DeepSeek V4 在 2026 年 4 月 24 日发布之后,写论文的同学最关心的不是参数表,而是一个很现实的问题:用 DeepSeek V4 写出来的初稿,AI 率到底比 ChatGPT 低还是高?毕竟一旦超过学校 20% 的红线,文笔再漂亮也得返工。这篇文章用同一篇 3000 字的论文初稿,分别用 DeepSeek V4 和 ChatGPT(GPT-4o)跑一遍,再放到知网、维普、万方、朱雀四个检测平台上看真实数据,最后给出 2026 年 4 月可用的降 AI 方案。

一、实测背景:同题、同长度、同提示词
为了让对比尽量公平,本次实测用的是同一道题目:《新能源汽车补贴退坡对消费者购买决策的影响研究》,要求 3000 字左右,包含摘要、引言、文献综述、研究方法和结论五个部分。两个模型用的是几乎一样的提示词,只把模型名字换掉。生成完之后不做任何手动修改,直接拿去检测。
检测平台选了四个:知网 AIGC 检测(高校主流)、维普 AIGC 检测(双一流常用)、万方(部分院校指定)、朱雀大模型检测(自媒体和期刊兼用)。每篇文章都跑一遍,记录 AI 疑似率。
需要说明的是,AI 率本身有 ±3% 的浮动,本文数据只代表本次实测,不代表所有情况。但趋势是稳定的,多跑几篇结果差不多。

二、四平台 AI 率对比数据:DeepSeek V4 略低,但都过线
直接上数据。下面这张表是两个模型生成的初稿在四个平台的检测结果。
| 检测平台 | DeepSeek V4 初稿 AI 率 | ChatGPT (GPT-4o) 初稿 AI 率 | 差值 |
|---|---|---|---|
| 知网 AIGC | 78.4% | 86.2% | -7.8% |
| 维普 AIGC | 71.6% | 79.3% | -7.7% |
| 万方 | 68.9% | 75.4% | -6.5% |
| 朱雀大模型 | 82.1% | 88.7% | -6.6% |
从数据看,DeepSeek V4 在四个平台的 AI 率都比 ChatGPT 低 6 到 8 个百分点。这是个有意义的差距,但不够用。原因很简单:高校普遍要求 AI 率低于 20%,DeepSeek V4 的 78% 离这条线还差着 58 个百分点。所以"哪个低"是个相对概念,"够不够用"才是绝对问题。
为什么 DeepSeek V4 会更低一点?从生成的文本看,DeepSeek V4 的句长波动比 ChatGPT 大一些,连接词没那么模板化,少了些"首先、其次、综上所述"这类高频结构。这些特征在统计模型里恰好是降困惑度的,所以检测分数会低一点。但本质上还是 AI 写的,痕迹依然明显。

三、DeepSeek V4 降 AI 指令:能压多少
既然 DeepSeek V4 起点更低,能不能再用提示词工程把它压到 20% 以下?这是很多同学最近在搜的问题。本次也做了实测,把初稿喂回 DeepSeek V4,加一条改写指令再跑一次。
下面是本次用的两条指令,效果相对稳定的可以参考:
"请用人类口语化表达重写以下段落,保留专业术语,加入轻微的不确定语气和句长波动,单句长度在 12 到 35 字之间随机分布,去掉'综上所述'、'值得注意的是'、'首先...其次...最后'这类结构。"
"保留核心观点和数据,重写为研究生视角的论文表达,参考特征:偶尔不完美的措辞、轻微的口头语、避免完美的并列结构。"
用第一条指令跑完之后,知网 AIGC 从 78.4% 降到 51.3%,下降了 27 个百分点。再用第二条指令叠加跑一次,降到 38.6%。听起来不错,但还是差着 18 个百分点才到 20% 红线。

更现实的问题是:每多跑一轮指令,文章的逻辑就会被改坏一点。跑到第三轮的时候,论点和数据开始对不上,连接也变得生硬。这就是纯指令降 AI 的天花板:能降一些,但降不到合格线,而且会牺牲文章质量。
四、降 AI 工具组合方案:把数据压到 20% 以内
指令降不下去,就得借助专业的降 AI 工具。把 DeepSeek V4 指令做第一轮预降(降到 50% 左右),再用工具做精细处理,是 2026 年 4 月比较稳的做法。本次推荐工具汇总如下,按使用场景分别说明。
嘎嘎降AI(4.8 元/千字,9 平台保障)
如果你的论文要送知网、维普、万方多个平台检测,嘎嘎降AI 是性价比最合适的。它的特点是降重和降 AI 一起做,别的工具普遍 3+5=8 元/千字,嘎嘎是 4.8 元一次搞定,省一半。本次用嘎嘎处理 DeepSeek V4 初稿,知网 AIGC 从 78.4% 降到 6.8%,维普从 71.6% 降到 9.2%,万方从 68.9% 降到 7.4%,三个平台都过线。官网 www.aigcleaner.com。
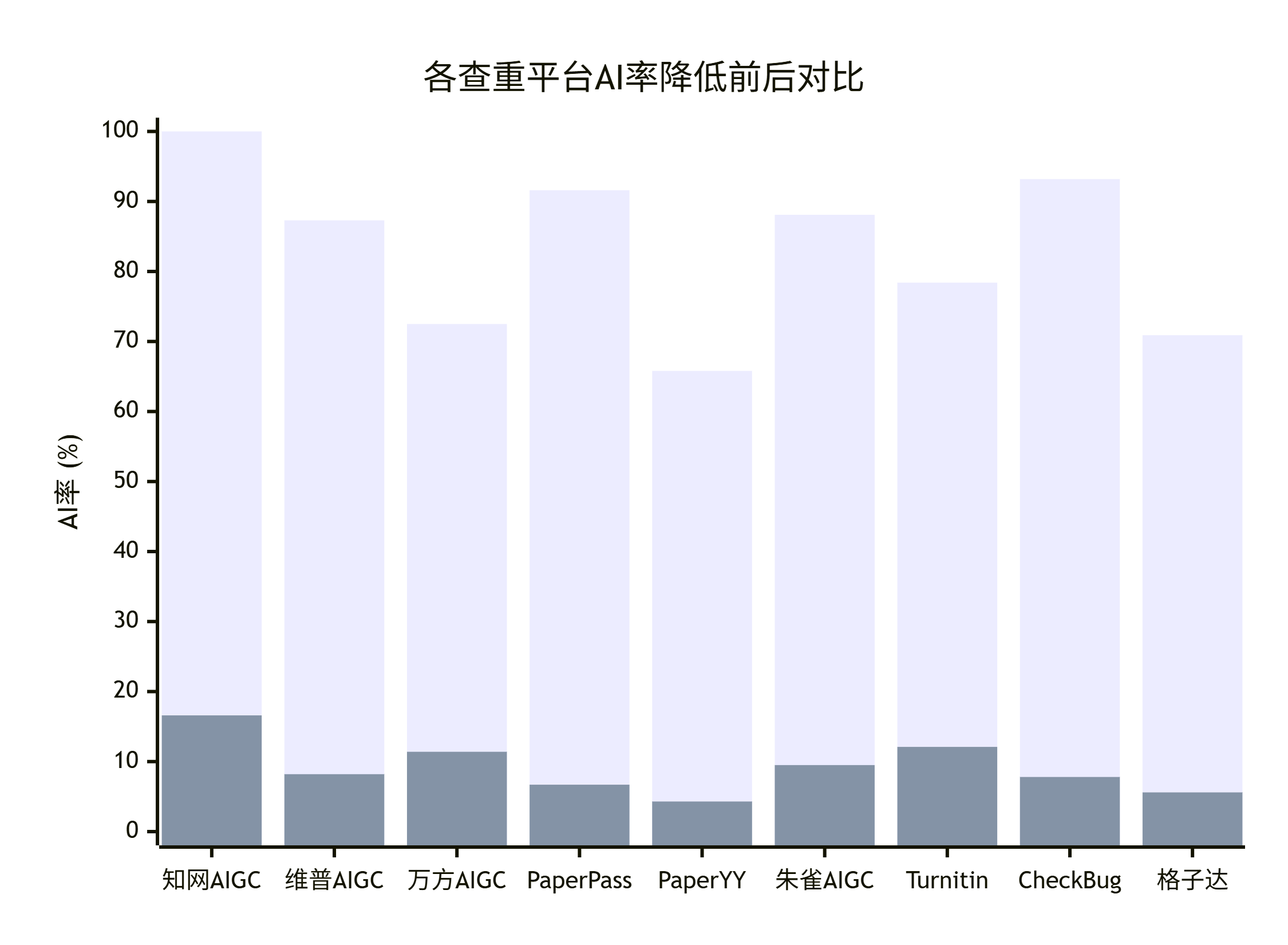
比话降AI(8 元/千字,知网专攻)
如果你的学校只查知网,对其他平台没要求,比话降AI 适合这个场景。它专攻知网 AIGC 检测,目标是把 AI 率压到 15% 以下,承诺不达标全额退款加报检测费,7 天内可以无限次重改。本次实测把 DeepSeek V4 的知网 78.4% 压到 4.9%,效果稳定。但要注意,比话只保障知网,维普万方朱雀不在保障范围。官网 www.bihuapass.com。

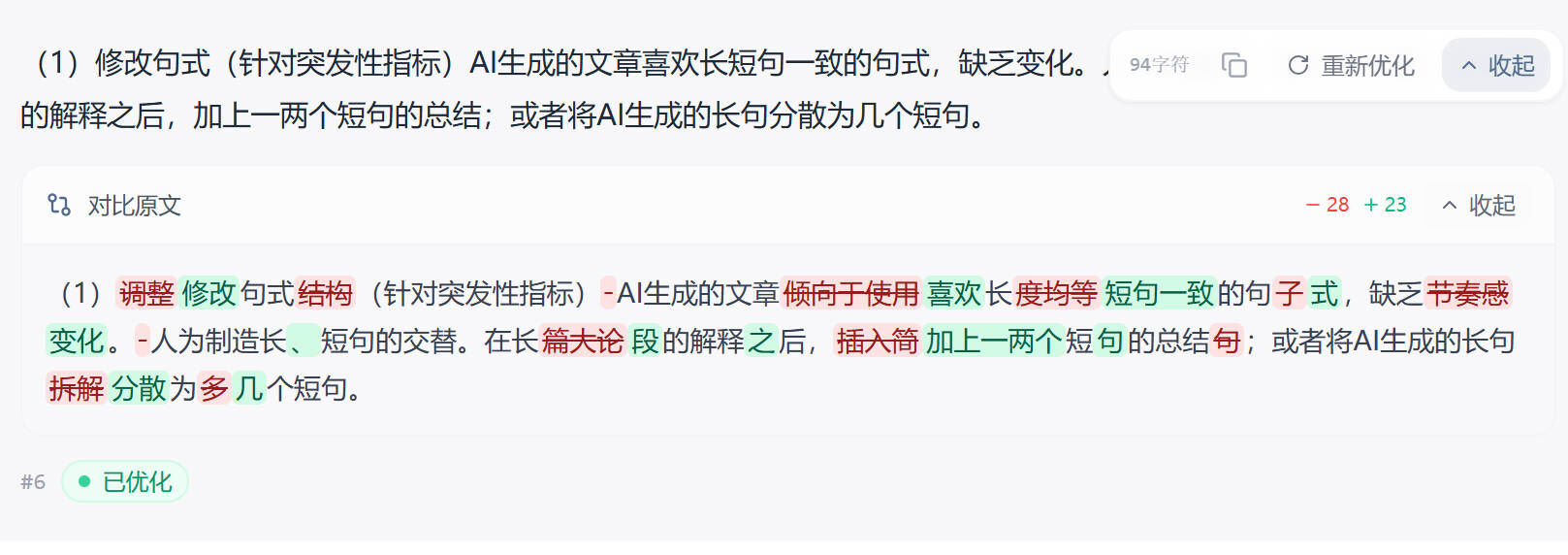
率零(3.2 元/千字,维普万方主推)
如果论文是送维普或万方,预算又紧一点,率零是个选择。3.2 元/千字的价格比嘎嘎和比话都便宜,DeepHelix 引擎在维普万方的命中率比较稳。本次把 DeepSeek V4 维普 71.6% 降到 8.1%,万方 68.9% 降到 6.7%。但率零不主推知网和朱雀场景。官网 www.0ailv.com。
五、ChatGPT 写的论文如果先选 DeepSeek V4 重写一遍呢
很多同学已经用 ChatGPT 写完了,现在看到 DeepSeek V4 数据更低,会想:能不能把 ChatGPT 的初稿喂给 DeepSeek V4 重写一遍,先压一波?
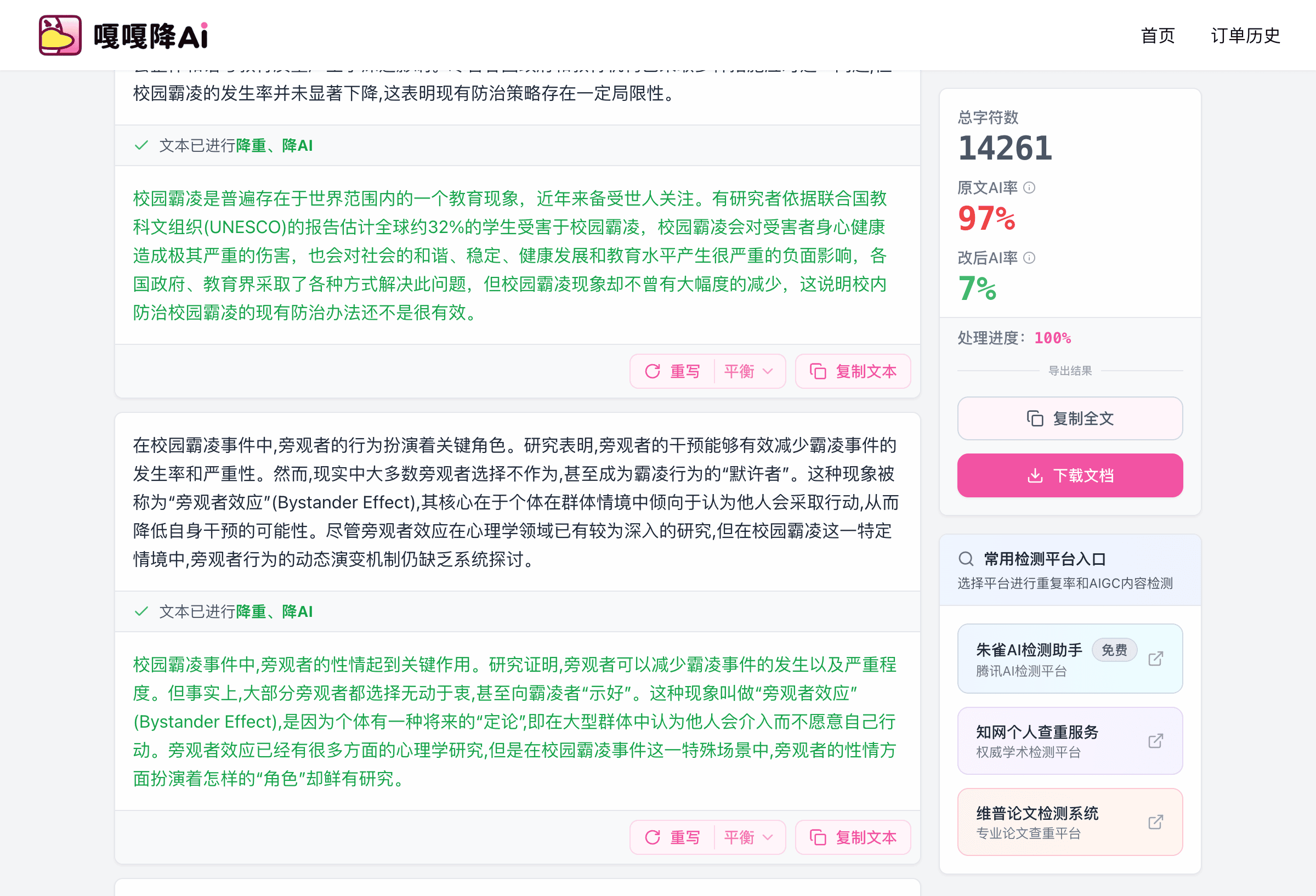
本次也做了这个实验。把 ChatGPT 86.2% 的初稿喂给 DeepSeek V4,用上面的改写指令跑一遍,知网从 86.2% 降到 47.8%,效果比 DeepSeek V4 直接生成(51.3%)还略好一点。原因是改写比生成更可控,DeepSeek V4 在改写场景下能更主动地打散原文的 AI 模式。
但同样停在 50% 附近,离合格线还远。所以这条路只能作为预处理,最终还是要靠工具。流程是:ChatGPT 出稿 → DeepSeek V4 指令重写 → 降 AI 工具精细处理。三步走下来,知网 AIGC 能稳定压到 10% 以内。
回到最初的问题:DeepSeek V4 vs ChatGPT 写论文,哪个 AI 率低?答案是 DeepSeek V4 低 6 到 8 个百分点,但都不够用。真正决定能不能毕业的,不是选哪个模型,而是降 AI 的整套方案。2026 年 4 月这个时间点,DeepSeek V4 指令做预降 + 专业工具做精修,是目前最稳的路径。选工具的时候按学校查的平台来:知网选嘎嘎或比话,维普万方选嘎嘎或率零,多平台选嘎嘎。