摘要:LangGraph的State传递与Channel传递是AI Agent工程面试的高频核心问题。

面试官抬了一下眼皮,问了一句看似简单的话:"说说你对State传递和Channel传递的理解,两者在LangGraph里是怎么配合的?"你张了张嘴,感觉答案在嘴边但又有点模糊。
最后憋出来的回答是"State是共享状态,Channel是通道"——面试官点了点头,但追问的手已经伸过来了:"那如果两个节点同时写同一个key,Reducer怎么处理的?
大佬一开口,先坐直
你用过自定义Reducer吗?"然后就是一路往下追,直到某个你说不清楚的边界条件当场卡壳。

这锅先别急着往我头上扣
这大概是LangGraph八股文里翻车频率最高的一道题。它不像Tool Calling那样有大量实战案例可以讲,也不像RAG那样容易找到直观的项目素材。
很多候选人的状态管理知识是碎的:知道State是个字典,知道Channel负责传递消息,但不清楚Reducer在其中扮演什么角色,也不理解为什么StateGraph和MessageGraph在底层走了两条完全不同的路。
更要命的是,面试官一旦顺着Reducer问下去,"last-write-wins"这个默认行为就成了很多人答不上来的黑洞。
这篇专题把State传递和Channel传递这件事从根子上讲清楚,目标是让你面试时不仅能答出来,还能主动引导面试官往你准备过的方向走。
一、基础概念:什么是State,什么是Channel
1.1 State的本质:一个共享的、可更新的字典
在LangGraph里,State不是一个独立存在于某个节点内部的变量,而是一个在整张图里共享的中央字典。每个节点在执行时做的第一件事,是从这张图的状态字典里读取当前值;
做的最后一件事,是把自己的更新写回去。这个读写过程不是直接修改共享对象,而是通过Reducer函数来控制的。
具体来说,每次节点返回的值会经过Reducer的聚合逻辑,才写入State。
举例来说,如果你在构建一个多步骤的研究Agent,第一步节点可能返回{"research_results": "...", "query": "..."},第二步节点返回{"analysis": "..."},Reducer会把这两个返回值合并成一个字典,而不是让第二步直接覆盖第一步的结果。
这个合并过程默认是浅层的key覆盖,但Reducer可以被自定义成深拷贝、列表追加、时间戳合并等任意策略。
理解State的关键在于:State是一个单例(singleton),整张图共享同一个实例,但写入方式是聚合式的,而不是替换式的。
这和传统编程里变量赋值的语义完全不同——后者是直接覆盖,前者经过了Reducer的二次加工。
1.2 Channel的本质:一个受管的、有序的读写队列
Channel在LangGraph里承担的是节点间消息传递的基础设施角色。和State不同,Channel不是一张共享字典,而是一组受管的读写队列。
每个节点通过Channel与相邻节点通信,数据沿着边的方向流动,最终影响State的更新。
更准确地说,Channel定义了三件事:第一,数据的来源节点;第二,数据的目标节点;第三,数据在传递过程中经过的中间格式。
当LangGraph执行invoke或stream时,它实际上在做这样一件事:读取Channel队列里的最新消息,结合当前State,执行目标节点的逻辑,然后把返回值经过Reducer写回State,同时可能往下一个Channel队列里写入新消息。
这里容易出现第一个认知陷阱:很多人把Channel理解成消息队列(比如RabbitMQ或Kafka那种),但实际上LangGraph的Channel是一个受管的内存数据结构,它没有持久化、没有ACK机制、没有消费组概念——它是专为LangGraph运行时设计的一种轻量通信原语。
把Channel当成外部消息队列来理解,会导致你在设计状态持久化和故障恢复时做出完全错误的判断。
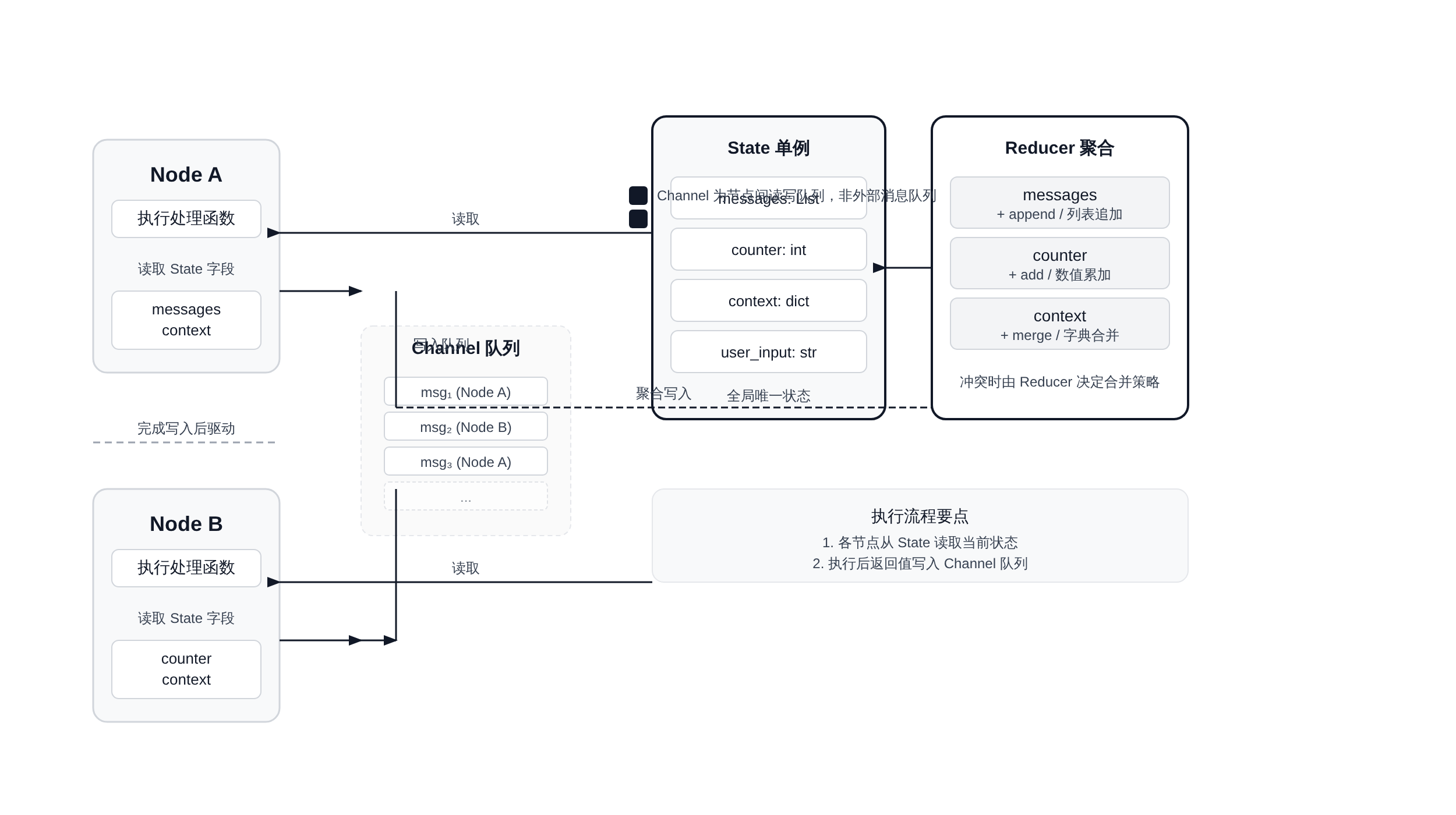
1.3 State与Channel的协作关系:一个图解
下面这张图展示了State、Channel和Reducer在实际执行流程中的协作关系。箭头代表数据流向,实线框代表写入动作,虚线代表读取动作:
正文图解 1
执行顺序的完整描述是这样的:LangGraph启动时从Checkpoint读取初始State(如果是恢复场景);然后根据输入,沿着Channel触发第一个节点的执行;
节点逻辑完成后返回一个dict,这个dict经过Reducer才写入State,同时更新下一个Channel队列的状态;
如果下一个节点配置了conditional边,LangGraph会读Channel的最新值决定走哪条分支;整个循环持续到没有更多可执行节点为止。
理解这张图的关键是:State是最终一致性的存储层,Channel是驱动节点执行的消息流,而Reducer是把节点返回值变成State写入的那道门。三个角色缺一不可,而且各自有不同的设计自由度。
二、Reducer函数:State聚合的真正核心
2.1 默认Reducer:last-write-wins机制
如果候选人从来没听说过Reducer,最常见的误解是:两个节点同时返回{"status": "done"},最后State里就是status=done。
这个理解对了一半——默认行为确实如此,但原因不是因为"后写的覆盖先写的",而是因为LangGraph默认使用了一个叫做last-write-wins的Reducer函数。
默认Reducer的行为是:对于每个key,取最后一个写入的值。"最后一个"的定义由节点执行顺序决定,而不是写入时的时间戳。
换句话说,如果你用.send或者在同一个节点里返回了多个更新,默认Reducer会按你返回的顺序依次处理,最后一个覆盖前面的。
但如果你配置了并发边(parallel edges),两个分支节点同时执行,这时候"最后一个"的行为就变得不确定了——取决于图执行器的调度顺序,而这在大多数情况下是不可预测的。
这个默认行为在简单场景下完全够用,但一旦涉及多节点并发写入同一个key,候选人就需要知道:默认Reducer并不能保证一致性,需要自己设计Reducer策略。
2.2 自定义Reducer:append、merge与自定义函数
LangGraph允许用户为每个State字段单独指定Reducer函数。
这意味着你可以让history字段用列表追加策略,让analysis字段用覆盖策略,让metadata字段用深度合并策略——同一个State里,不同key可以走完全不同的聚合逻辑。
最常见的自定义Reducer有三种模式:
列表追加型(append):适用于消息历史、对话记录这类需要保留全量数据的字段。比如:
def append_reducer(existing, new):if existing is None:return [new]if isinstance(existing, list):return existing + [new]return [existing, new]# StateSpec中这样使用:
builder = StateGraph(AgentState)
builder.add_node("researcher", researcher_node)
builder.add_node("writer", writer_node)# history字段使用追加Reducer
builder.add_edge("researcher", "writer")
追加型Reducer的典型应用场景是让一个研究员节点输出{"step": "research", "findings": [...]},紧接着一个分析节点输出{"step": "analysis", "insights": [...]},两者都追加到同一个history字段,最终State里保留完整的执行链路记录。
这种模式对于事后复盘和可观测性至关重要。
深度合并型(deep merge):适用于配置对象这类需要逐层合并的字段。
比如一个Agent的配置可能是多层嵌套的,如果研究员节点只改了model.temperature,写手节点只改了output_format,深度合并Reducer会保留两者的改动,而不是让后写的节点完全覆盖前一个节点的所有配置。
时间戳合并型(timestamp merge):适用于需要保留"最新有效值"的场景。
比如多个节点可能报告同一个指标的中间结果,时间戳合并Reducer只保留时间戳最新的那个,这在监控和流式数据处理场景里很有用。
2.3 Reducer的面试应答模板
面试官问Reducer的目的通常不是考你API调用,而是想看你有没有理解"状态一致性"这个命题。以下是一套可以直接开口的应答框架:
30秒快速版:"Reducer控制的是多个节点返回值写入同一个State key时的合并策略。
LangGraph默认用last-write-wins,即最后一个写入的值生效。
但你也可以给每个字段单独配置Reducer,比如history字段用列表追加,metadata字段用深度合并——这样不同字段可以有不同的聚合规则,更灵活地表达业务语义。"
展开追问版:如果面试官继续追问"那你遇到过Reducer冲突的问题吗",标准答案是:"在并发边场景下,如果两个分支节点同时更新同一个字段,默认Reducer的执行顺序是不确定的。
我会在设计StateSpec时提前避免这种并发写同key的情况,比如通过条件边分流,或者给不同分支分配不同的State字段。
另外,如果业务上确实需要合并,我会实现一个自定义Reducer比如带版本号的时间戳合并。"
这个回答模板有两个关键点值得注意:第一,不仅说出了默认行为,还说出了"为什么不总是用它";第二,不仅描述了解决方案,还给出了设计阶段就避免问题的思路。
面试官要筛的不是会查文档的候选人,而是有系统性思考能力的工程师。
三、StateGraph vs MessageGraph:两种状态模型的底层差异
3.1 通信语义对比:共享状态 vs 消息序列
StateGraph和MessageGraph不是两个平行的API选项,而是两种完全不同的状态哲学。它们的区别本质上回答了同一个问题:当多个节点需要协作完成一个任务时,它们之间靠什么来共享信息?
StateGraph的回答是:靠共享的State字典。
所有节点都读写同一个状态对象,信息通过Reducer聚合传递,节点之间不需要直接知道彼此的存在,只需要知道如何操作State里的字段。
这种方式的优势是表达能力强,适合那种"所有步骤都在改同一个业务对象"的场景——比如一个订单处理流程,节点A更新订单状态,节点B读取订单状态再添加物流信息,节点C做最终校验,三个节点通过共享State协同,不需要彼此直接调用。
MessageGraph的回答是:靠消息序列。每个节点接收的输入是一系列历史消息的列表,而不是一个共享字典。
消息按时间顺序排列,节点的任务是从消息历史中提取信息,然后产生下一条消息。
这种方式的灵感来自通信理论里的"消息传递"模型,在LLM领域对应的是那种"把完整对话历史喂给模型"的经典做法。
MessageGraph天然适合多轮对话类Agent,因为对话本身就是消息序列,而不是共享状态。
下面这张图把两种模型的输入输出做了直接对比:
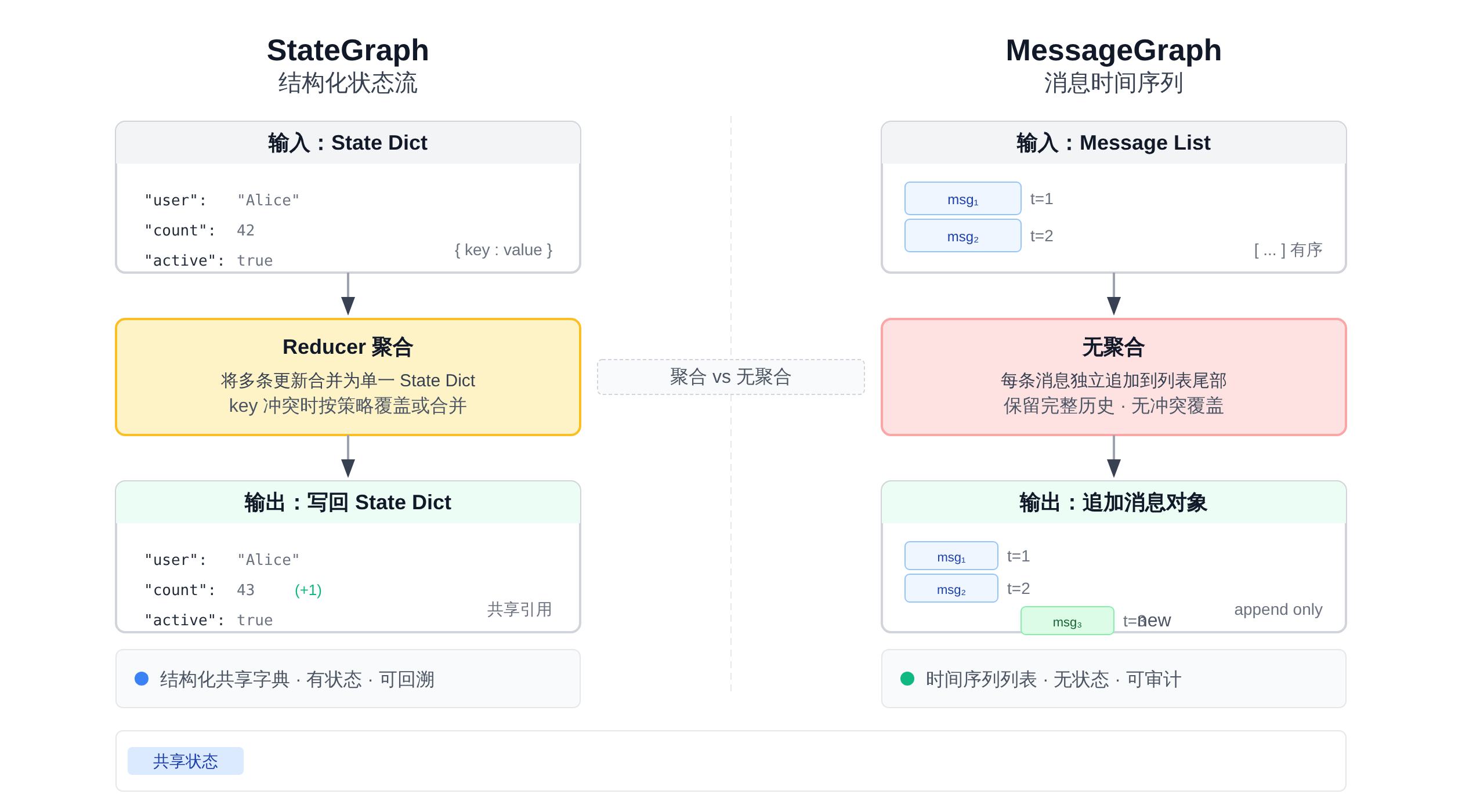
正文图解 2
两种模型在API层面有一个关键差异值得记住:StateGraph的StateSpec可以完全自定义字段和Reducer策略,而MessageGraph的StateSpec默认只有一个messages字段,类型是Annotated[list, add_messages_graph],这是一个预置的Reducer——本质上就是把你的消息追加到一个列表里。
这意味着在MessageGraph里,你几乎不需要自己写Reducer,因为整个状态模型就围绕消息追加设计的。
3.2 Reducer的作用差异:聚合 vs 不聚合
在StateGraph里,Reducer是你必须理解和主动设计的组件。
状态聚合的策略直接影响业务逻辑的正确性——如果你把一个需要追加历史的字段配置成了默认的last-write-wins,数据就会莫名其妙地丢失,debug起来非常痛苦。
在MessageGraph里,Reducer的存在感被大幅弱化了。
add_messages_graph是框架内置的消息追加函数,它做的事情非常直接:对于同一个消息ID,如果消息已经存在就更新,如果不存在就追加。
它不处理冲突,不做去重(除非你手动实现消息ID逻辑),也不提供条件覆盖的能力。
MessageGraph假设你不需要在消息层面做复杂的聚合——因为消息本身就是时间序列,你不需要把"第3轮对话"和"第5轮对话"合并成一个对象。
这个差异在面试里的意义是:面试官问你"Reducer在两种图里有什么区别",标准答案是"StateGraph的Reducer是完全可定制的,你为每个字段设计聚合策略;
MessageGraph的Reducer是固定的消息追加,你不需要操心聚合逻辑——但也意味着你失去了在消息层面做复杂合并的能力。"
3.3 选型决策表:什么场景用哪个
选StateGraph还是MessageGraph,核心判断标准只有一个:你的业务数据更接近"共享对象"还是"消息序列"。但光有这个判断还不够,具体可以参考以下决策维度:
优先选StateGraph的场景:业务状态是结构化的、有明确字段边界的;多个节点需要并发读写同一个实体的不同属性;你需要精确控制字段级别的聚合策略;
你的应用场景是工作流自动化、任务编排、实体管理这类偏向"操作"的任务。
优先选MessageGraph的场景:核心数据是对话历史或事件流;每个节点只需要追加新消息而不需要修改历史;你希望保留完整的执行轨迹用于审计或复现;
你的应用场景是多轮对话Agent、聊天机器人、日志记录这类偏向"记录"的任务。
两者混用的场景:LangGraph支持在StateGraph的StateSpec里添加一个messages字段,然后用MessageGraph的add_messages_graph作为该字段的Reducer。
换句话说,你可以在StateGraph里嵌入一个MessageGraph式的消息管理能力。
这在复杂Agent里很常见——主State管理业务实体状态,同时保留一个messages字段记录完整的对话历史。
面试里最容易被追问的一个边界问题是:"如果我既需要结构化状态管理,又需要保留消息历史,怎么办?
"标准回答是:"在StateSpec里声明两个字段:state字段用自定义Reducer做结构化聚合,messages字段用add_messages_graph追加消息历史。
Node执行时,逻辑层处理state,输出层在返回之前把关键输出追加到messages。这样两个维度互不干扰,各自按自己的聚合规则运行。"
四、工程落地:从设计到调试的全链路实战
前面三章已经把概念、模型对比和选型决策讲清楚了——但面试官真正想看的,不是你能不能背出State和Channel的定义,而是你有没有在真实项目里踩过坑、解决过问题。
本章把工程实战拆成三个维度:典型翻车场景、Human-in-the-loop状态管理、Checkpoint持久化。
这三个维度分别对应状态管理的三个高危区间,也是面试里最容易被追问的工程深水区。
4.1 典型翻车场景:状态覆盖与隐式依赖
在LangGraph的工程现场,最常见的翻车不是"某个API不会调",而是"状态在不该丢的时候丢了,但不知道丢在哪"。
这种问题往往发生在Reducer配置不当的情况下,调试成本极高,因为问题的根因不是代码逻辑错误,而是设计阶段对聚合策略的误判。
场景一:并发分支节点写入同一个key,后执行的结果覆盖了先执行的
假设你设计了一个Research Agent,它有一个主流程和两个并行的子任务——一个负责搜索公开信息,一个负责读取内部知识库。两个子任务都需要更新findings字段。
默认Reducer是last-write-wins,如果你不做任何配置,后执行完的节点会覆盖先执行完的节点的结果。
更糟糕的是,在不同的执行环境或并发调度下,这个顺序是不确定的——本地测试全过,线上可能随机丢一半的数据。
这个问题在面试里的变形是:候选人知道要用Reducer,但回答时只说"我用了自定义Reducer",却不解释Reducer策略的选择逻辑。
面试官会接着问:"如果两个节点的写入有依赖关系,比如后一个节点的结果依赖前一个节点的输出,你的Reducer怎么设计?"
标准应答应该落到:条件边(Conditional Edge)来控制执行顺序,而不是靠Reducer的隐式覆盖来处理依赖。
如果确实需要在并发场景下聚合两个节点的输出,应该用append型Reducer把两个结果追加成列表,而不是让后写入的覆盖先写入的。
场景二:State里的隐式依赖没有被显式声明
隐式依赖是状态管理里最容易被忽视的设计缺陷。
典型表现是:Node A修改了config.model字段,Node B读取了config字段但没有在StateSpec里声明对它的写入,这时候如果图执行顺序变了,Node B可能会读到旧配置。
这种bug在单人开发、测试数据固定的情况下几乎不会暴露——因为执行顺序是固定的,隐式依赖刚好碰巧满足了。但一旦引入重试机制、并行边或动态路由,隐式依赖就变成了随机触发的不稳定bug。
工程上解决这个问题的标准做法是:在设计阶段就给每个节点的状态依赖建立清单,明确"谁写什么、谁读什么",然后用LangGraph的类型注解(TypedDict)把这些声明固化到StateSpec里。
如果一个节点读了某个字段但没写,就应该在Node函数的类型签名里显式标注,确保静态检查能抓到这类问题。

这个bug本地跑从来没出现过,一上线就随机丢数据
4.2 Human-in-the-loop中的状态管理
Human-in-the-loop(人被嵌入到Agent执行链路中)场景是状态管理里最复杂的场景之一。
它本质上是一个异步的、带人工介入的工作流,状态需要在"Agent自动执行"和"人工介入点"之间保持一致性。
典型的Human-in-the-loop场景是这样的:Agent生成了一个方案,需要人类审批后才能执行。在这个节点上,Agent的执行会暂停,等待人工输入。
暂停期间,State必须完整地保留下来——包括上下文、中间结果和审批历史。一旦人工输入完成,State需要正确地恢复到执行链路中,Agent继续后续步骤。
LangGraph处理这个场景的核心机制是interrupt和状态持久化的配合。
当Agent执行到需要人工介入的节点时,interrupt()调用会暂停图的执行,但State不会丢失——它被完整地保存在当前checkpoint里。
人工审批完成后,外部调用方拿到当前State,手动注入审批结果(通常是通过更新一个特定的State字段,比如approval_result),然后调用Command(resume=True)让图继续执行。
这个机制在面试里最容易被追问的点是:候选人能不能解释"为什么需要在resume时手动注入结果,而不是让Agent自己从历史消息里读"。
标准答案是:Agent在被interrupt的瞬间已经停止了执行,它不会主动去读外部的审批系统——必须由外部调用方在resume之前把审批结果写回State。
这是状态管理里的一个隐式契约:Human-in-the-loop的"人"是外部于图的,它需要通过State这个唯一的共享接口来与图交换信息。
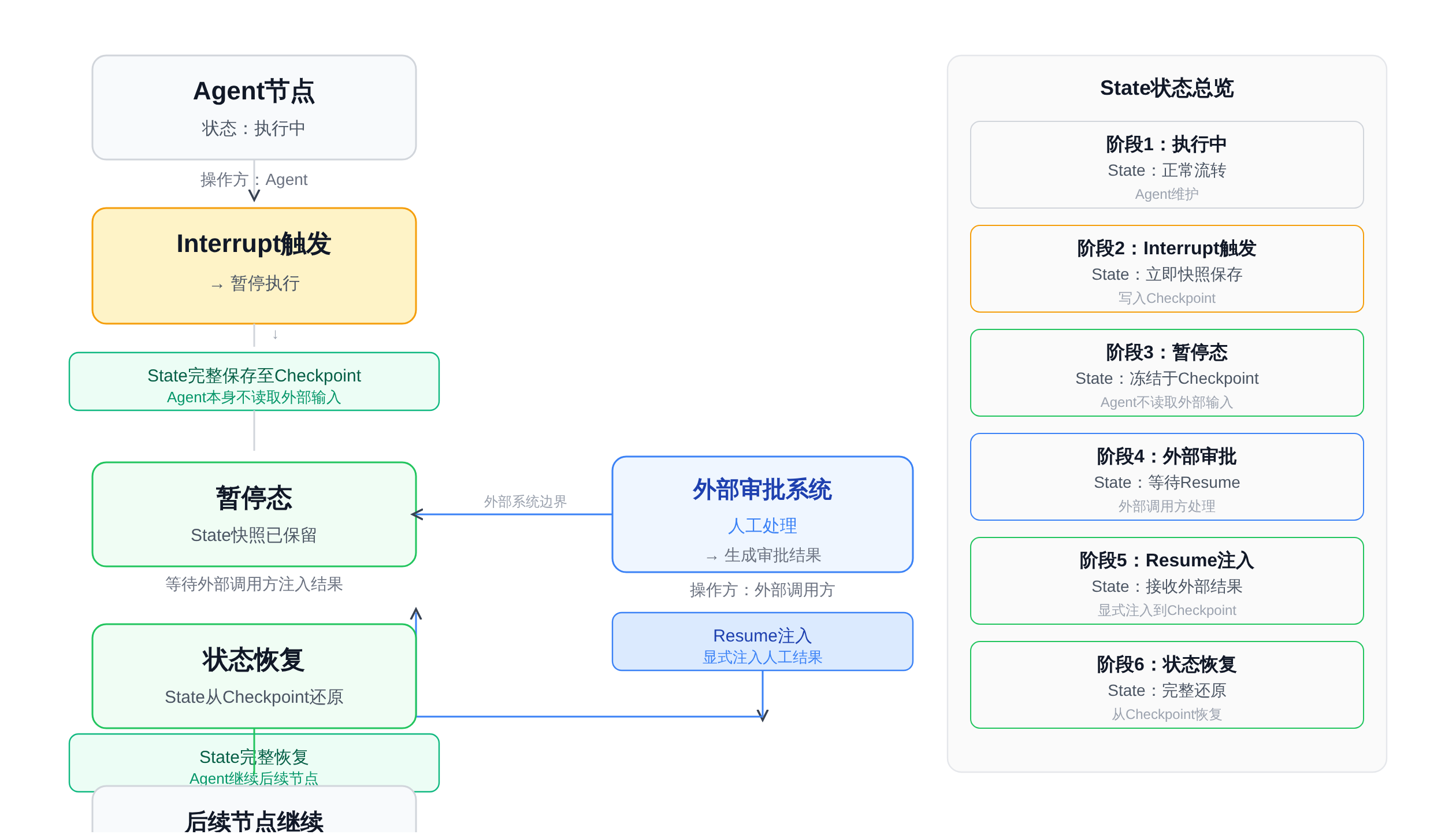
正文图解 3
4.3 持久化与状态恢复:Checkpoint机制
Checkpoints是LangGraph持久化机制的核心。当一个节点执行完成后,LangGraph会在当前State的基础上创建一个checkpoint快照。
这个快照保存了完整的State字典、执行历史(用于trace和replay)以及图的元数据。
Checkpoint的主要用途有三个。
第一个是恢复(Recovery):当Agent执行到一半遇到错误或网络中断时,可以通过加载最近的checkpoint恢复执行,而不需要从头重跑整个流程。
这在长时间运行的复杂工作流里非常重要,因为一个涉及十几步的Agent任务,如果每次中断都要从头来,开发体验会非常糟糕。
第二个是回放(Replay):在调试阶段,工程师可以重放某个checkpoint,观察Agent在某个特定状态下的决策过程。
这对于定位"为什么Agent在某个节点输出了这个结果"这类问题非常有用——你可以把State回滚到那个节点之前,然后单步执行,观察每一步的变化。
第三个是分支(Forking):Checkpoint也支持从某个历史状态创建分支,尝试不同的执行路径。
这在A/B测试、策略探索和回测场景里很有价值——比如你有一个交易Agent,它在某个checkpoint的基础上分别跑两套策略,然后比较结果。
在面试里,Checkpoint最常被问到的问题有两种。
第一种是"Checkpoint和State的区别是什么"——标准答案是:State是当前执行链路中的运行数据,Checkpoint是State在某个时间点的快照;
State会随着图执行不断变化,Checkpoint一旦创建就不会被修改,除非手动创建新的checkpoint。
第二种是"你遇到过checkpoint恢复后状态不一致的问题吗"——这类问题考验的是候选人有没有实际处理过持久化边界条件的经验,标准应答要落到:检查点与外部数据源(如数据库、缓存)的一致性需要额外处理,不能假设checkpoint里包含了所有状态。
五、面试高频追问:15道追问的应答路径
这一章把State/Channel/Reducer相关的面试追问分成三个层次,每个层次5道题,共15道。每道题给出"核心考什么"和"标准应答方向"。
这些追问是AI Agent工程面试的真实高频题,不是我编的——它们来自LangGraph官方文档里的设计决策讨论、LangChain Academy的课程问答,以及公开的面试复盘记录整理。
5.1 概念层追问
追问1:State和Channel的本质区别是什么?
核心考什么:候选人能不能不靠背定义,而是用一句工程判断来区分两者。
标准应答方向:State是一个结构化的共享字典,所有节点在同一个内存空间里读写,聚合策略由Reducer控制;
Channel是一个有序的读写队列,强调的是"先后顺序"和"单向流动"。如果你的业务数据更接近"共享对象",用State;如果更接近"事件流",用Channel。
在LangGraph的实现里,Channel通常对应的是MessageGraph的输入输出,而State对应StateGraph的核心机制。
追问2:为什么Reducer函数必须接受两个参数?
核心考什么:有没有真正理解Reducer的类型签名,而不是只会调用API。
标准应答方向:Reducer函数的签名是(existing, updates) -> merged,两个参数分别是当前State中该字段的已有值(existing)和节点返回的更新值(updates)。
这个设计来源于函数式编程的fold思想——把一个列表的值归约成一个值。
对于状态管理来说,existing是"之前聚合的结果",updates是"本轮的新写入",Reducer把它们合并后的结果作为该字段的新值。
这个设计保证了每个节点的输出都能被正确地累积到State里,而不是被覆盖。
追问3:last-write-wins在什么情况下会出问题?
核心考什么:有没有理解并发场景下默认Reducer的局限性。
标准应答方向:last-write-wins在单线程顺序执行的场景下完全没问题,但一旦引入并行边(两个分支节点同时执行)、重试机制(同一个节点可能被调用多次)或动态路由(执行顺序不确定),"最后一个写入"的定义就变得模糊了——取决于图的调度顺序,而这个顺序在并发场景下是不可预测的。
典型翻车是:两个分支节点同时更新findings字段,结果只有一个被保留了,因为后执行完的覆盖了先执行完的。
解决方案是给该字段配置自定义Reducer(如append型),或者通过条件边控制并发写入的字段分配。
追问4:StateGraph的StateSpec能自定义哪些部分?
核心考什么:有没有真正用过StateSpec,而不是只会import。
标准应答方向:StateSpec可以自定义的部分有三个维度。第一是字段定义——你可以声明任意多个字段,每个字段有明确的类型注解(TypedDict)。
第二是Reducer策略——每个字段可以单独配置Reducer函数,默认是last-write-wins,但你可以换成append、merge或自定义函数。
第三是默认值——可以给每个字段设置初始值,这个初始值在图启动时被写入State。
实际工程中,最容易被忽略的是第二点——很多候选人知道StateSpec可以声明字段,但不知道每个字段的Reducer策略是可以独立配置的。

你说的这个API我好像见过,但从来没配过Reducer
追问5:add_messages_graph和自定义Reducer有什么区别?
核心考什么:有没有理解MessageGraph的Reducer是预置的、不可修改的。
标准应答方向:add_messages_graph是MessageGraph的默认Reducer,它本质上是一个固定的消息追加函数——对于同ID的消息做更新,对于新消息做追加。
它是不可定制的,不提供冲突解决、条件覆盖或复杂合并的能力。
相比之下,自定义Reducer是完全可设计的——你可以实现任意逻辑,包括基于时间戳的合并、基于版本的冲突解决,或者业务特定的去重规则。
在选型上,如果你需要结构化的状态管理,用自定义Reducer;如果你只需要消息追加,用add_messages_graph;
如果两者都需要,在StateGraph的StateSpec里同时声明两个字段。
5.2 对比层追问
追问6:什么场景下应该选StateGraph而不是MessageGraph?
核心考什么:有没有系统的选型判断框架,而不是凭感觉回答。
标准应答方向:选StateGraph的判断标准是:你的业务数据是结构化的共享对象;多个节点需要并发读写同一个实体的不同属性;你需要精确控制字段级别的聚合策略。
典型场景是工作流自动化、任务编排、实体管理。如果你的数据是对话历史或事件流,每个节点只需要追加新消息,用MessageGraph。
混用的场景是:主State管理业务实体状态,同时保留一个messages字段用add_messages_graph追加对话历史——这种设计在复杂Agent里很常见。
追问7:Reducer和Channel的关系是什么?
核心考什么:有没有理解Reducer是State聚合的机制,而Channel是State传递的通道——两者不在同一个抽象层次。
标准应答方向:Channel是State传递的物理通道,它负责把节点返回的值传递到State里;Reducer是State聚合的逻辑层,它决定多个值写入同一个key时如何合并。
类比的话:Channel是快递员,Reducer是签收规则——快递员把包裹送到门口,签收规则决定这些包裹怎么处理(合并还是覆盖)。
在LangGraph的实现里,Channel的读写是由StateGraph的执行引擎自动管理的,你通常不需要直接操作Channel;你需要设计的是Reducer策略。
追问8:如果Node A和Node B并发执行,它们对State的写入会互相干扰吗?
核心考什么:有没有理解并发写入的边界条件和LangGraph的执行模型。
标准应答方向:取决于它们是否写入同一个key。如果写入不同的key,不会互相干扰;
如果写入同一个key,默认Reducer(last-write-wins)会让后执行完的覆盖先执行完的,但这个"后执行完"的顺序在并发场景下是不确定的。
要解决这个问题,可以给该字段配置自定义的聚合Reducer(如append),或者通过条件边把并发写入的节点路由到不同的State字段。
LangGraph不提供乐观锁或原子性保证,如果需要这种保证,需要在业务层实现。
追问9:StateGraph和MessageGraph在Checkpoint处理上有区别吗?
核心考什么:有没有理解持久化机制在不同状态模型上的行为差异。
标准应答方向:在checkpoint粒度上,两者有差异。StateGraph的checkpoint会保存完整的State字典,包含了所有字段的当前值;
MessageGraph的checkpoint会保存messages列表,列表中的每条消息都有时间戳和ID。
在恢复行为上,两者都支持从checkpoint恢复执行,但恢复后的"继续执行"语义不同:StateGraph恢复后节点可以继续读写State的任何字段,而MessageGraph恢复后节点是在消息序列的末尾继续追加新消息。
如果你既用了StateGraph又嵌入了一个messages字段,恢复时需要确保两个维度的状态都被正确处理。
追问10:Reducer和Python的reduce/fold有什么关系?
核心考什么:有没有把函数式编程的基础概念和LangGraph的Reducer设计联系起来。
标准应答方向:Reducer的设计直接来自函数式编程里的fold/reduce概念——把一个列表的值通过某个归约函数合成一个值。
在LangGraph里,Reducer归约的不是列表,而是一个序列的历史值:[初始值, 第1次更新, 第2次更新, ..., 第N次更新]通过Reducer函数依次处理,得到第N次更新后的状态。
函数签名(existing, new) -> merged对应了fold的经典形式。
理解这一点有助于理解为什么Reducer必须是纯函数——它不应该有副作用,也不应该依赖外部状态,因为它可能在并发场景下被多次调用,而且每次调用之间不能有隐式依赖。
5.3 工程层追问
追问11:如何在State更新时做版本控制或冲突检测?
核心考什么:有没有在真实工程场景下考虑过状态冲突的问题。
标准应答方向:基础方案是在State里维护一个version字段,每次更新时自增。
Reducer检查传入的updates里的version和existing里的version,如果相同则接受,如果不同则触发冲突处理——可以是抛出异常、merge冲突值或回退到某个默认值。
高级方案可以用向量时钟或逻辑时钟来实现分布式版本的冲突检测,但这在LangGraph的单进程执行模型下通常不需要。
面试里想听到的不是"我用了xx框架",而是"我在Reducer里做了版本检查,发现版本冲突时走了以下处理流程"。
追问12:在Human-in-the-loop场景下,State如何和外部系统保持一致性?
核心考什么:有没有理解State和外部系统的边界,以及状态恢复的完整链路。
标准应答方向:State和外部系统的一致性需要从两个角度处理。第一个角度是写入一致性:人工审批结果在resume前必须显式写回State,不能假设Agent会自己从外部系统读取。
第二个角度是读取一致性:checkpoint保存的是State在某个时间点的快照,但外部数据源(如数据库)的内容可能在checkpoint创建后发生了变化,恢复时需要判断是否需要刷新外部数据。
标准工程做法是:在checkpoint里保存外部数据源的版本号或时间戳,恢复时对比,如果不一致则重新拉取或触发冲突处理流程。

这个边界情况设计文档里没写啊
追问13:如何调试State聚合过程中的异常行为?
核心考什么:有没有实际排查过Reducer相关的bug,工具链是什么。
标准应答方向:标准排查链路是:打开LangSmith的trace功能,观察每个节点的输入State和输出State——如果输出State里的某个字段不符合预期,第一步检查节点本身是否正确返回了该字段,第二步检查Reducer函数是否有bug,第三步检查StateSpec里该字段的Reducer配置是否与预期一致。
在本地调试阶段,可以用checkpoint replay功能,把State回滚到某个节点执行之前,然后手动注入测试数据,单步执行观察Reducer的行为。
最容易被忽视的排查点是:Reducer函数本身的逻辑是否正确——比如一个深度合并Reducer,如果没处理None值,就可能在某些边界条件下抛出异常。
追问14:如果一个节点的输出会触发State的大面积变更,你如何设计StateSpec来避免隐式依赖?
核心考什么:有没有系统性的StateSpec设计方法论,而不是凭经验碰。
标准应答方向:首先做依赖分析:列出所有节点对State字段的读和写,建立一个读写矩阵——哪行是哪个节点,哪列是哪个字段,读写交叉的位置标上读/写/读写。
目标是确保没有"只读不写但依赖其他节点的写结果"这种隐式依赖链。如果存在隐式依赖,解决方案有三个:第一,把被依赖的字段显式声明在依赖节点的输出里(即使值没变,也要写回State);
第二,把强依赖的节点用条件边串行化,不让它们并发执行;第三,把隐式依赖转化为显式依赖,在State里添加版本号或时间戳字段,让下游节点可以判断数据是否过期。
追问15:在生产环境里,你如何监控State的健康度?
核心考什么:有没有把状态管理纳入生产可观测性体系,而不是只在开发阶段关注。
标准应答方向:生产环境的State健康监控通常从三个维度入手。
第一个维度是完整性:每个checkpoint里State的必填字段是否有值,字段类型是否正确,可以用schema validation在checkpoint创建时自动检查。
第二个维度是一致性:对于有业务约束的字段组合(如status=done时result必须有值),可以设置断言检查,checkpoint创建后如果断言失败则告警。
第三个维度是延迟:State的更新是否有延迟监控——如果某个节点执行完成超过一定时间(比如5秒)State还没更新,说明可能有阻塞或死锁。
LangSmith的trace功能可以帮助你在生产环境里观察每个节点的State变化,如果发现异常可以通过trace的checkpoint历史做根因分析。
六、常见误区与避坑清单
这一章把State/Channel/Reducer使用中的高频误区整理成清单,每个误区都给出"错误做法"和"正确做法"的直接对比。这些误区来自真实的工程翻车记录和面试中的高频错误回答。
6.1 把Channel当成消息队列
这是最常见的误解之一——候选人在学Channel机制时,会自然地把它类比成Kafka或RabbitMQ这类消息队列,认为Channel也是一个异步的、持久化的、可重试的消息传输通道。
错误做法:把Channel当成消息队列来设计,在Node里从Channel读消息、处理、往另一个Channel写消息,期待它有持久化和重试能力。
正确做法:在LangGraph的语境里,Channel是State传递的内存通道,不是持久化消息队列。
它只在图的执行过程中存在,图执行结束后Channel里的数据要么被checkpoint保存,要么丢失。如果你需要持久化消息,必须依赖Checkpoint机制;
如果你需要异步处理,必须依赖外部的任务队列(如Celery、RQ)。Channel的作用域是图的执行上下文,不是分布式系统的消息总线。
6.2 混淆Reducer和Reducer函数签名
另一个高频误区是:知道"Reducer控制聚合策略",但在实际使用时不理解Reducer函数的签名要求,导致运行时错误。
错误做法:定义了一个Reducer函数,但签名只有1个参数(比如只接收new值),或者Reducer函数有副作用(如修改了外部变量),或者Reducer返回了None。
正确做法:Reducer函数的签名必须是(existing, new) -> merged,两个参数,返回一个新值。
existing是State中该字段的当前值(可能是None),new是节点返回的更新值(可能是单个值或列表),返回值是该字段在State中的新值。
Reducer必须是无副作用的纯函数,因为LangGraph可能在并发场景下调用Reducer,而且Reducer的执行顺序在并行场景下是不确定的——有副作用的Reducer会产生不可预测的行为。
如果需要做复杂的状态转换,在Node函数里处理,不要在Reducer里做业务逻辑。

这个Reducer函数我看了三遍才找到bug
6.3 认为last-write-wins是唯一选择
很多候选人知道Reducer,但默认"last-write-wins已经够用了",在所有场景下都使用默认Reducer,不去做任何自定义配置。
错误做法:在需要追加消息历史的字段(如history、messages)上也使用默认Reducer,导致新消息覆盖旧消息,历史数据丢失。
在需要深度合并的配置字段上使用默认Reducer,导致后一个节点的配置完全覆盖前一个节点的配置。
正确做法:在设计StateSpec时,先做字段分类——哪些字段是"最终值"类型(如status、result),用默认的last-write-wins;
哪些字段是"历史累积"类型(如history、logs、messages),用append型Reducer;
哪些字段是"配置合并"类型(如metadata、config),用deep merge型Reducer。这个分类过程应该在设计阶段完成,而不是在发现数据丢失后补救。
如果你在面试里能说出"我会在设计阶段做字段分类,不同类型的字段有不同的Reducer策略",面试官会认为你有过系统性思考,而不是只会查文档。
七、项目语境:如何在简历和面试中正确表达
这一章专门解决一个实际问题:如何在简历和面试里正确表达你用过LangGraph的状态管理机制。
很多候选人的问题是:知道怎么用,但说出来像背八股,或者说出来的时候暴露了自己其实只停留在"会用API"的层面。
简历层面的表达
简历上写"用LangGraph实现了一个Agent"是不够的——它没有体现出你理解状态管理机制。
更好的表达方式是:"使用StateGraph管理Agent的多阶段状态,设计了自定义Reducer实现历史记录追加和配置深度合并"。
这句话里包含了三个关键信息:第一,你用的是StateGraph而不是MessageGraph,说明你知道两者的区别;第二,你设计了自定义Reducer,说明你不只依赖默认行为;
第三,你列举了两种具体场景(历史记录追加和配置深度合并),说明你有实际工程经验而不是纸上谈兵。
如果你的项目涉及Human-in-the-loop,可以加一句:"设计Human-in-the-loop状态持久化方案,通过interrupt和checkpoint恢复机制实现人工审批节点的异步介入"。
这句话让面试官知道你知道状态管理在异步场景下的具体实现,而不是泛泛地说"支持人工介入"。
面试层面的表达
面试里最难的不是回答概念题,而是把项目经历讲得有技术深度。
很多候选人会在项目描述里说"我负责Agent的状态管理",但如果面试官追问"你遇到的最难的状态管理问题是什么",答案往往是泛泛的"要考虑并发情况",没有具体到问题是什么、你是怎么设计的、结果怎么样。
好的项目表达应该包含三个部分:问题描述、设计决策、结果验证。
比如:"在实现一个多节点并行Research Agent时,遇到了两个分支节点同时更新findings字段导致数据丢失的问题。
原因是默认Reducer的last-write-wins在并发场景下不可预测。
我把findings字段的Reducer改成了append型,同时通过条件边确保并发分支写入同一个列表,最终保留了所有节点的输出。
在测试环境用100次随机并发执行验证,数据丢失率为0%。"
这段表达里有问题(数据丢失)、有根因(last-write-wins在并发场景下不可预测)、有设计(append型Reducer + 条件边)、有验证(100次随机并发测试),面试官可以从中看到系统性思考能力和工程落地能力。
容易被追问的边界问题
面试里关于State/Channel/Reducer,最容易被追问的边界问题有三个,提前准备会让面试更从容。
第一个是"如果你的Reducer逻辑有bug,导致State被破坏了,你怎么发现和恢复"——标准答案是:checkpoint + LangSmith trace + 字段级schema validation。
从checkpoint恢复时先做schema检查,如果不符合预期则告警并回退到上一个checkpoint。
第二个是"你怎么决定哪个字段用什么Reducer策略"——标准答案是:在StateSpec设计阶段做字段分类,区分最终值类型、历史累积类型和配置合并类型;
不同类型对应不同的聚合语义和Reducer策略;如果不确定,先用最保守的策略(比如append),再根据业务需求升级。
第三个是"State和Channel的性能有什么区别"——标准答案是:在LangGraph的实现里,Channel是State传递的物理机制,Reducer是State聚合的逻辑层,两者在性能上的主要区别来自于Reducer的计算复杂度——默认的last-write-wins是O(1),append是O(n),深度合并是O(n*m),如果State里有很多嵌套字段,深度合并的Reducer会成为性能瓶颈。
优化方案是给不同的字段配置不同复杂度的Reducer,避免在不需要深度合并的字段上使用深度合并Reducer。
延伸入口
- 原文归档:https://tobemagic.github.io/ai-magician-blog/posts/2026/04/25/ai面试八股文-vol11-专题10节点间通信state传递vs-channel传递/
- 公众号:计算机魔术师

参考文献
[1] 原始资料[EB/OL]. https://github.com/alexeygrigorev/ai-engineering-field-guide/blob/main/interview/questions/04-ai-system-design.md. (2026-04-25).