作业1
## 代码以及相关图片
点击查看代码
import requests
from bs4 import BeautifulSoup#原本想把第一个页面设为base_url,之后以此为根据跳转其他页面的(获取排名31之后的学校信息),可惜未能做到
base_url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
response = requests.get(base_url)#用get方法发出请求
response.encoding = 'utf-8'#此处是为了避免乱码现象# 把页面信息变成bs4对象
page = BeautifulSoup(response.text, 'html.parser')
#爬取学校排名所在的表格,并存储在table中
table = page.find('table', class_='rk-table')
tbody = table.find('tbody')
#取出表格中每一行的信息,存储在trs中
trs = tbody.find_all('tr')result = []
result_num = 0
#遍历表格的每一行
for tr in trs:result.append([])j = 1i = 1#遍历一行中每一个单元格for td in tr.find_all('td'):if j > 5:breakif j == 1:ranking = 'ranking top' + str(i)i += 1#把排名号码存储在结果列表里result[result_num].append(tr.find('div', class_='ranking').text.strip())elif j == 2:#把学校名称存储在结果列表里result[result_num].append(tr.find('span', class_='name-cn').text.strip())elif j == 3:# 把学校所在地存储在结果列表里result[result_num].append(td.text.strip())elif j == 4:# 把学校类型存储在结果列表里result[result_num].append(td.text.strip())elif j == 5:#把学校总分存储在结果列表里result[result_num].append(td.text.strip())j += 1result_num += 1#通过列表的方式输出结果
for num in result:print(num)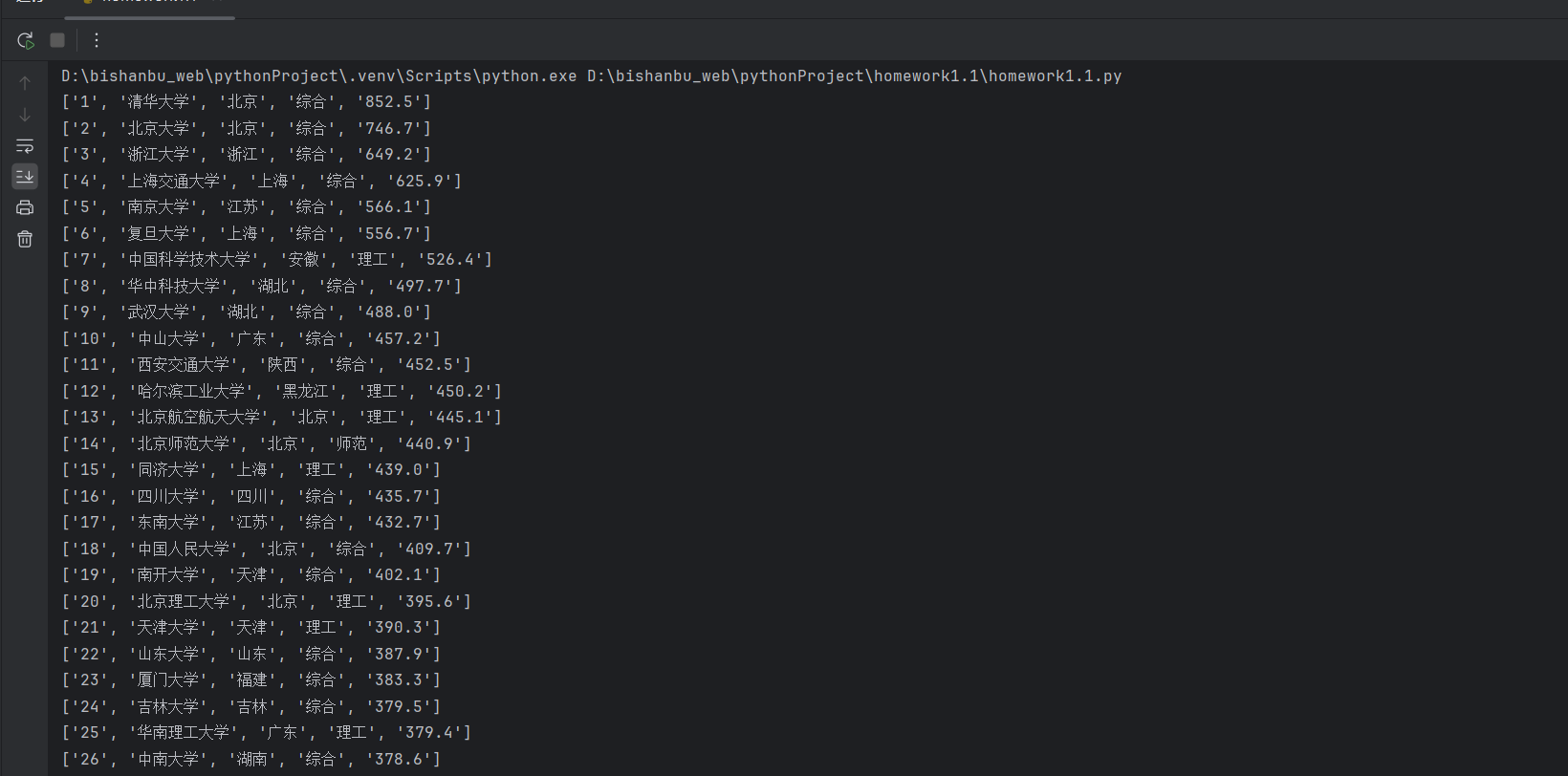
## 作业心得体会
通过这次作业我了解到了很多前端的知识,明白了网上那么多好看的网页是怎么制作出来的,以及我还学到了爬取网页信息最基本的知识,明白了bs4模块的工作原理。
作业2
## 代码以及相关图片
点击查看代码
import requests
import re
#这里是当当网的url
url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input"headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0'
}
resp = requests.get(url,headers=headers)#为正则表达式创建一个容器
pattern = re.compile(r'<li ddt-pit.*?<a title="(?P<name>.*?)".*?<span class="price_n">(?P<price>.*?)</span>',re.S)
#html是网页源代码
html = resp.text
#创建一个迭代器
result = re.finditer(pattern,html)
#创建一个名为goods的列表,用于存放商品的名称和对应的价格
goods = []
i = 0
#遍历迭代器,并把爬取到的商品信息放进goods列表里
for match in result:goods.append([match.group('name')])goods[i].append(match.group('price')[5:])i += 1
#一行行地输出商品信息
for good in goods:print(good)
代码输出结果:
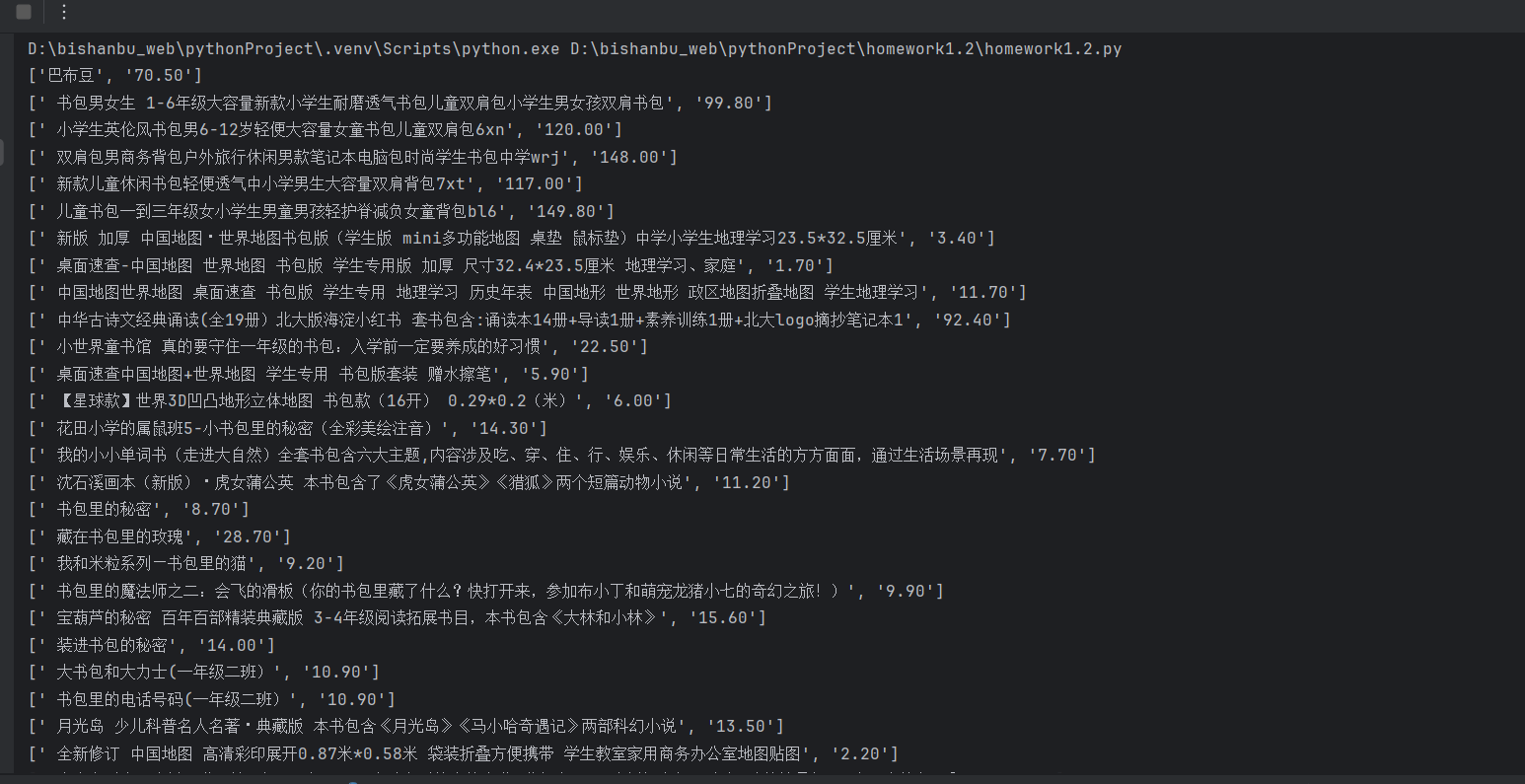
## 作业心得体会
通过这一次的作业,我学到了re模块和正则表达式的用法,并且可以独立用正则表达式爬取网页信息,但是通过这次作业我发现很多网站的反爬机制真的很强大,很难爬取到,因此我们要学习的爬虫相关知识还是有很多。
作业3
## 代码以及相关图片
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin# 导入福州大学新闻网相关网页的url
url = "https://news.fzu.edu.cn/yxfd.htm"
# 设置图片保存目录
save_dir = "homework1.3.images"# 判断图片保存目录是否存在,若不存在就要自己创建
if not os.path.exists(save_dir):os.makedirs(save_dir)resp = requests.get(url) # 网页未设置反爬手段,因此不需要headers
resp.encoding = 'utf-8' # 此处的编码格式若不设置会出现乱码
html = resp.text # html中保存网页代码
# print(html) # 这里把try的步骤改成了直接测试
page = BeautifulSoup(html, 'html.parser') #把网页内容转换成bs4对象imgs = page.find_all('img') # 获取页面中所有的图片,并存在imgs中count = 0
# 一个个遍历爬取到的图片
for img in imgs:img_src = img.get('src') #获取图片连接if not img_src: # 若遇到没有连接的图片直接跳过continue# 把相对路径转换为绝对路径full_img_src = urljoin(url, img_src)# 检查图片格式是否为JPEG、JPG或PNG,如果不是直接跳过if not (full_img_src.lower().endswith(('.jpg', '.jpeg', '.png'))):continue# 开始下载图片img_response = requests.get(full_img_src, timeout=10)# 获取图片扩展名if full_img_src.lower().endswith('.png'):ext = '.png'else: # jpg或jpegext = '.jpg'# 保存图片img_name = f"image_{count}{ext}"img_path = os.path.join(save_dir, img_name)count += 1 # 计算总共保存了多少张图片with open(img_path, 'wb') as f:f.write(img_response.content)print(f"已保存: {img_name} ({full_img_src})")print(f'总共保存了{count}张图片')运行结果:
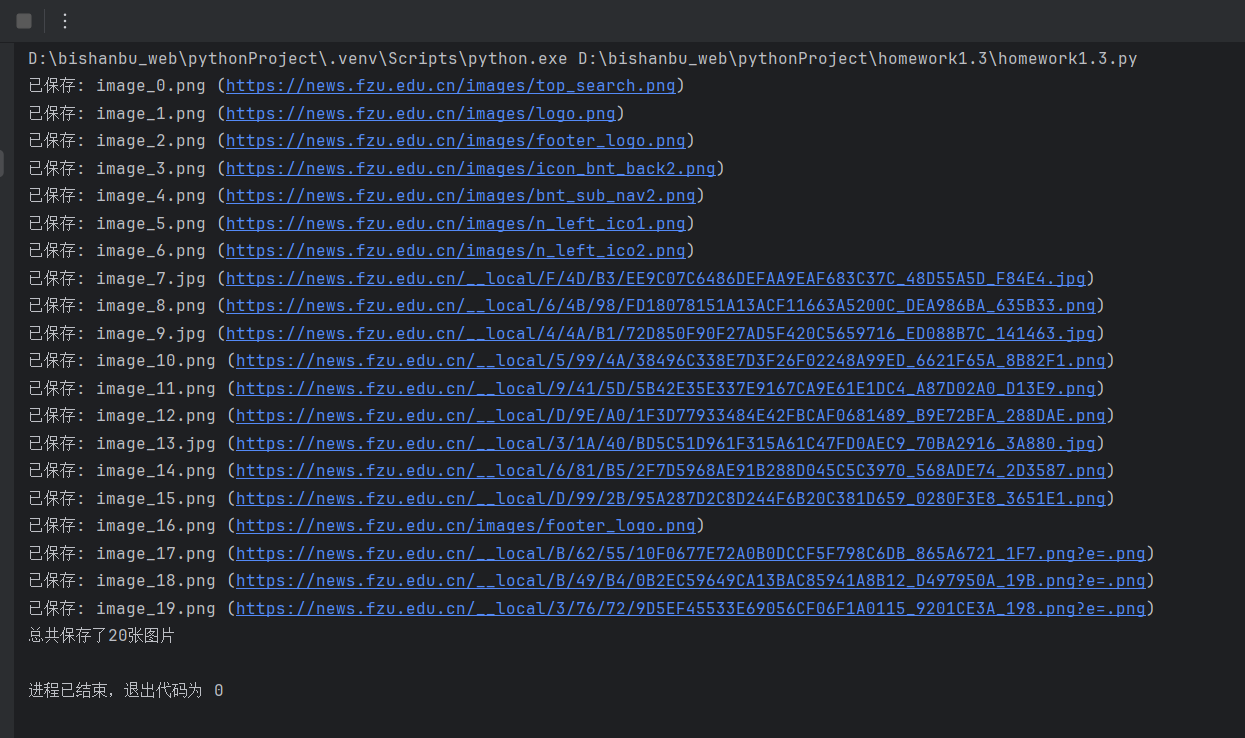
## 作业心得体会
通过这一次的作业我学会了从网上爬取图片的方法以及原理。