作业①:要求:使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
1.代码以及实践过程
1.1 分析页面
首先获取对应xpath(整个表格、对应每行每个股票、对应每列)
通过分析,获得了核心的定位对象
股票数据表格://[@id="mainc"]/div/div/div[4]/table
数据行://[@id="mainc"]/div/div/div[4]/table/tbody/tr
数据列://*[@id="mainc"]/div/div/div[4]/table/tbody/tr/td[索引],其中根据索引的不同可以匹配到不同的信息
1.2 使用Selenium框架
进行浏览器初始化
def __init__(self):self.driver_path = r"D:\悦读书\数据采集\chromedriver.exe"self.options = webdriver.ChromeOptions()self.service = Service(executable_path=self.driver_path)self.driver = webdriver.Chrome(service=self.service, options=self.options)self.wait = WebDriverWait(self.driver, 15)
进入东方财富相应页面之后,留出20秒时间给到需要人工操作的地方,如可能出现的广告以及滑块验证
def crawl_single_plate(self, plate_info):plate_name, plate_url = plate_infoself.driver.get(plate_url)time.sleep(10)
进行对应数据的定位、爬取
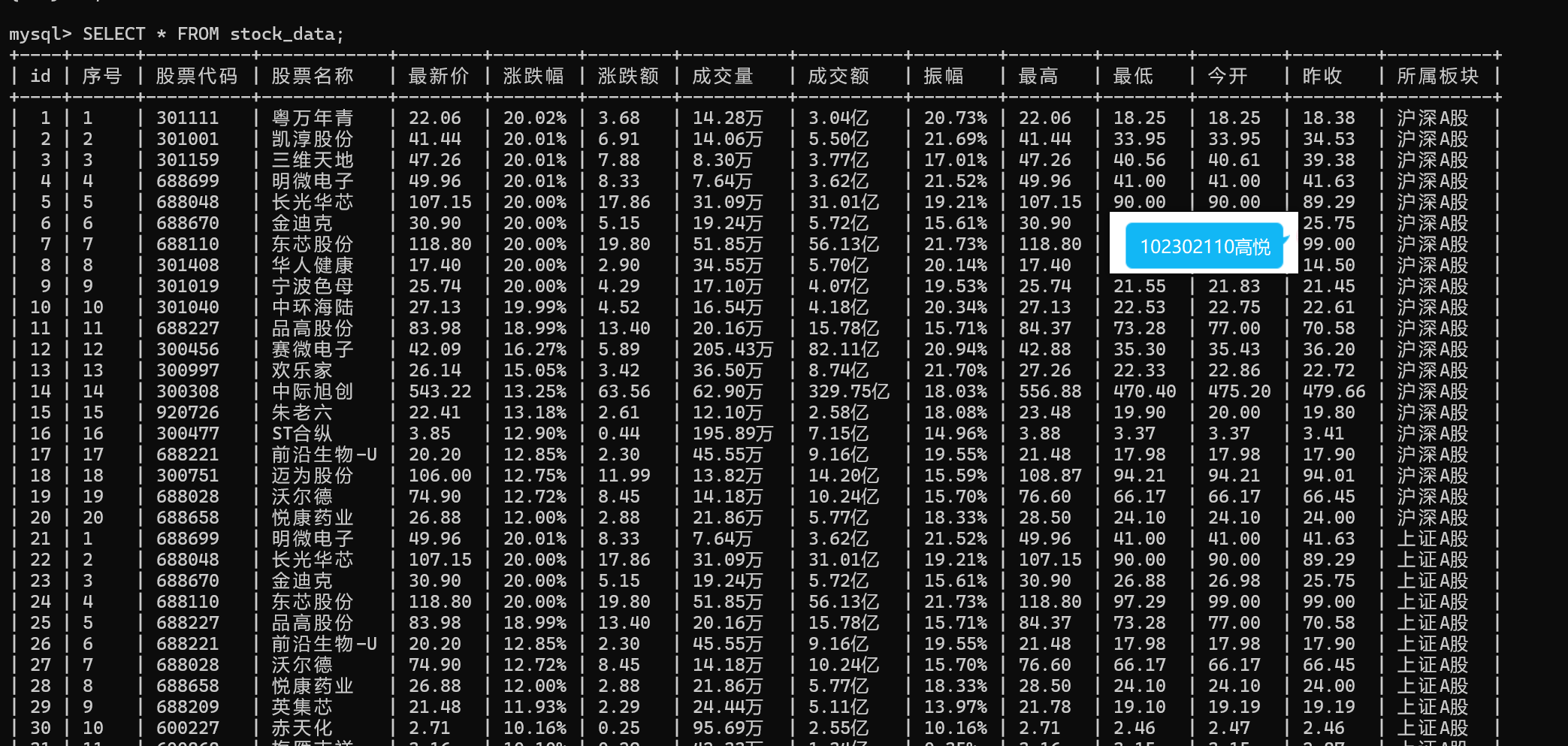
def get_stock_data(self, plate_name):try:table = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="mainc"]/div/div/div[4]/table')))rows = table.find_elements(By.XPATH, './/tbody/tr')valid_rows = [row for row in rows if len(row.text.strip()) > 0]stock_list = []for row in valid_rows[:20]:cols = row.find_elements(By.TAG_NAME, "td")if len(cols) >= 14:stock = {"序号": cols[0].text.strip(),"股票代码": cols[1].text.strip(),"股票名称": cols[2].text.strip(),"最新价": cols[4].text.strip(),"涨跌幅": cols[5].text.strip(),"涨跌额": cols[6].text.strip(),"成交量": cols[7].text.strip(),"成交额": cols[8].text.strip(),"振幅": cols[9].text.strip(),"最高": cols[10].text.strip(),"最低": cols[11].text.strip(),"今开": cols[12].text.strip(),"昨收": cols[13].text.strip(),"所属板块": plate_name}stock_list.append(stock)return stock_listexcept Exception as e:return []
gitee链接:https://gitee.com/augtrqv/shoren/blob/master/作业4/第一题.py
2.心得体会
本来想直接复制上次使用scrapy的核心代码进行修改,但是发现两次的要求不同,上次是通过json进行爬取网页的数据,而这次是使用xpath来进行定位。而另外使用Selenium框架来模拟人工使用浏览器,其中反爬验证本来想用代码进行操作,但是感觉随机性太高,最后还是留给了自己操作。
作业②:使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
1.代码以及实践过程
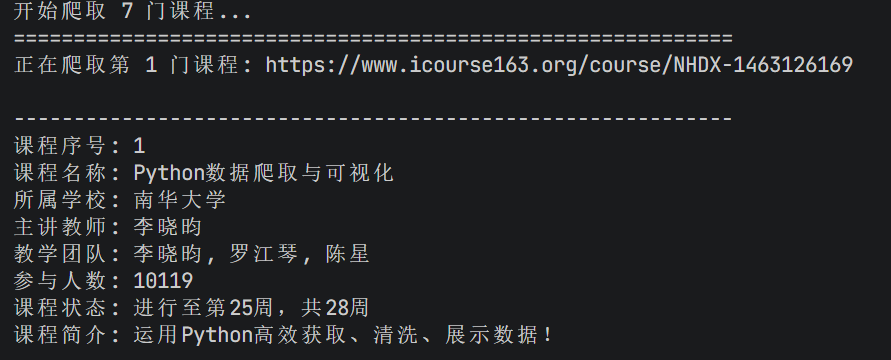
课程名称

学校名称

主讲教师

课程进度

参加人数
课程简介

终端输出
数据库输出

gitee链接:https://gitee.com/augtrqv/shoren/blob/master/作业4/第二题.py
2.心得体会
关于本题我尝试了很多方法,一开始我想直接从主页进行爬取课程信息,然后再通过可能隐藏的链接进入课程详情页爬取课程介绍等信息。但我发现很难找到课程详情页的链接,并且想要精准定位到我想要爬取的那几门课程也很困难,因为主页的大部分内容在好几个
作业③:掌握大数据相关服务,熟悉Xshell的使用
1.实验过程
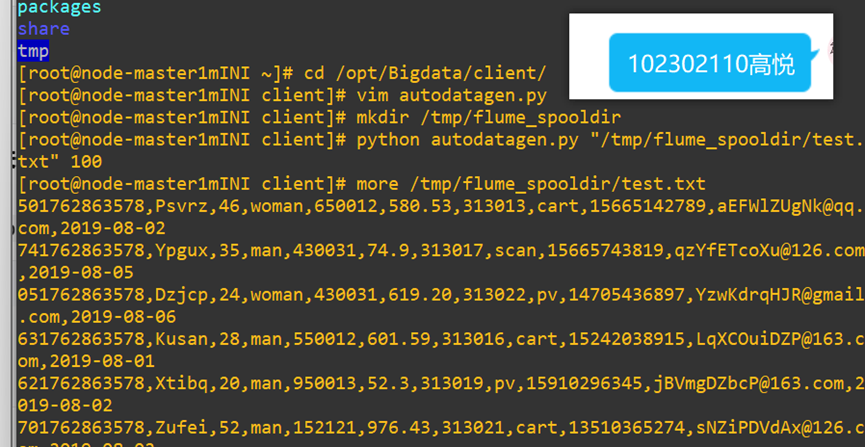
1.1 任务一:Python脚本生成测试数据
1.2 任务二:配置Kafka

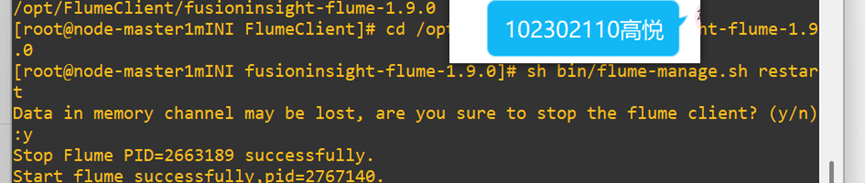
1.3 任务三: 安装Flume客户端
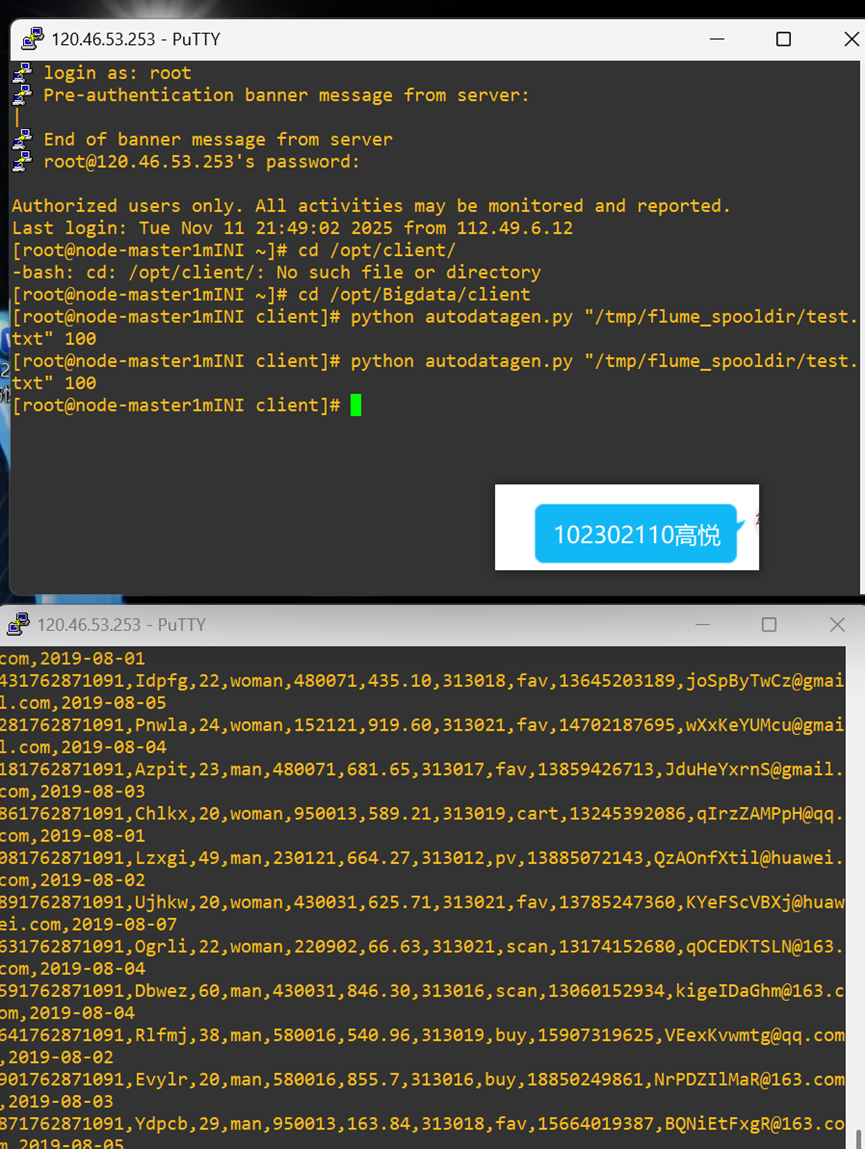
1.4 任务四:配置Flume采集数据
2.实验心得:本次华为云 Flume 日志采集实验,让我掌握了 MapReduce 开通、Python 造数、Kafka 与 Flume 配置等实操技能。实操中因配置文件语法错误遇采集失败,排查后深刻体会到大数据组件参数精准的重要性,也熟悉了 Xshell 运维操作,理解了实时数据采集链路的核心逻辑。