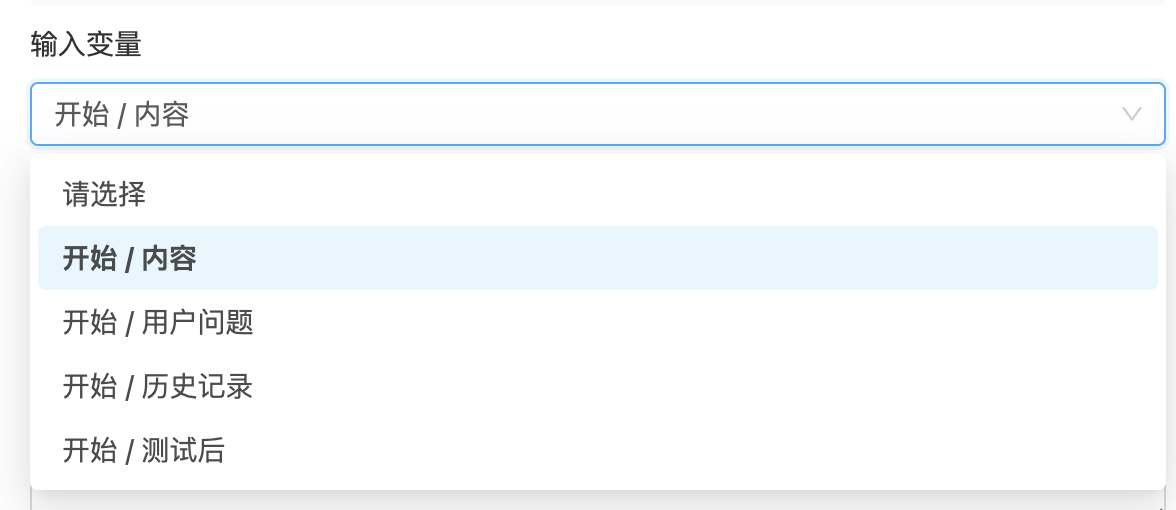
输入变量决定了"用什么去查知识库"——它定义了知识库检索的查询条件来源。知识库节点会将该变量的内容作为语义查询关键词,在知识库中执行向量相似度检索。
实际使用中,输入变量通常绑定为"用户的原始提问"或经过前置节点处理后的"优化查询语句"。例如在客服场景中,可以先用一个大模型节点将用户的口语化提问改写为更精确的检索关键词,再传递给知识库节点,这样能显著提升检索命中率。
注意:变量来源必须是当前节点的上游节点,不能引用并行或下游节点的输出。
知识库选择与检索参数
在此区域选择需要查询的目标知识库。JeecgBoot低代码平台支持同时查询多个知识库,系统会自动整合来自不同知识库的检索结果并统一返回。
每个知识库旁边的设置按钮可以配置两个关键的检索参数:
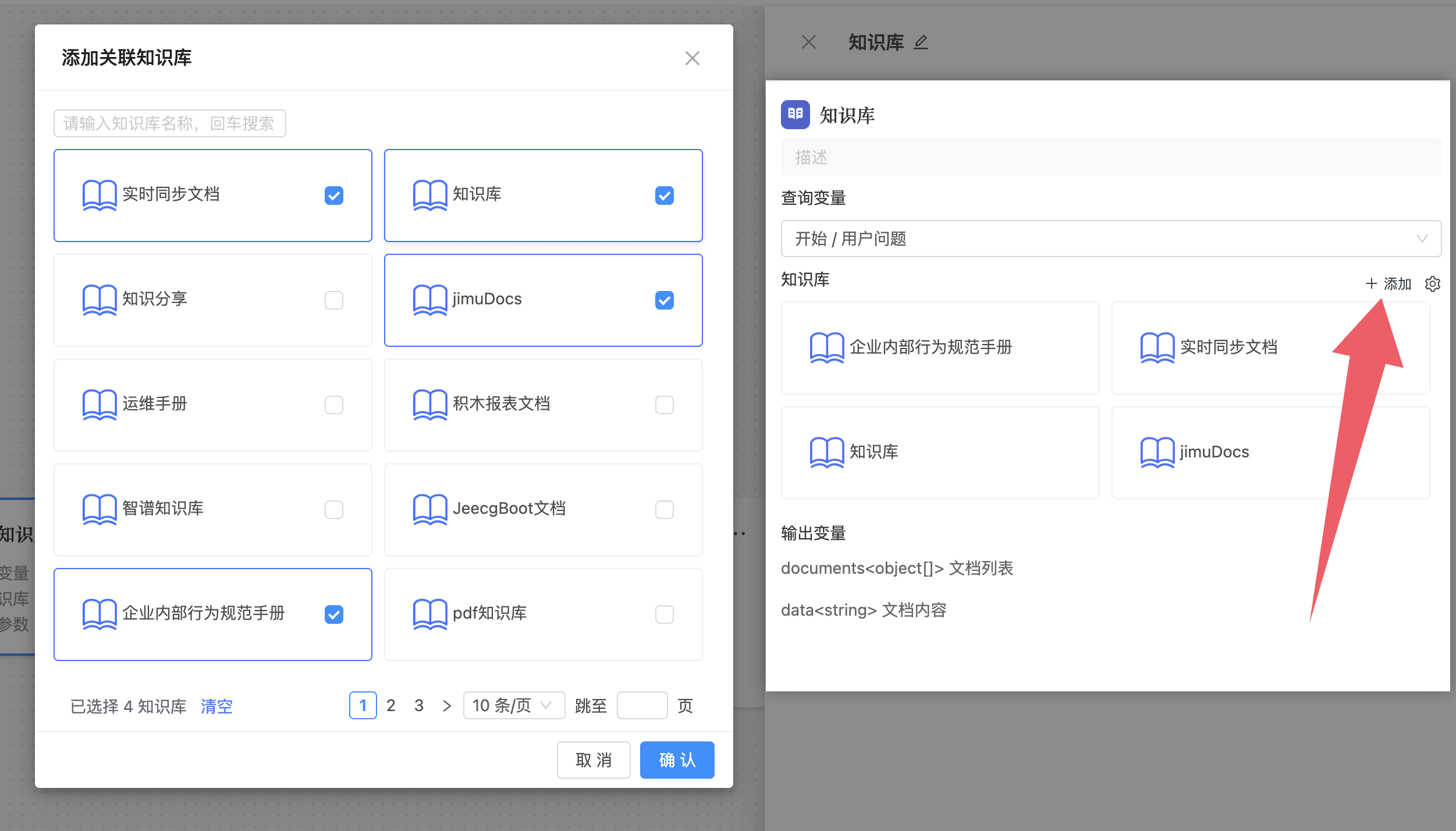
| 参数 | 含义 | 调优建议 |
|---|---|---|
| TOP K | 返回相似度最高的前 K 条文档片段 | K 值越大召回越多但可能引入噪音,一般建议 3~5。对于简短问答场景可设为 2~3,复杂分析场景可设为 5~10 |
| Score 阈值 | 最低相似度分数,低于此分数的结果会被过滤 | 阈值越高结果越精确但可能遗漏相关内容。建议初始设为 0.5,根据实际效果逐步调整 |
这两个参数的合理配置对问答质量影响巨大:TOP K 过小可能漏掉关键信息,过大则会引入不相关内容干扰大模型;Score 阈值过高会导致"查不到",过低则会返回大量低质量片段。建议在开发阶段多做几轮测试,找到适合你业务数据的最佳参数组合。
理解输出变量
知识库节点检索完成后,会输出两个变量供下游节点使用:
| 输出变量 | 类型 | 说明 |
|---|---|---|
| documents | 数组 | 检索到的文档片段列表,包含完整的结构化信息(片段内容、来源文档、相似度分数等) |
| data | 字符串 | 所有检索到的文档片段正文合并后的纯文本,适合直接传递给大模型作为上下文 |
在大多数场景中,下游大模型节点直接引用 data 变量即可——它已经将所有相关片段拼接为一段连续文本,模型可以直接阅读理解。如果需要对检索结果做更精细的处理(比如按相似度排序筛选、提取来源信息等),则使用 documents 数组变量。
搭建完整 RAG 流程的实战建议
知识库节点通常不会单独使用,而是作为 RAG 流程中的关键一环。一个典型的完整流程如下:
用户提问 → [查询改写节点(可选)] → 知识库节点 → 大模型节点 → 输出回答
几点实战经验:
- 知识库质量决定上限:再好的检索参数也无法弥补低质量的知识库内容。导入前建议对文档做清洗、分段优化
- 查询改写提升检索效果:在知识库节点前加一个大模型节点,将用户的口语化提问改写为更适合语义检索的表述
- 多知识库分而治之:按主题将知识拆分到不同知识库中(如"产品文档库"、"FAQ 库"、"规章制度库"),根据场景选择性查询,减少噪音
- Prompt 工程配合:在下游大模型节点的提示词中明确指示"仅基于以下参考资料回答,不要编造",避免模型在知识库未覆盖的问题上胡编乱造
总结
JeecgBoot低代码平台的知识库节点,是构建企业私域 RAG 问答系统的核心组件。通过灵活的多知识库查询、可调节的检索参数以及结构化的输出变量,它让开发者无需编写复杂的检索代码,就能在可视化工作流中实现"基于企业知识的精准 AI 问答"能力。结合上下游节点的协作,知识库节点真正打通了"私有数据"与"大模型推理"之间的通道。
本文为 JeecgBoot AI 专题研究系列文章。