数据采集与融合实验报告
作业①
1)实验内容
要求:
▪ 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内
容。
▪ 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、
“深证A股”3个板块的股票数据信息。
网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
代码说明
import time
import sqlite3
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
# 设置Chrome浏览器的选项
chrome_options = Options()
# 设置ChromeDriver路径
chrome_driver_path = r"D:\HuaweiMoveData\Users\33659\Desktop\python\chromedriver-win64\chromedriver.exe"
# 初始化WebDriver
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)def connect_db():conn = sqlite3.connect('stocks_sz.db')return conndef create_table():conn = connect_db()cursor = conn.cursor()cursor.execute("""CREATE TABLE IF NOT EXISTS stocks(idINTEGERPRIMARYKEYAUTOINCREMENT,股票名称TEXTNOTNULL,股票代码TEXTNOTNULL,最新报价REAL,涨幅REAL,涨跌额REAL,成交量REAL,成交额REAL,最高价REAL,最低价REAL,今开盘价REAL,昨收REAL)""")conn.commit()cursor.close()conn.close()def insert_stock_data(name, code, price, change_rate, change_amount, volume, amount, high, low, open_price, last_close):conn = connect_db()cursor = conn.cursor()cursor.execute("""INSERT INTO stocks (股票名称, 股票代码, 最新报价, 涨幅, 涨跌额, 成交量, 成交额, 最高价, 最低价, 今开盘价, 昨收)VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)""",(name, code, price, change_rate, change_amount, volume, amount, high, low, open_price, last_close))conn.commit()cursor.close()conn.close()def scrape_data():try:time.sleep(3)
#//*[@id="mainc"] 这个是数据表的xpath路径rows = driver.find_elements(By.XPATH, '//*[@id="mainc"]/div/div/div/table/tbody/tr')for row in rows:try:# 提取每行数据code = row.find_element(By.XPATH, './td[2]/a').text # 股票代码name = row.find_element(By.XPATH, './td[3]/a').text # 股票名称price = row.find_element(By.XPATH, './td[5]/span').text # 最新报价change_rate = row.find_element(By.XPATH, './td[6]/span').text # 涨跌幅change_amount = row.find_element(By.XPATH, './td[7]/span').text # 涨跌额volume = row.find_element(By.XPATH, './td[8]/span').text # 成交量amount = row.find_element(By.XPATH, './td[9]/span').text # 成交额high = row.find_element(By.XPATH, './td[10]/span').text # 最高价low = row.find_element(By.XPATH, './td[11]/span').text # 最低价open_price = row.find_element(By.XPATH, './td[12]/span').text # 今开盘价last_close = row.find_element(By.XPATH, './td[13]/span').text # 昨收# 将数据保存到SQLite数据库insert_stock_data(name, code, price, change_rate, change_amount, volume, amount, high, low, open_price,last_close)print(f"股票: {name}, 代码: {code}, 当前价: {price}, 涨幅: {change_rate}, 涨跌额: {change_amount}, 成交量: {volume}, 成交额: {amount}")except Exception as e:print(f"Error: {e}")continueexcept Exception as e:print(f"等待数据加载时出错: {e}")#这是关闭广告的函数,用的方法是物理点击空白处(因为经过我测试发现只要点击页面空白处,广告就会关闭)
def close_ad_popup():try:safe_area = driver.find_element(By.XPATH, '//body')actions = ActionChains(driver)actions.move_to_element(safe_area).click().perform() # 模拟点击print("广告已关闭")except Exception as e:print(f"关闭失败: {e}")# 这是我的翻页函数
def click_next_page():try:driver.execute_script('document.querySelector("a[title=\'下一页\']").click();')time.sleep(5)print("点击了下一页")except Exception as e:print(f"未找到“下一页”按钮,错误信息:{e}")# 这是爬虫主体函数,调用了前面的函数
def scrape_pages(pages=5):# 只在第一次爬取时关闭广告,因为只有第一次会弹广告close_ad_popup()for page in range(1, pages + 1):print(f"正在爬取第 {page} 页数据...")scrape_data()# 点击“下一页”click_next_page()# 主程序
if __name__ == "__main__":create_table()# 设置初始URL,这个url是可以改变的,三个web只有后缀的两个字母不一样(页面结构完全相同),所以改起来很方便initial_url = "https://quote.eastmoney.com/center/gridlist.html#sz_a_board"driver.get(initial_url)time.sleep(5)# 我只爬取了五页scrape_pages(5)driver.quit()结果展示
hs(沪深京A股):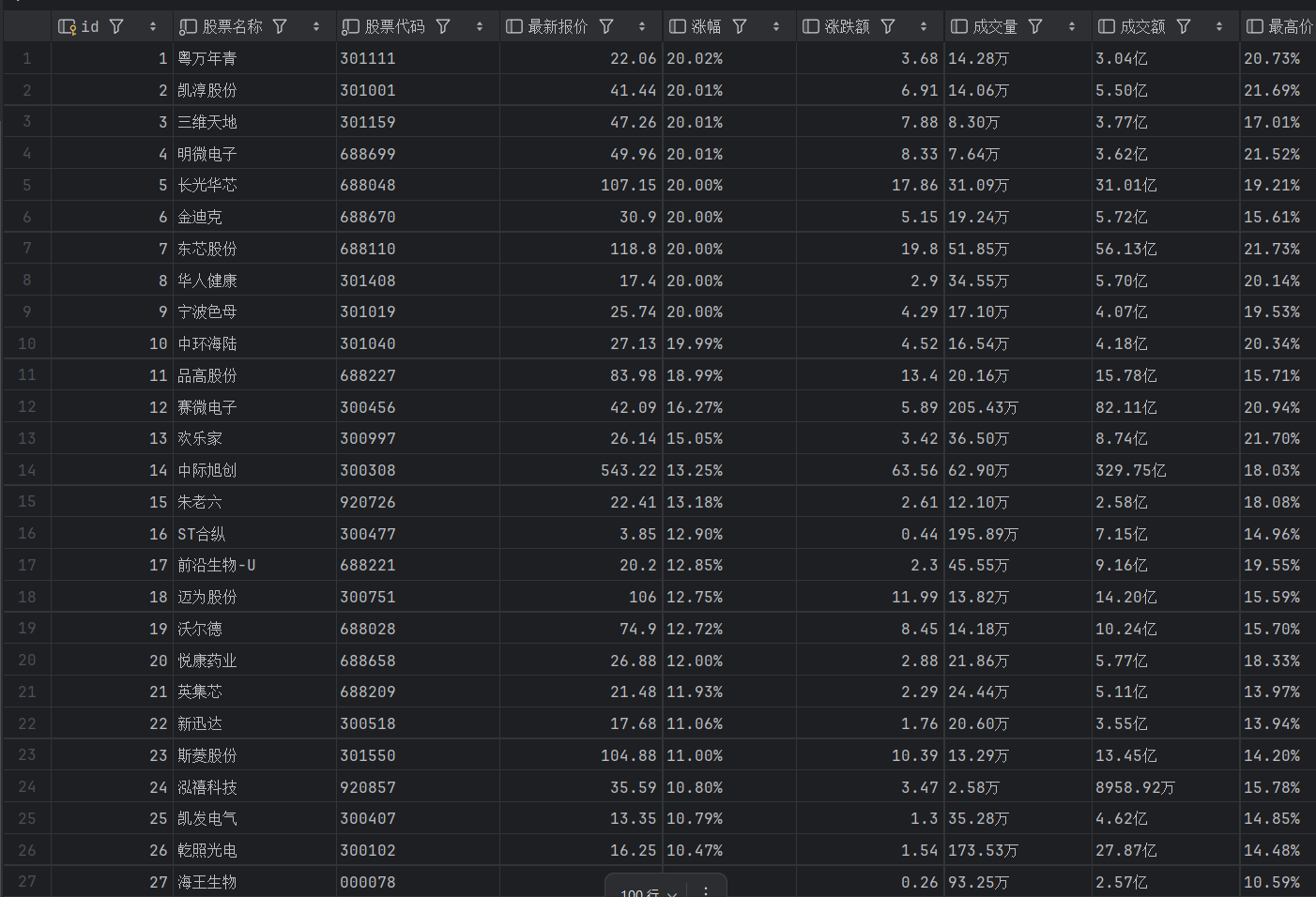
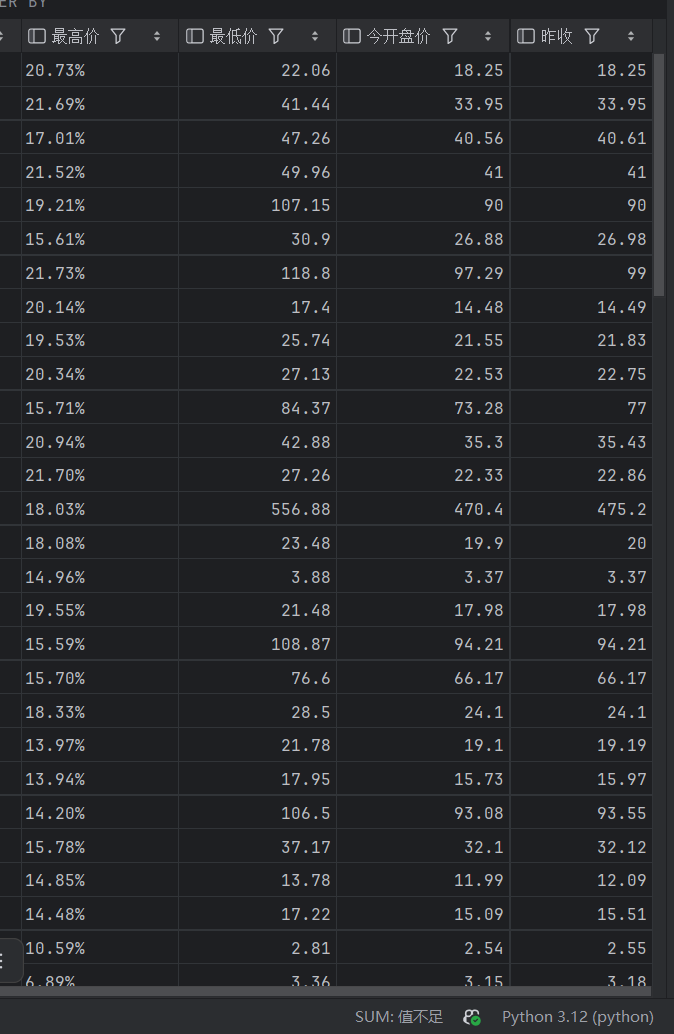
sh (上证A股) :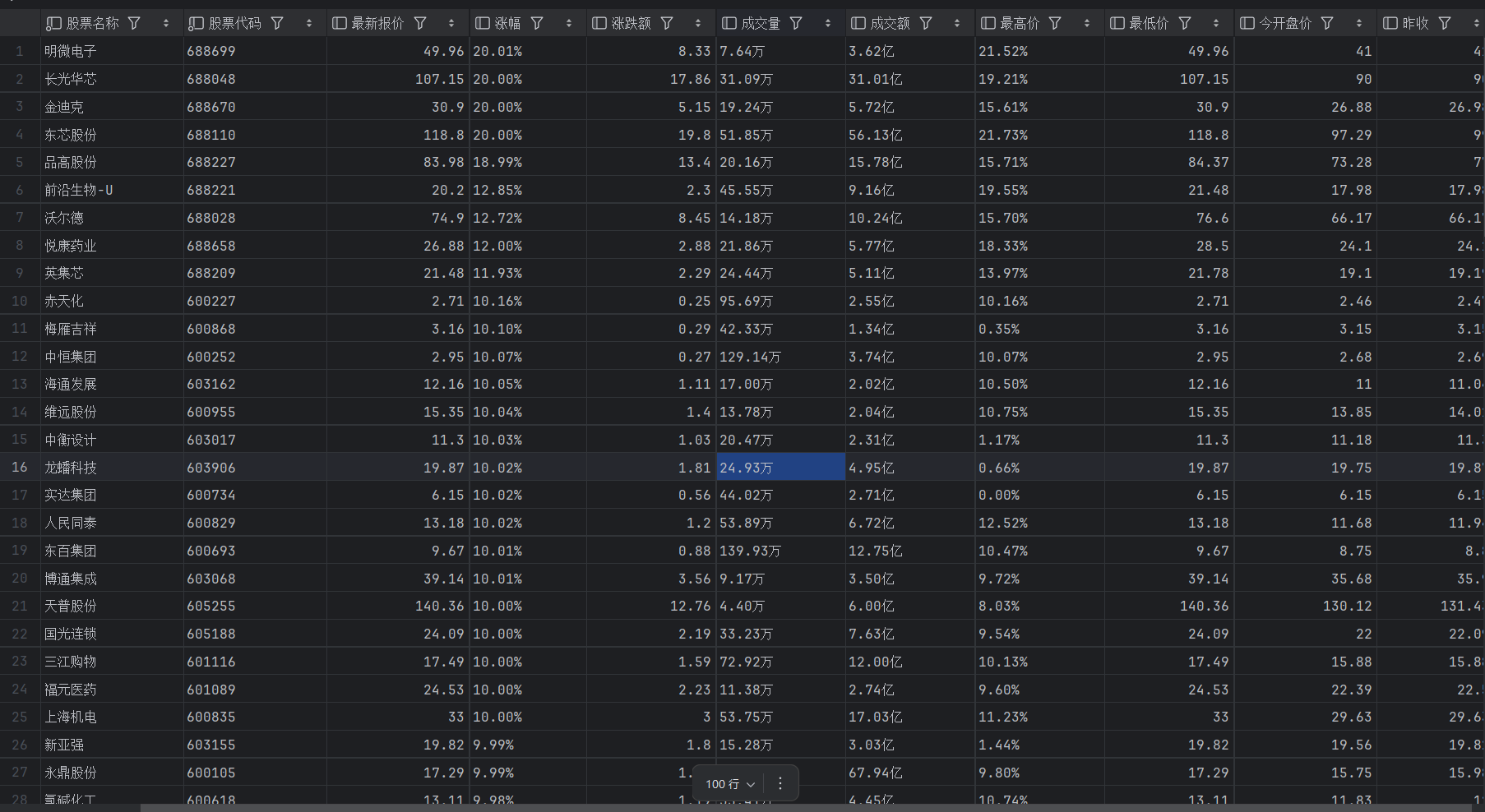
sz (深证A股):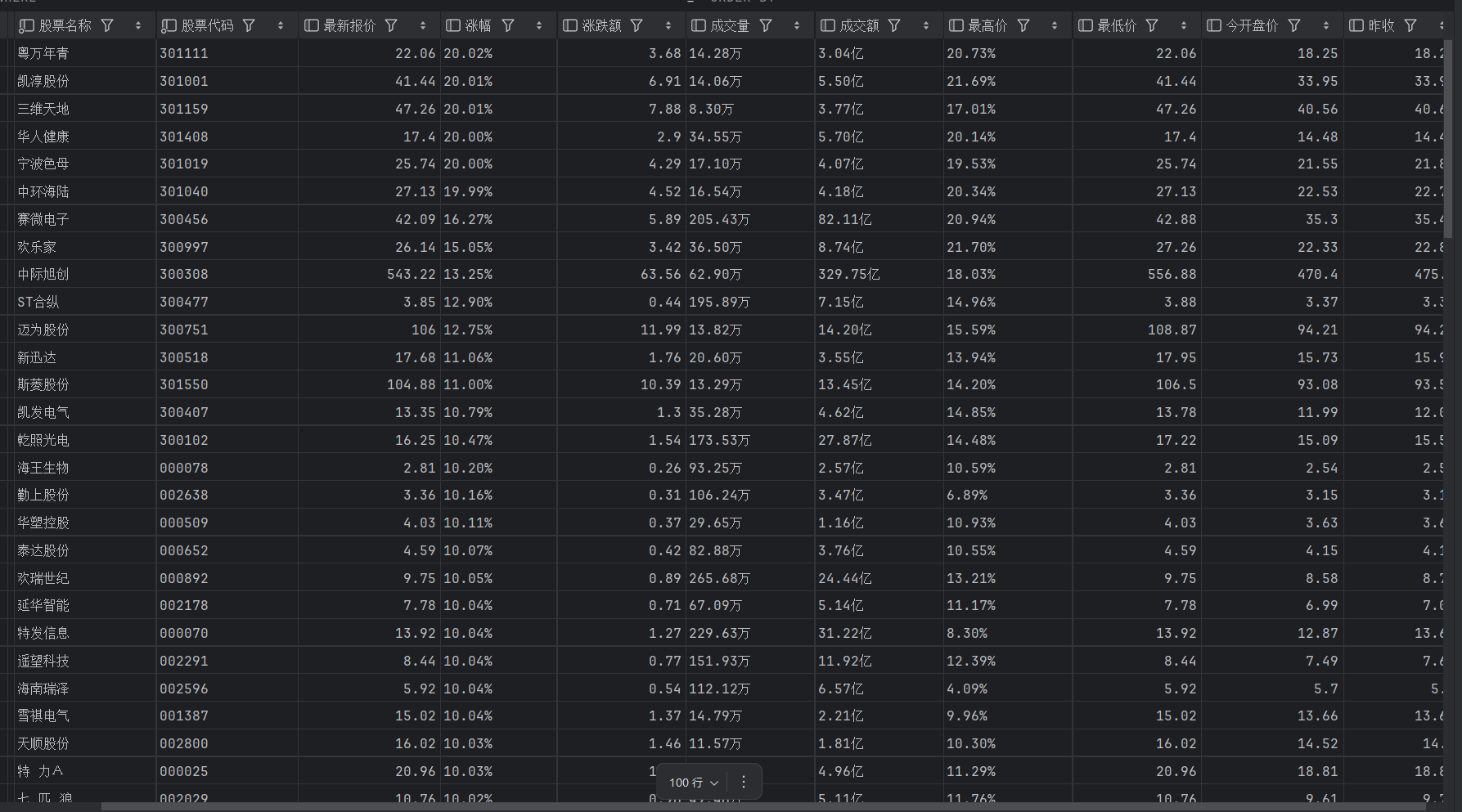
gitee链接:https://gitee.com/zhuang-jingxuan/data/blob/master/作业代码/第四次作业/作业1.py
2)心得体会
一开始被广告折腾了很久,找到了他的关闭图标的点击,但是还是关不掉,后来自己研究了一下,发现其实不用直接关闭广告,只需要点击空白处,广告就会关闭。再然后就是查找xpath元素的时候,爬取不到数据。后来问了老师,发现自己的find_elements写得太限制了,他匹配不到,需要再往上多递归几层,才能找到元素。
作业②
1)实验内容
要求:
▪ 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、
等待HTML元素等内容。
▪ 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国mooc网:https://www.icourse163.org
o 输出信息:MYSQL数据库存储和输出格式
因为首页太难爬取了(url隐藏),所以我退而求其次,选择自己个人学习过的课程,爬取了4个。模拟登录用我的是我自己的cookie。
代码说明
import time
import sqlite3
import os
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 设置Chrome浏览器的选项
chrome_options = Options()
chrome_driver_path = r"D:\HuaweiMoveData\Users\33659\Desktop\python\chromedriver-win64\chromedriver.exe"
# 初始化WebDriver
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)def init_db():conn = sqlite3.connect('mooc_courses.db')cursor = conn.cursor()cursor.execute('''CREATE TABLE IF NOT EXISTS courses (id INTEGER PRIMARY KEY AUTOINCREMENT,course_number TEXT,course_title TEXT,school TEXT,teacher TEXT,participants TEXT,progress TEXT,intro TEXT,team_members TEXT )''')conn.commit()print(f"数据库文件路径: {os.path.abspath('mooc_courses.db')}")return conn, cursordef insert_course_info(conn, cursor, info):try:cursor.execute('''INSERT INTO courses (course_number, course_title, school, teacher, participants, progress, intro, team_members)VALUES (?, ?, ?, ?, ?, ?, ?, ?)''', (info['course_number'], info['course_title'], info['school'],info['teacher'], info['participants'],info['progress'], info['intro'],info['team_members']))conn.commit()course_id = cursor.lastrowidprint(f"成功插入课程 {info['course_title']},课程ID为 {course_id}")return course_idexcept Exception as e:print(f"插入课程失败: {e}")def get_course_info(driver, course_url, course_number):driver.get(course_url)wait = WebDriverWait(driver, 15)# 课程名称title = wait.until(EC.visibility_of_element_located((By.XPATH, "//*[@id='g-body']/div[1]/div/div/div/div[2]/div[2]/div/div[2]/div[1]/span[@class='course-title f-ib f-vam']"))).text# 学校名称school = ""try:school = driver.find_element(By.XPATH, "//*[@id='j-teacher']/div/a/img").get_attribute('alt')except:school = "无"# 主讲教师teacher = ""try:teacher = driver.find_element(By.XPATH, "//*[@id='j-teacher']/div/div/div[2]/div/div/div/div/div/h3[@class='f-fc3']").textexcept:teacher = "无"# 团队成员(多个团队成员)team_members = []try:names = driver.find_elements(By.XPATH, "//h3[@class='f-fc3']")if names:for name in names:team_members.append(name.text)else:team_members.append("无")except Exception as e:print(f"抓取团队成员失败: {e}")team_members = ["无"]# 参与人数 —— 广泛搜索 span.count 并提取数字participants = "无"try:span_elem = driver.find_element(By.CSS_SELECTOR, "span.count")text = span_elem.text# 用正则提取数字m = re.search(r"\d+", text)if m:participants = m.group(0)print(f"参与人数: {participants}")except Exception as e:print(f"抓取参与人数失败: {e}")participants = "无"participants_str = participants if participants else "无"# 课程进度progress = ""try:progress = driver.find_element(By.XPATH, "//*[@id='course-enroll-info']/div/div[1]/div[4]/span[@class='text']").textexcept:progress = "无"# 课程简介intro = ""try:intro = driver.find_element(By.XPATH, "//*[@id='j-rectxt2']").textexcept:intro = "无"return {"course_number": course_number,"course_title": title,"school": school,"teacher": teacher,"team_members": ', '.join(team_members),"participants": participants_str,"progress": progress,"intro": intro}if __name__ == "__main__":course_urls = ["https://www.icourse163.org/course/ZJU-1472847200","https://www.icourse163.org/course/ZJU-1003377027","https://www.icourse163.org/course/ZJU-1472836187","https://www.icourse163.org/course/DUT-1463110162",]# 初始化数据库连接conn, cursor = init_db()results = []for index, url in enumerate(course_urls, start=1):try:info = get_course_info(driver, url, index)print(f"爬取成功: {info['course_number']} - {info['course_title']}")course_id = insert_course_info(conn, cursor, info)except Exception as e:print(f"爬取失败: {url} - {e}")driver.quit()cursor.execute("SELECT * FROM courses")rows = cursor.fetchall()print("数据库中的课程信息:")for row in rows:print(row)cursor.close()conn.close()print("爬取完成,数据已保存到数据库")结果展示

gitee链接:https://gitee.com/zhuang-jingxuan/data/blob/master/作业代码/第四次作业/作业2.py
2)心得体会
爬取web的方式用的webdriver,遍历数组当中的所有web,查找元素一开始用的Xpath,发现团队人员的名字一直爬取不了(应该也是写得太限制了),之后用全页面搜索,只搜索span.count,再用正则表达式匹配数字进行提取,反而成功了。说明有的时候查找元素没必要从上面几层一个个递归查找,只要保证该元素的属性名唯一,就可以直接查找了
作业③
1)实验内容
要求:
• 掌握大数据相关服务,熟悉Xshell的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部
分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
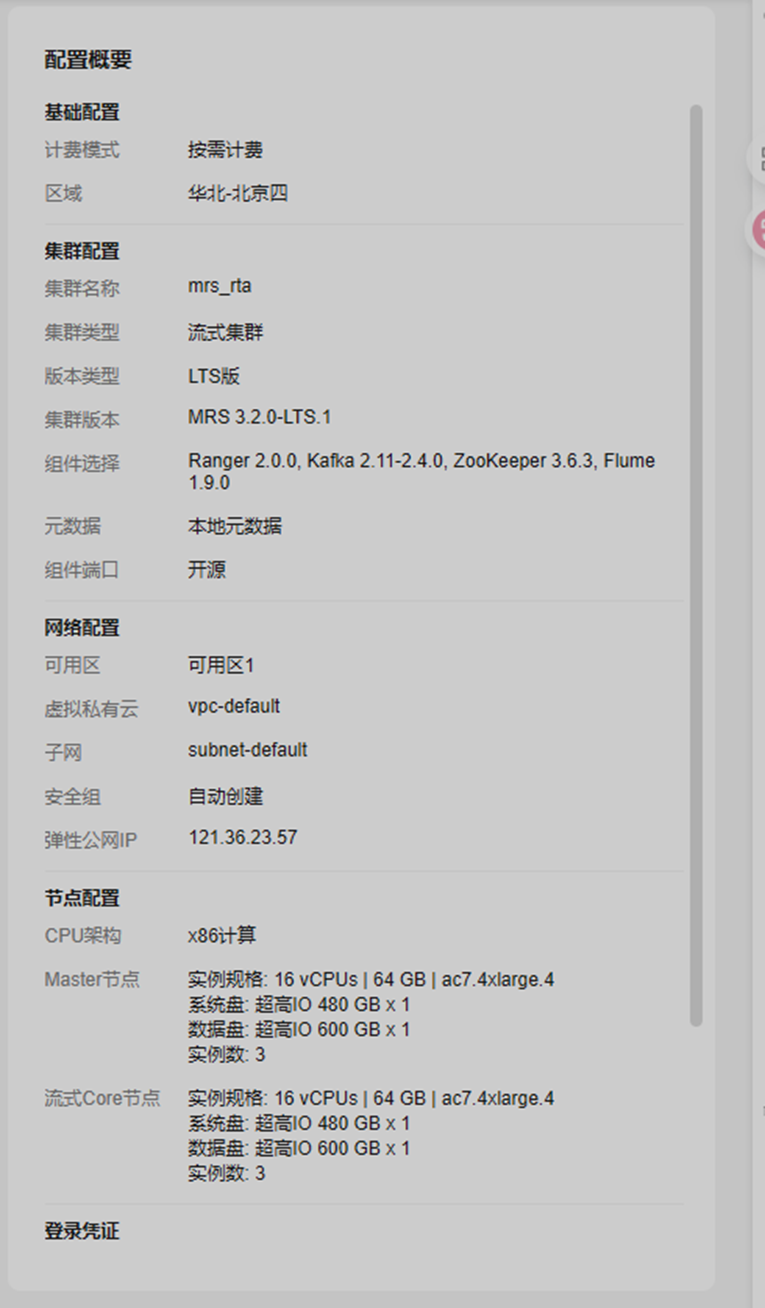
1.这是集群的创建
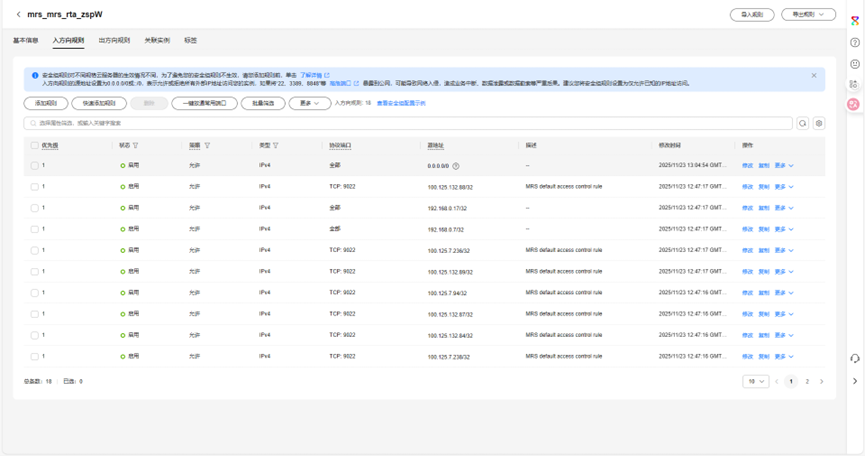
2.这是集群的节点
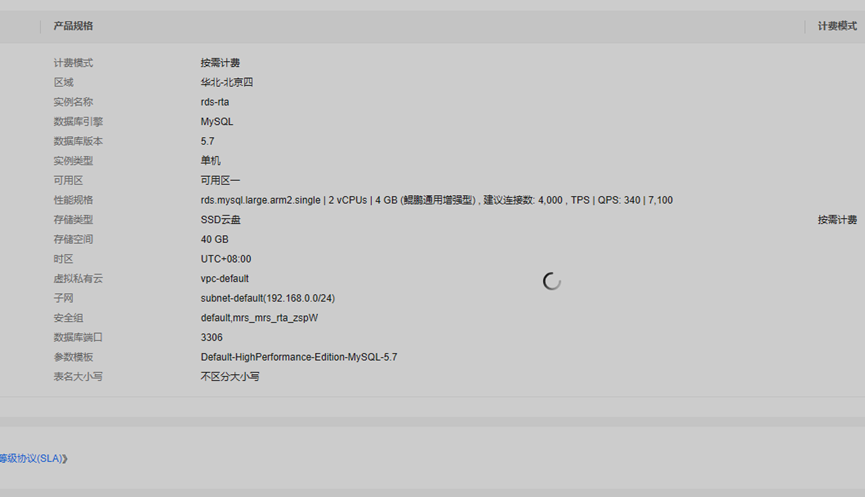
3.这是Mysql的创建以及其配置
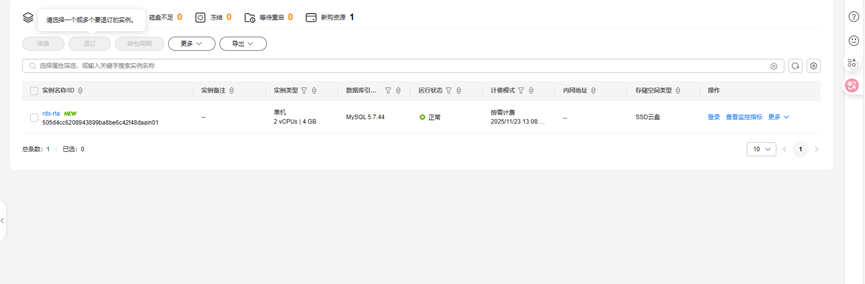
4.Mysql创建成功
5.弹性资源池的创建
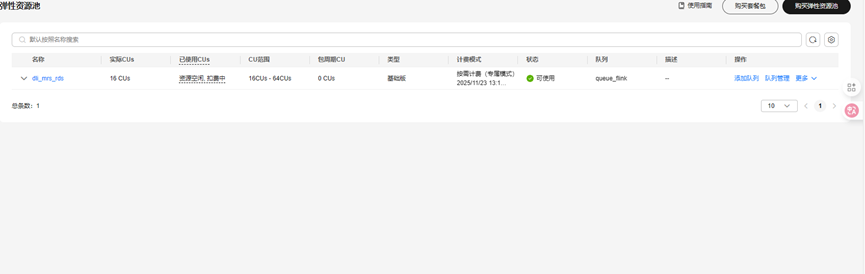
实时分析开发实战:
任务一:Python脚本生成测试数据

任务二:配置Kafka
进入到集群管理
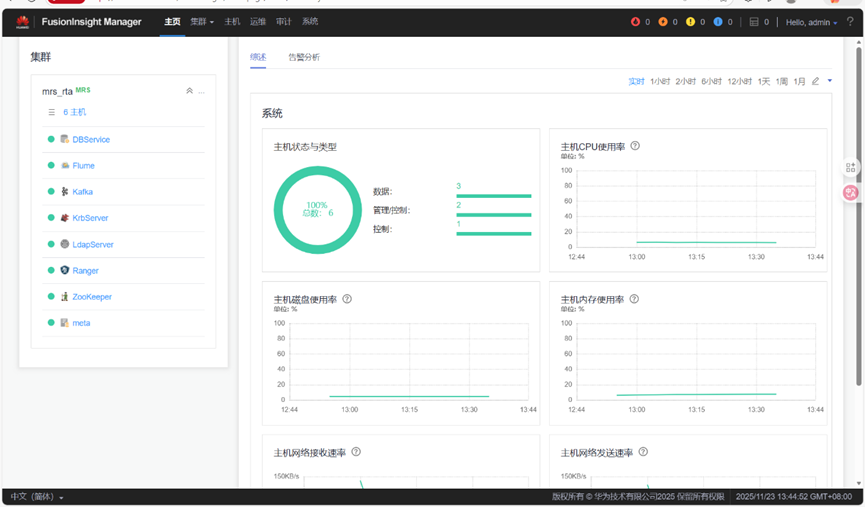
安装Kafka:
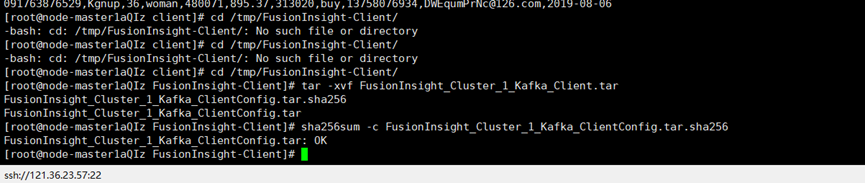
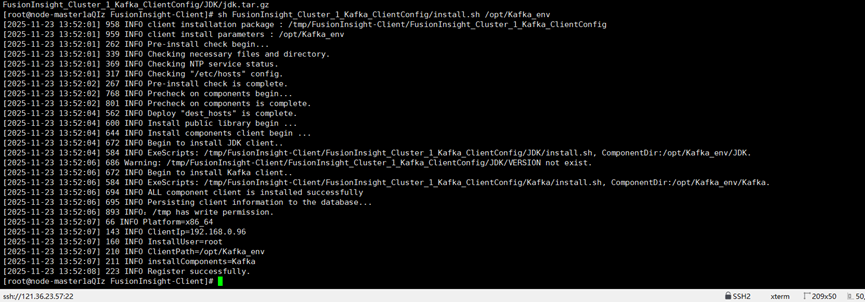
创建kafka-topic:

Kafka配置完毕:

任务三: 安装Flume客户端
Flume解压成功

Flume安装成功:
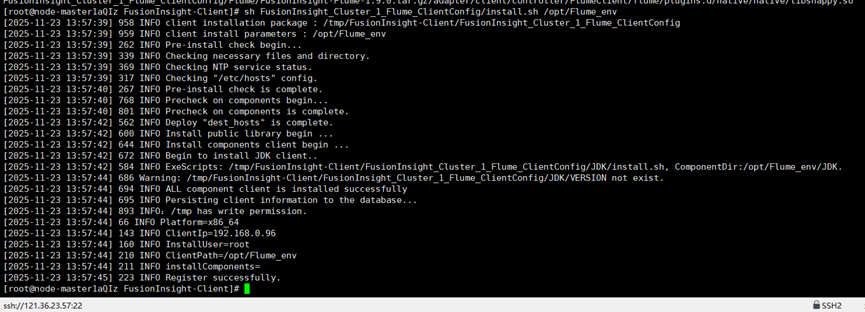

创建flume对象成功:

任务四:配置Flume采集数据
到第二个通话当中在启动python测试文件
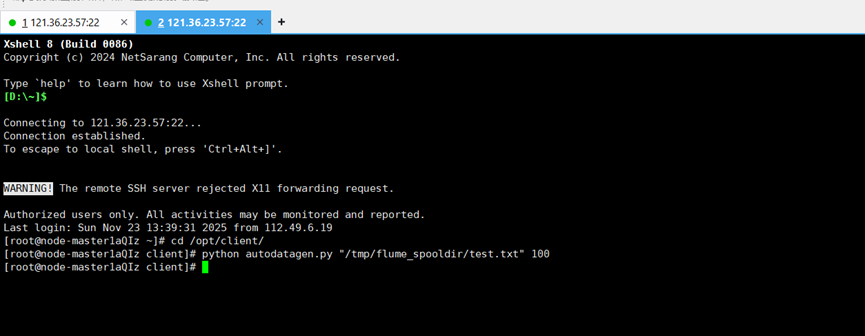
可以看到第一个通话多了100条数据
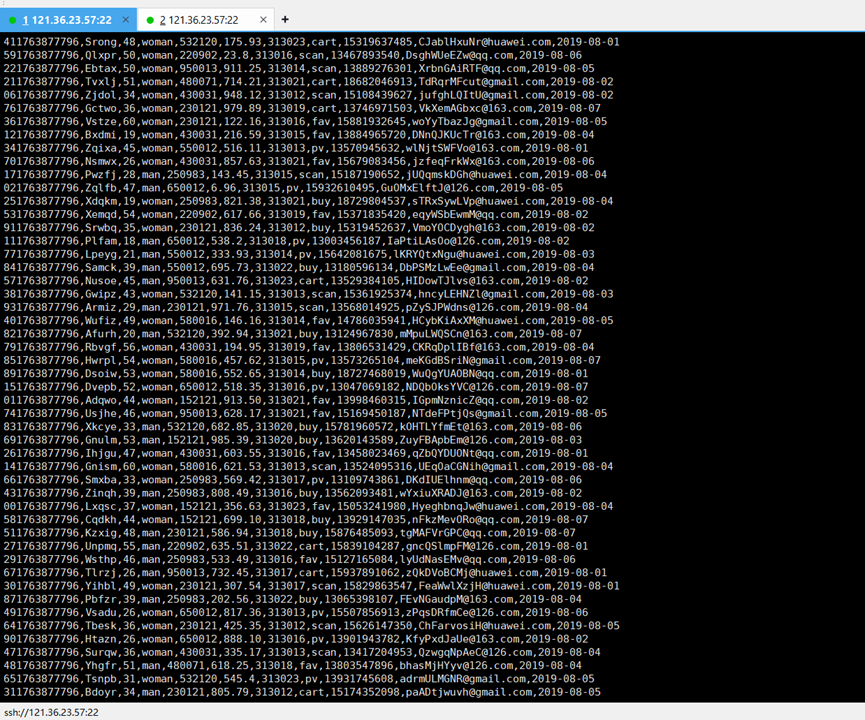
最后一共是200条

2)心得体会
这个实验我是严格按照实验手册上的来的,做的相当痛苦,做了快有四个小时。