声音识别(声纹识别)与语音识别:技术边界与应用场景的深度解析
一、技术本质的差异:生物特征识别 vs 内容语义解析
声纹识别(Voiceprint Recognition)本质上是生物特征识别技术,其核心在于通过分析声带振动、声道结构等生理特征形成的独特声波模式,提取如基频、共振峰、频谱包络等参数,构建个体唯一的声纹模型。其技术流程可分为特征提取(如MFCC、LPC)、模型训练(如GMM-UBM、i-vector、PLDA)和匹配验证三个阶段。例如,某银行声纹支付系统要求用户重复特定短语,系统通过比对实时声纹与注册模板的相似度(通常采用EER等指标)完成身份核验。
语音识别(Automatic Speech Recognition, ASR)则属于自然语言处理范畴,其目标是将声波信号转换为文本或命令。技术路径涉及声学模型(如CNN、RNN、Transformer)、语言模型(如N-gram、RNN-LM)和解码器(如WFST)的协同。以智能家居场景为例,用户说出”打开空调,26度”,ASR系统需先通过声学特征提取识别音素序列,再结合语言模型预测最可能的词序列,最终输出结构化指令。
关键差异点:声纹识别关注”谁在说”,依赖生理特征;语音识别关注”说了什么”,依赖语言内容。两者在特征空间上存在本质区别——声纹特征具有跨语言稳定性(如中文和英文的同一说话人声纹相似度高),而语音识别需针对不同语言训练独立模型。
二、应用场景的分化:安全认证 vs 交互控制
声纹识别的核心场景集中在高安全要求的身份认证领域:
- 金融支付:某国际银行采用动态声纹密码技术,用户需随机生成3位数字并朗读,系统通过声纹验证+内容校验双重机制,将欺诈风险降低至0.001%以下。
- 司法取证:公安部门利用声纹比对系统,在电话诈骗案件中通过嫌疑人通话录音与数据库比对,破案效率提升40%。
- 门禁系统:企业园区部署声纹门禁,员工无需携带卡片,仅需说出预设口令即可通过,误识率控制在0.1%以内。
语音识别的主流应用则聚焦于人机交互效率提升:
- 智能客服:某电商平台ASR系统支持中英文混合识别,实时转写用户咨询并自动分类,客服响应时间从平均120秒缩短至30秒。
- 车载系统:特斯拉Model S的语音控制模块采用端到端ASR架构,在80km/h时速下仍保持95%以上的识别准确率,支持导航、音乐控制等20余项功能。
- 医疗转录:科大讯飞智能语音系统可将医生口述病历实时转为结构化文本,转写效率达160字/分钟,错误率低于2%。
协同应用案例:在智能会议系统中,声纹识别用于参会者身份标注(如”张经理:关于预算…”),语音识别完成内容转写,两者结合实现会议纪要的自动生成与权限管理。
三、技术实现的关键挑战
声纹识别的核心难题:
- 跨信道问题:手机通话(8kHz采样)与高清录音(16kHz采样)的频谱差异可能导致性能下降。解决方案包括信道补偿算法(如FFTN)和对抗训练。
- 短时语音挑战:1秒以内的语音片段特征不足,需采用深度嵌入(Deep Embedding)技术提取更鲁棒的特征表示。
- 活体检测:防止录音重放攻击,需结合文本相关验证(如随机数字)和生理信号分析(如呼吸节奏)。
语音识别的技术瓶颈:
- 口音与方言适应:中文八大方言区的识别需构建大规模方言语料库,某团队通过迁移学习将粤语识别准确率从68%提升至89%。
- 噪声鲁棒性:工厂环境(SNR<5dB)下,可采用波束形成(Beamforming)和深度学习增强的谱减法(DSS)提升信噪比。
- 实时性要求:流式ASR需在100ms内输出首个结果,Facebook的Emformer架构通过记忆压缩技术将延迟降低至320ms。
四、开发者实践建议
-
场景适配选择:
- 身份认证场景优先选择声纹识别,推荐使用GMM-UBM算法(适合小样本)或ResNet34声纹编码器(适合大规模应用)。
- 交互控制场景选择语音识别,开源工具推荐Kaldi(传统模型)或WeNet(端到端模型)。
-
性能优化策略:
- 声纹系统:采用数据增强(如速度扰动、添加噪声)提升模型泛化能力,某团队通过此方法将跨信道性能提升15%。
- 语音系统:使用语言模型自适应(如插值法)优化垂直领域术语识别,医疗场景下专业术语识别率可提升20%。
-
隐私保护方案:
- 声纹数据建议采用局部差分隐私(LDP)处理,在特征提取阶段添加噪声,平衡可用性与隐私性。
- 语音数据推荐使用联邦学习框架,某银行通过此方式在保护用户数据的同时完成声纹模型更新。
五、未来技术融合趋势
随着多模态技术的发展,声纹与语音识别的融合呈现三大方向:
- 情感识别增强:结合声纹的基频变化和语音的语义内容,可更准确判断用户情绪(如愤怒、焦虑),某客服系统通过此技术将客户满意度提升18%。
- 抗攻击能力提升:联合声纹活体检测和语音内容验证,可有效防御AI合成语音攻击,最新研究显示联合系统的防伪能力达99.7%。
- 低资源场景突破:通过迁移学习将高资源语言(如中文)的声纹特征迁移至低资源语言,非洲某语种的声纹识别准确率从52%提升至76%。
结语:声纹识别与语音识别如同生物特征认证与自然语言处理的”双生子”,前者构建安全信任的基石,后者搭建高效交互的桥梁。开发者需深刻理解两者在技术本质、应用场景、实现难点上的差异,方能在智能语音的浪潮中精准布局,创造真正符合用户需求的价值。
ChipIntelli 声纹识别 Voice Print Recogition(VPR) 技术应用方案
声纹注册算法当前推荐最多注册4个人,人数越多会影响注册效果,如需注册更多人数,需确认效果达到使用要求;同时注册过的声纹支持单个删除或全部删除。
1.算法功能配置步骤如下:
打开CI13XX_SDK_ALG_PRO_Vx.x.x\project_file\makefile文件,将CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_VPR)
CI_ALG_TYPE变量和算法功能对应说明请参考:算法功能使用说明
2. 该算法参数宏说明在projects\CI13XX_SDK_ALG_PRO_Vx.x.x\app\app_main\user_config.h文件中, 可调整的参数如下(如无特殊需求,建议都使用sdk中的默认宏配置):
//声纹计算的窗长,单位为ms, 建议范围1200-1500,值越大消耗内存越多(每增加100,内存增加8KB)
#define VP_USE_FRM_LEN 1200
//声纹阈值-建议范围(0.48-0.68),值越大,灵敏度越低,误识越低,识别率下降,需要更严格的匹配注册的模版
#define VP_THR_FOR_MATCH (0.52f)
//声纹注册时重复录入次数 -注册时的次数
#define VP_REC_TIMES 3
//声纹识别功能允许的最大模版(用户)数,最大4个 重要说明:每个模版单次约占0.8KB NV空间,三次2.4KB
#define MAX_VP_TEMPLATE_NUM 3
//注册声纹时最大超时等待时间(秒)
#define MAX_VP_REG_TIME 10 3. 声纹注册算法请把external\model\vpr(声纹注册)中[60001]VPR_model_v00xx.bin算法模型,复制到projects\CI13XX_SDK_ALG_PRO_Vx.x.x\firmware\dnn文件夹中
注意
- 声纹注册算法,涉及收费,需烧录license,具备license的芯片正常运行,无license的芯片每五分钟会进行复位,如有量产需求,请联系启英泰伦商务。
- 固件打包时,如果NV data分区空间过小,影响模板数据存储,导致无法正常识别已注册的声纹。
- 声纹注册需搭配该算法的前端算法模型使用。
4. 声纹注册结果说明:
声纹注册和注册以后的识别结果在vpr_callback回调函数中,该函数位于CI-SDK-ASR-ALG_Vx.x.x\projects\components\VPR\voice_print_recognition.c中,如下图:
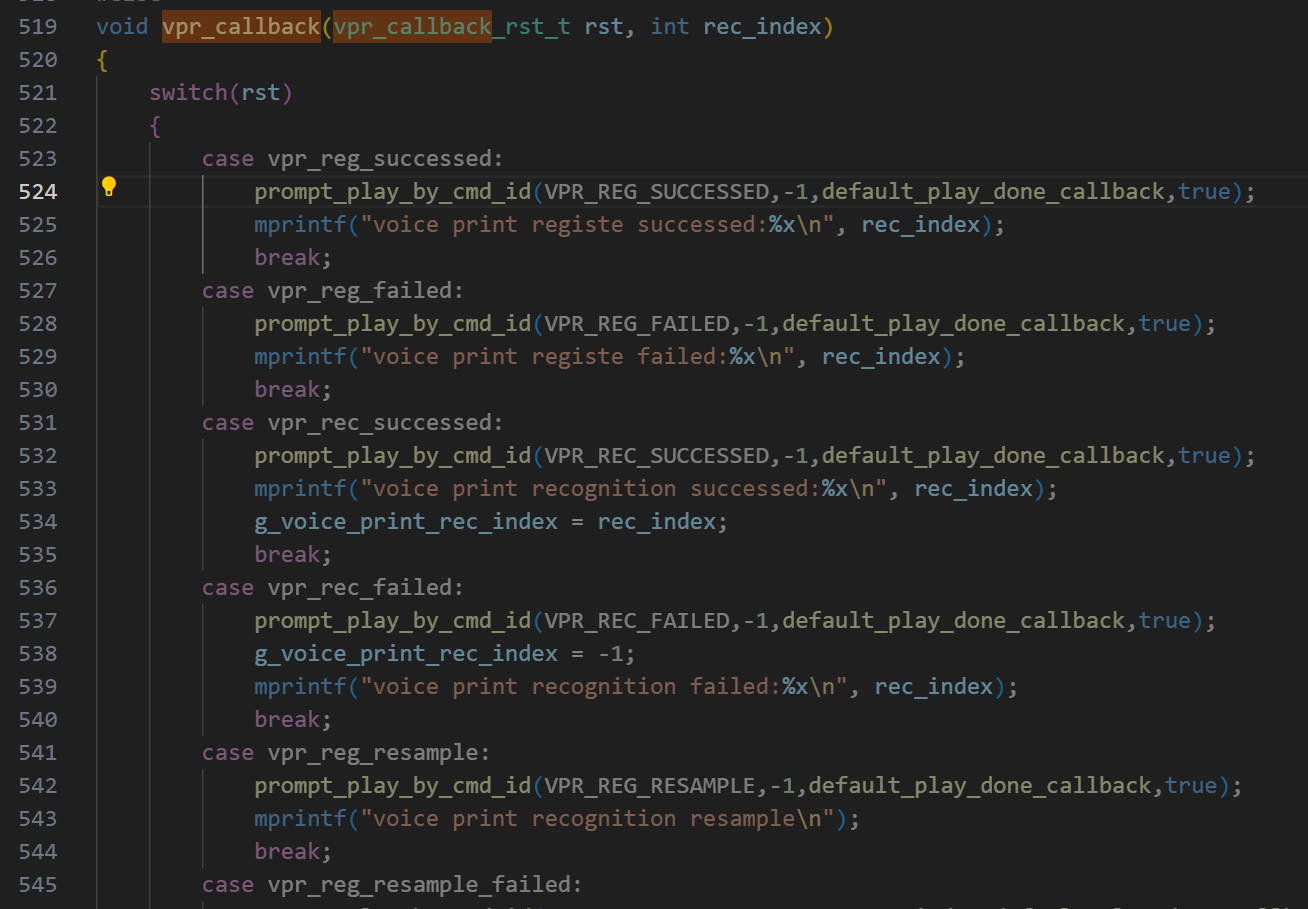
vpr_callback函数参数rst:表示返回当前注册状态,reg_index:表示当前注册到第几个模版
rst注册状态有如下几类:
typedef enum{vpr_reg_successed, // 注册成功vpr_reg_failed, // 注册失败vpr_rec_successed, // 识别成功vpr_rec_failed, // 识别失败vpr_reg_resample, //继续重复录入声纹vpr_reg_resample_failed //重复录入失败(注册一个模板可能需要录入多次)。}vpr_callback_rst_t;用户可以根据rst状态在对应的case添加后续对应需要执行的逻辑代码,示例中只对当前注册和识别状态做了对应的结果进行了播报。
讯飞平台声纹识别方案:
参考资料:
1.声音识别(声纹识别)与语音识别:技术边界与应用场景的深度解析
https://developer.baidu.com/article/detail.html?id=3694515