全文降AI的好处:从知网检测算法角度解读为什么要全文处理
2026年的毕业季,知网AIGC检测已经成了大多数高校的标配。很多同学论文写完之后第一件事不是找导师看,而是先查一下AI率。
问题来了:查完之后发现AI率偏高,应该怎么处理?
目前最主流的两种方案:一是手动逐段修改,二是用工具做全文降AI。从大量实际案例来看,全文降AI的效果远好于手动修改。但很多人不理解为什么——"不都是改文字吗,为什么全文改就比局部改效果好?"
这篇文章我们从知网AIGC检测算法的具体逻辑出发,来拆解全文降AI的好处到底体现在哪里。

知网AIGC检测算法的三层检测逻辑
知网的AIGC检测不是一个简单的模型,而是多层检测机制的组合。理解这几层机制,你才能明白为什么全文处理是最优解。
第一层:Token级困惑度扫描
这是最底层的检测。系统会把你的文本切分成token(可以简单理解为"词元"),然后逐个计算每个token出现的概率。
AI生成文本的特点是:大部分token都是"高概率"选项——也就是说,在给定上文的情况下,AI总是选择最"正确"、最"标准"的下一个词。这导致整体困惑度偏低。
知网的系统会统计全文的困惑度分布。如果一篇文章的困惑度长期处于低位,几乎没有"意外"的词汇选择,那就会被标记为高AI疑似。
第二层:段落级风格一致性分析
这一层是局部修改的"克星"。
知网的系统会将文章分成若干段落(通常以自然段或固定字数为单位),分别计算每个段落的语言特征值。然后比较段落之间的特征差异。
正常的人类写作,段落间的语言特征会有自然的波动——比如方法论部分可能比较严谨刻板,讨论部分可能更灵活开放。但这种波动是渐进的、有逻辑的。
而局部修改后的论文,改过的段落和没改的段落之间会出现突变性的风格跳跃。这种跳跃在检测系统看来,要么是拼凑的,要么是AI和人类混合写作的——不管哪种解读,都会提高AI疑似率。
第三层:全文级语义连贯性评估
知网的检测系统还会从宏观层面评估全文的语义连贯性。包括:
- 论点的推进是否逻辑清晰
- 论据和论点之间的支撑关系是否自然
- 术语使用的一致性
- 过渡段/过渡句的使用模式
AI生成的文章在这些方面往往"过于完美"——逻辑严丝合缝,过渡句像教科书一样标准。这种"完美"本身就是一个检测信号。

为什么全文降AI能同时应对三层检测
理解了知网的三层检测逻辑,全文降AI的好处就很清楚了:
应对第一层:全局困惑度重塑
全文降AI工具会对整篇文章的词汇选择模式进行调整,有策略地引入"低概率但合理"的表达方式,让整篇文章的困惑度分布从"AI型"变成"人类型"。
关键在于"全局"二字。如果只改部分段落,那改过的段落困惑度升高了,没改的段落还是低困惑度,整体分布反而更不自然。全文处理能确保困惑度分布在整篇文章范围内是均匀变化的。
应对第二层:消除风格断层
这是全文降AI最大的优势。因为整篇文章都经过同一套处理逻辑,处理后的文本在段落间不存在风格突变。每一段的语言特征值变化是渐进的、连续的,完全符合人类写作的特征。
打个比方:局部修改就像给一面墙补了几块不同颜色的砖,远看就知道修过。全文降AI是把整面墙重新粉刷一遍,颜色统一,看不出痕迹。
应对第三层:保持语义连贯的同时降低"完美度"
好的全文降AI工具会在保持论证逻辑的前提下,适当打破AI那种"过于标准"的语义结构。比如:
- 让某些过渡句更简短直接,而不是每次都用"基于上述分析,可以得出…"
- 让某些段落的论证更紧凑,某些更展开,制造自然的"不均匀"
- 适当使用一些非模式化的表达
这些调整不会影响论文的学术质量,但能有效降低知网第三层检测的AI疑似判定。

实际案例:知网检测结果对比
以下是一些真实的知网AIGC检测结果对比:
案例一:管理学硕士论文,3.2万字
- 原始AI率:45.3%(知网)
- 手动改写5天后:33.8%(降了但不够)
- 再手动改3天:36.2%(反弹了)
- 使用全文降AI工具后:4.1%(一次到位)
案例二:计算机本科毕业设计,1.8万字
- 原始AI率:58.6%(知网)
- 局部改写后:51.2%(基本没效果)
- 使用全文降AI工具后:3.7%
案例三:教育学博士论文,8.5万字
- 原始AI率:31.2%(知网)
- 使用全文降AI工具后:6.8%
- 处理耗时:约4小时
规律很明显:不管初始AI率多少,全文降AI工具都能稳定地降到10%以下。而手动局部修改的结果不确定性很大,经常出现反弹。
针对知网检测效果好的全文降AI工具
并不是所有降AI工具都能很好地应对知网检测。知网的算法相对其他平台更严格,需要工具有更强的全文处理能力。
嘎嘎降AI(aigcleaner.com)
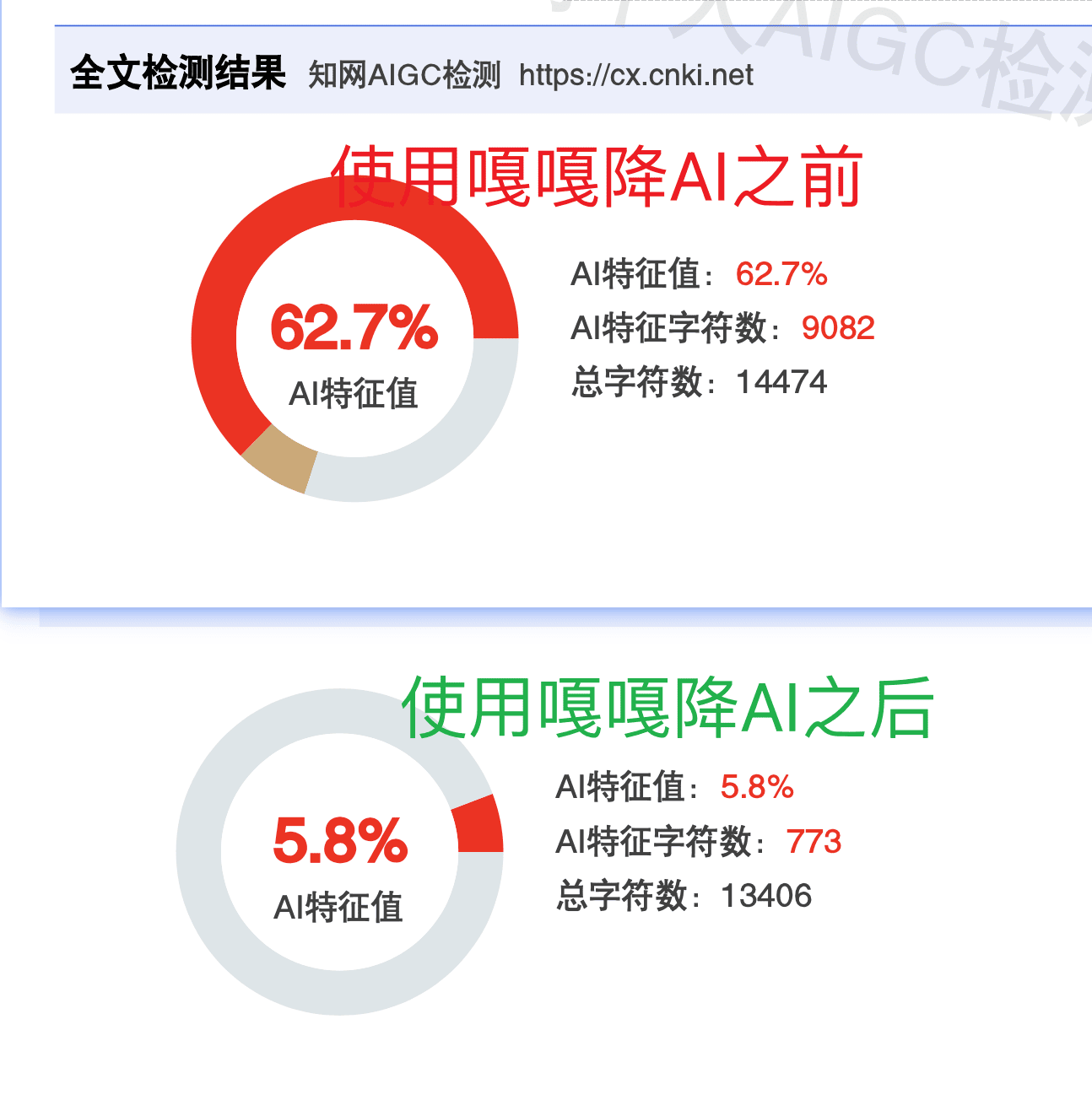
在知网检测场景下,嘎嘎降AI的表现非常亮眼。实测数据显示知网AI率从62.7%降到5.8%,这个降幅在行业里属于第一梯队。
嘎嘎降AI支持9个检测平台,但从用户反馈来看,它对知网的适配做得特别好。可能是因为知网是最主流的平台,嘎嘎降AI在知网方向投入了更多的研发资源。
比话降AI(bihua.co)
比话降AI的"AI率高于15%全额退款+检测费"承诺,针对的就是知网检测。也就是说,用比话处理后的论文拿到知网去检测,AI率如果超过15%,不仅退款还报销检测费。
这个承诺对用户来说非常友好。知网检测一次也不便宜,比话愿意承担这个成本,说明它对自己在知网场景下的效果非常有信心。
另外比话支持10万字的论文,博士生写的大部头也能处理,这一点很重要。

率零(lv0.ai)
率零在知网场景下也有不错的表现。它的优势在于改写后的文本非常自然,不会出现"机翻感"。对于文科类论文来说,改写的自然度很重要——因为导师通读论文时,如果感觉表达很奇怪,即使AI率低也会让你改。

知网检测的几个"坑"你要知道
在用全文降AI工具之前,有几个关于知网检测的"坑"需要提前了解:
1. 知网检测结果有波动
同一篇论文,间隔一两天再查,AI率可能会有1-3个百分点的浮动。这是正常的,因为知网的模型也在持续更新。所以不要因为查了两次结果不一样就慌,关注大趋势而不是具体数字。
2. 不同版本的知网检测结果不同
知网目前有多个检测入口,价格和算法版本可能不完全一样。建议使用学校指定的检测入口,或者使用最新版本的检测。
3. 参考文献格式会影响检测
如果你的参考文献格式不规范(比如没有用知网标准的引用格式),检测系统可能无法正确识别引用部分,把引用的文字也算进AI检测范围。在做全文降AI之前,先把参考文献格式整理好。
4. 图表说明文字容易被误判
表格标题、图片说明这些短文本,由于表达方式比较固定("如表1所示""图2展示了…"),容易被检测为AI生成。这部分其实是正常的学术写作规范,全文降AI工具通常会识别并保护这些内容。
2026年知网算法升级对全文降AI的影响
知网在2026年对AIGC检测算法做了几次升级,主要变化包括:
- 上下文分析窗口更大:以前可能看前后各3段,现在看前后各5段甚至更多
- 对混合写作的检测更敏感:专门针对"AI写+人改"这种模式做了优化
- 学科模型细化:不同学科的检测模型参数有差异化调整
这些升级对局部修改来说是坏消息——上下文窗口越大,局部修改的风格断层越容易被检测出来。对"AI写+人改"的混合写作检测更敏感,更是直接针对手动修改这种方式。
但对全文降AI来说,这些升级的影响相对较小。因为全文降AI本来就不存在风格断层,也不是"AI写+人改"的模式。只要工具的处理效果能让整篇文章的语言模式接近人类写作,不管算法怎么升级,结果都是稳定的。
这也是为什么我说全文降AI是面向未来的策略——它不是在"骗"检测系统,而是从根本上改变了文本的语言特征。
写在最后
从知网检测算法的角度看,全文降AI的好处可以归结为一句话:它是唯一能同时应对知网三层检测机制的方案。
困惑度检测?全文降AI能全局重塑困惑度分布。风格一致性检测?全文降AI天然没有风格断层。语义连贯性检测?全文降AI能在保持逻辑的同时降低"AI完美度"。
如果你的论文要过知网检测,与其花好几天手动改还可能越改越高,不如直接用嘎嘎降AI、比话降AI或率零做一次全文处理,省时间、效果好、结果稳。