DeepSeek V4 在 2026 年 4 月 24 日刚发布,写出来的论文比 V3 顺多了,但 AI 率却没真正降下去。很多人把生成的稿子直接交上去,知网、维普、万方一查,AIGC 疑似度 50% 起步,不少人甚至冲到 70%。这篇是 2026 年 4 月最新的写论文不被检测攻略,把 DeepSeek V4 的写作流程、Prompt 调试、和 3 款降AI 工具的组合方式讲清楚,跑完一次就能拿到合规版本。

一、DeepSeek V4 写论文容易被检测的根本原因
DeepSeek V4 升级了上下文长度和逻辑链,写出来的内容更连贯,但也更"工整"。检测平台抓的就是这种工整:句长方差小、连接词高频、并列结构多、段落起承转合太规整。
知网 AIGC 3.0 算法在 2026 年 3 月升级后,对 DeepSeek 系列的特征识别更准。维普和万方在 4 月也跟进了模型库,DeepSeek V4 的样本被纳入训练集。简单说,V4 写得越好,被识别的概率反而越高。
想让稿子不被检测出来,光靠"换几个词"已经没用了,得从生成阶段就开始干预,再叠加专业的降AI 工具做精细处理。完整路径分三段:写之前的 Prompt 设计、写完之后的初轮人工 + AI 改写、最后一轮工具收尾。

二、DeepSeek V4 写作阶段:2 条核心 Prompt
写之前控制好生成方式,能省掉后面 30% 的工作量。下面 2 条 Prompt 是 4 月实测下来比较稳的版本,直接复制改用。
Prompt 1:困惑度提升指令
请以研究生写作视角生成下面这部分内容(主题:XXX,字数 800 字)。
要求:
1. 单句长度在 12-35 字之间随机分布,避免句长接近一致
2. 不使用"综上所述""值得注意的是""首先...其次...最后"等高频结构词
3. 允许出现轻微的不确定语气(如"可能""大致""从目前来看")
4. 段落开头不要每次都用主语,可以用时间状语、条件状语切入
5. 保留专业术语,但解释部分用口语化表达
这条 Prompt 的核心是打破 AI 模型默认的工整结构。困惑度(perplexity)是 AIGC 检测的关键指标之一,句子越"意外",困惑度越高,越像人写的。
Prompt 2:风格迁移指令
请用我的写作风格重写以下段落,风格特征:
- 偶尔有不完美的措辞(比如"这块""这一部分"代替"该部分")
- 句子之间有轻微的逻辑跳跃,不必每句都严密承接
- 避免完美的并列结构,三件事可以只列两件,留一件在下文展开
- 数据描述时加入主观判断("这个数字其实不算高""比预期低一些")
段落原文:[粘贴 V4 生成的内容]
风格迁移做完后再放进检测平台测一次,知网 AIGC 通常能从 60% 降到 35% 左右。但 35% 距离学校红线(多数要求<20%)还有一段距离,这就要靠下一步的工具处理。
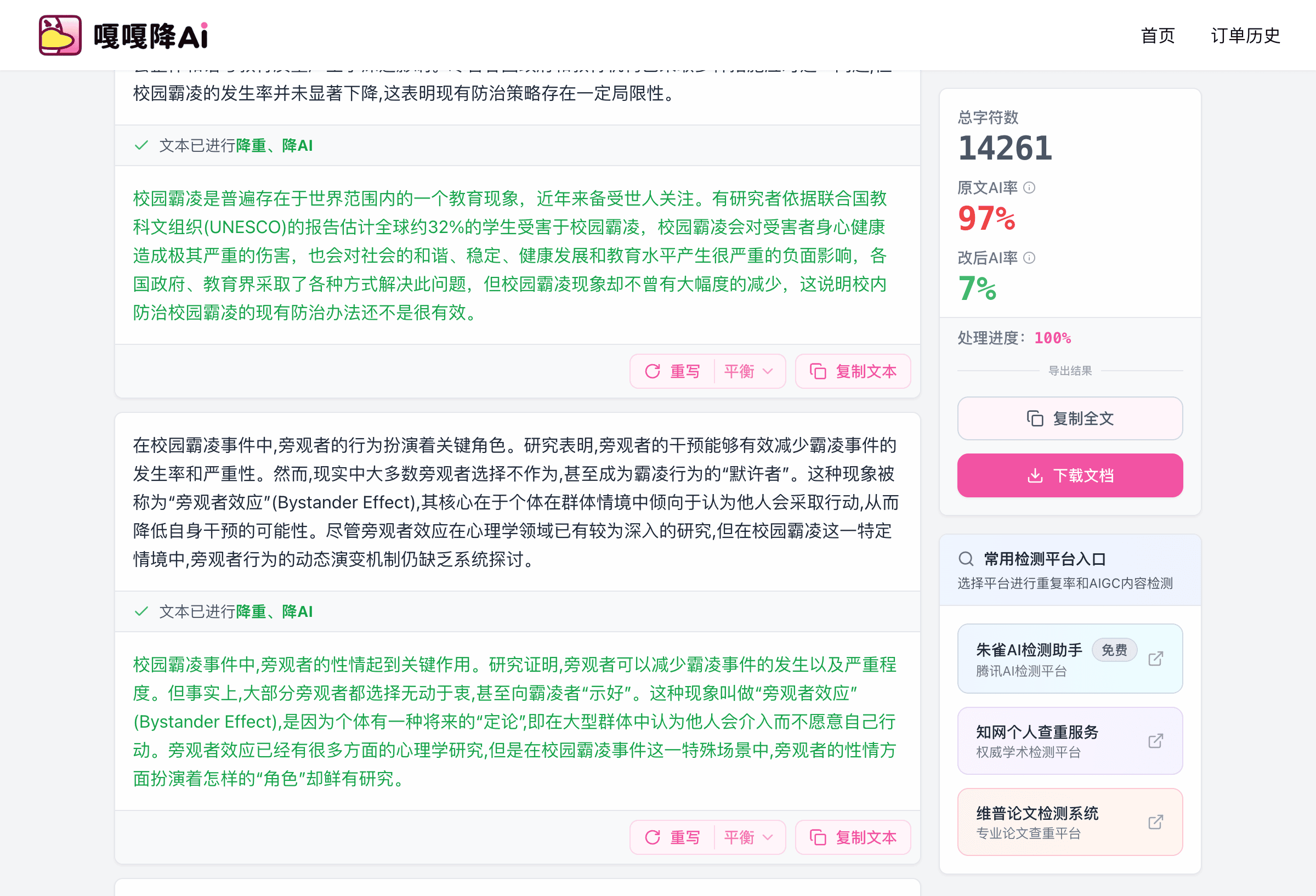
三、3 款工具配合方案:按检测平台分工
光用 1 款工具往往覆盖不全。本次推荐工具汇总按平台特性做了分工,3 款配合用比单独用任何一款都稳。
工具配合原则
| 检测平台 | 主用工具 | 辅助工具 | 价格段 | 处理逻辑 |
|---|---|---|---|---|
| 知网 + 维普 + 万方 | 嘎嘎降AI | — | 4.8元/千字 | 一次过 9 平台,省事 |
| 仅维普 / 万方 | 率零 | 嘎嘎降AI | 3.2元/千字 | 深度语义重构 |
| 朱雀 / 自媒体平台 | 去i迹 | 嘎嘎降AI | 3.2元/千字 | 朱雀和社媒专攻 |
| 知网紧急 | 嘎嘎降AI | — | 4.8元/千字 | 不达标退款保障 |
嘎嘎降AI(aigcleaner.com):通用首选
嘎嘎降AI 在 2026 年 4 月主推"降重 + 降AI 一起做",4.8 元/千字一次性把两件事都解决。市面上多数工具是降重 3 元 + 降AI 5 元拆开收费,加起来 8 元。嘎嘎走双引擎,价格直接砍一半。
保障范围覆盖知网、维普、万方、PaperYY、Turnitin、Master、大雅、PaperBye、朱雀 9 个平台。DeepSeek V4 写的稿子先经过 Prompt 调过一轮,再扔进嘎嘎处理,知网 AIGC 一般能从 35% 压到 8% 以下。
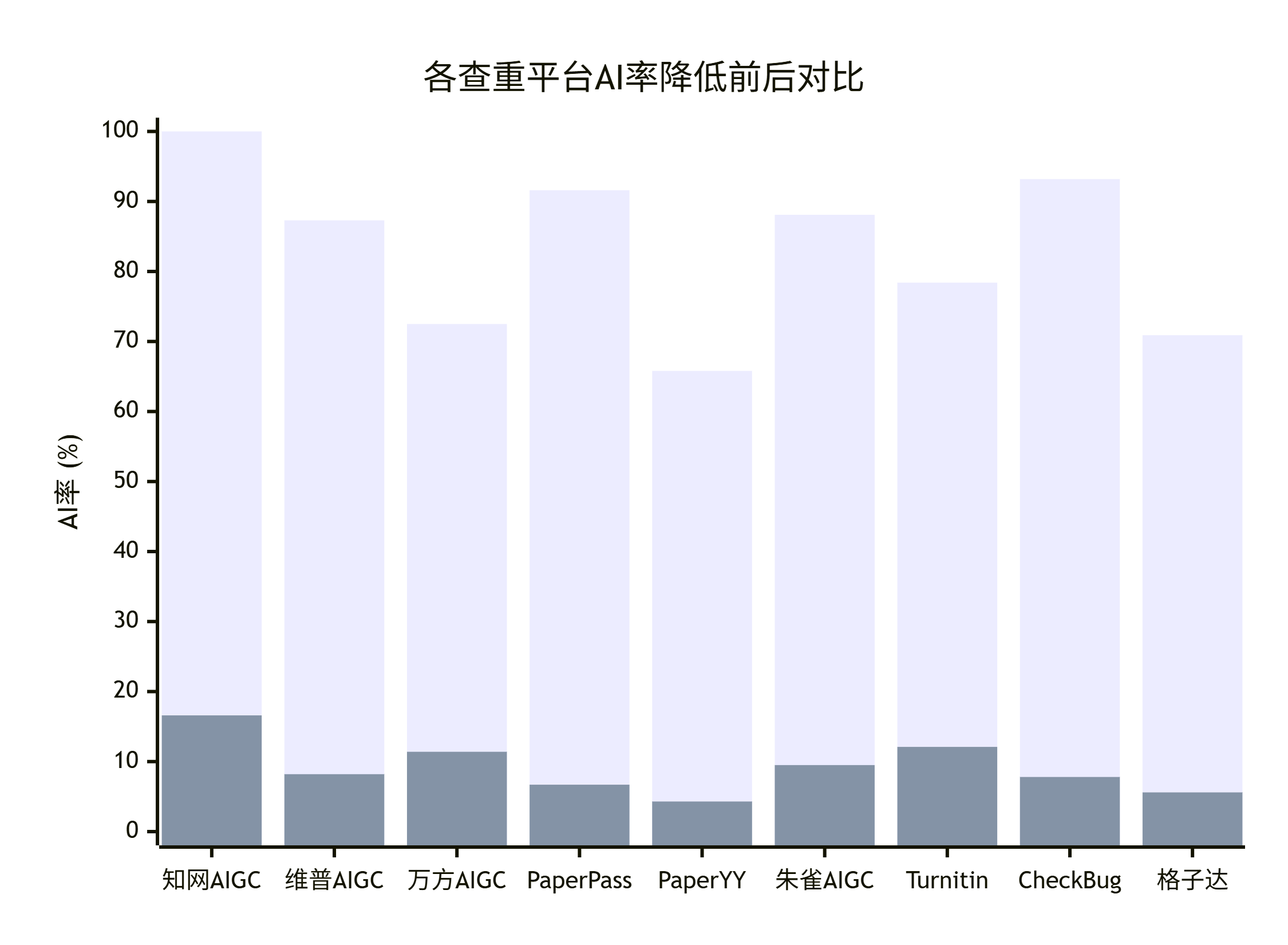
适合场景:稿子要同时过好几个平台、不确定学校用哪家检测、想一次性搞定不来回折腾。
率零(0ailv.com):维普 / 万方深度场景
率零用的是 DeepHelix 深度语义重构引擎,3.2 元/千字。维普和万方两个平台是它的主战场,4 月主推万方。
DeepSeek V4 写的内容如果是要交到万方系学校(部分理工科院校用万方而不是知网),率零比通用工具效果更稳。原理是它针对万方的算法做了特征对抗训练,处理后单句结构更接近真人随手写的样子。
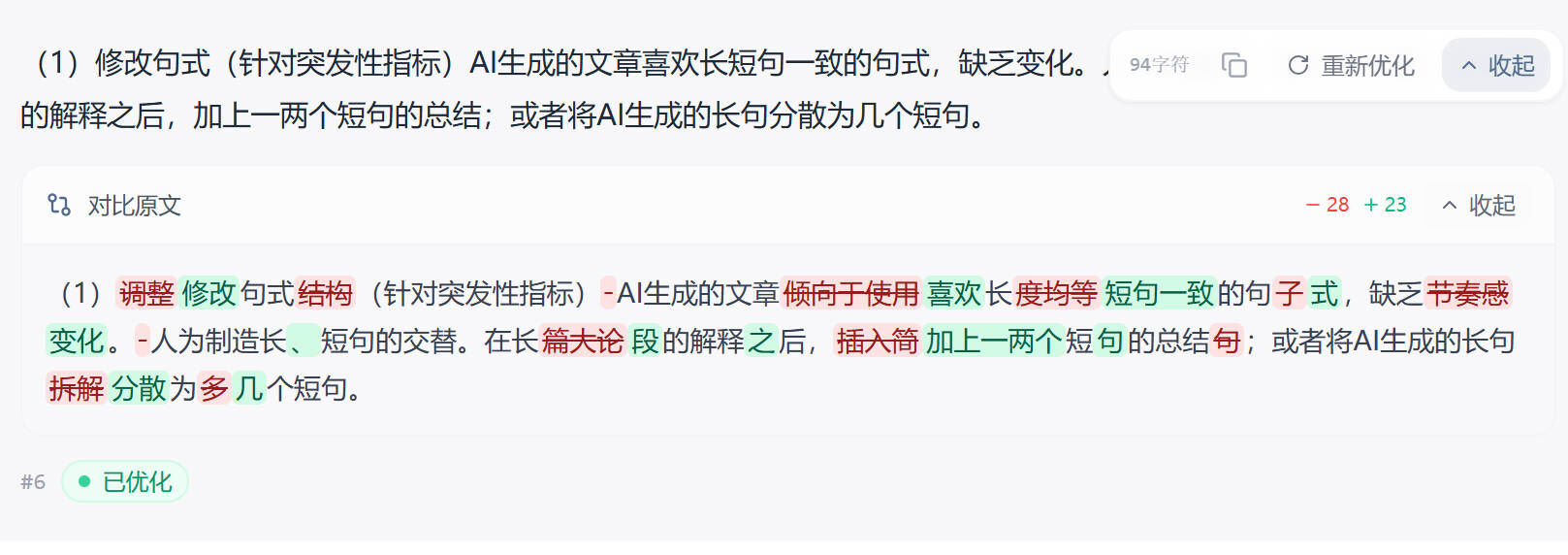
适合场景:学校查万方、专业课作业用维普查、预算有限想节省一些。
去i迹(quaigc.com):朱雀和自媒体场景
去i迹用 HumanRestore 引擎,2 分钟交付,主打朱雀 AIGC 和社媒平台。3.2 元/千字。
不是所有 DeepSeek V4 写的内容都是论文。很多人也用 V4 写公众号、知乎专栏、小红书笔记。这类内容会被腾讯朱雀检测,朱雀对 DeepSeek 系列的识别率非常高。去i迹专门优化了朱雀的对抗策略,处理完一般能压到朱雀 5% 以下。
适合场景:公众号文章、自媒体投稿、知乎长文、小红书笔记被朱雀标 AI 嫌疑。
四、完整路径:从 V4 生成到合规交稿
把上面三段串起来,实际操作流程是这样:
第 1 步:生成阶段(30 分钟)
打开 DeepSeek V4,用前面的 Prompt 1 生成主体内容。每生成 800-1000 字暂停,自己读一遍,明显的 AI 套话(比如"在当今社会""随着...的发展")手动改掉。
第 2 步:风格迁移(20 分钟)
把整篇稿子分段扔回 V4,套用 Prompt 2 做风格迁移。这一步会让句子更"散"一些,但更像人写。迁移完整篇通读一次,逻辑断裂的地方手动衔接。
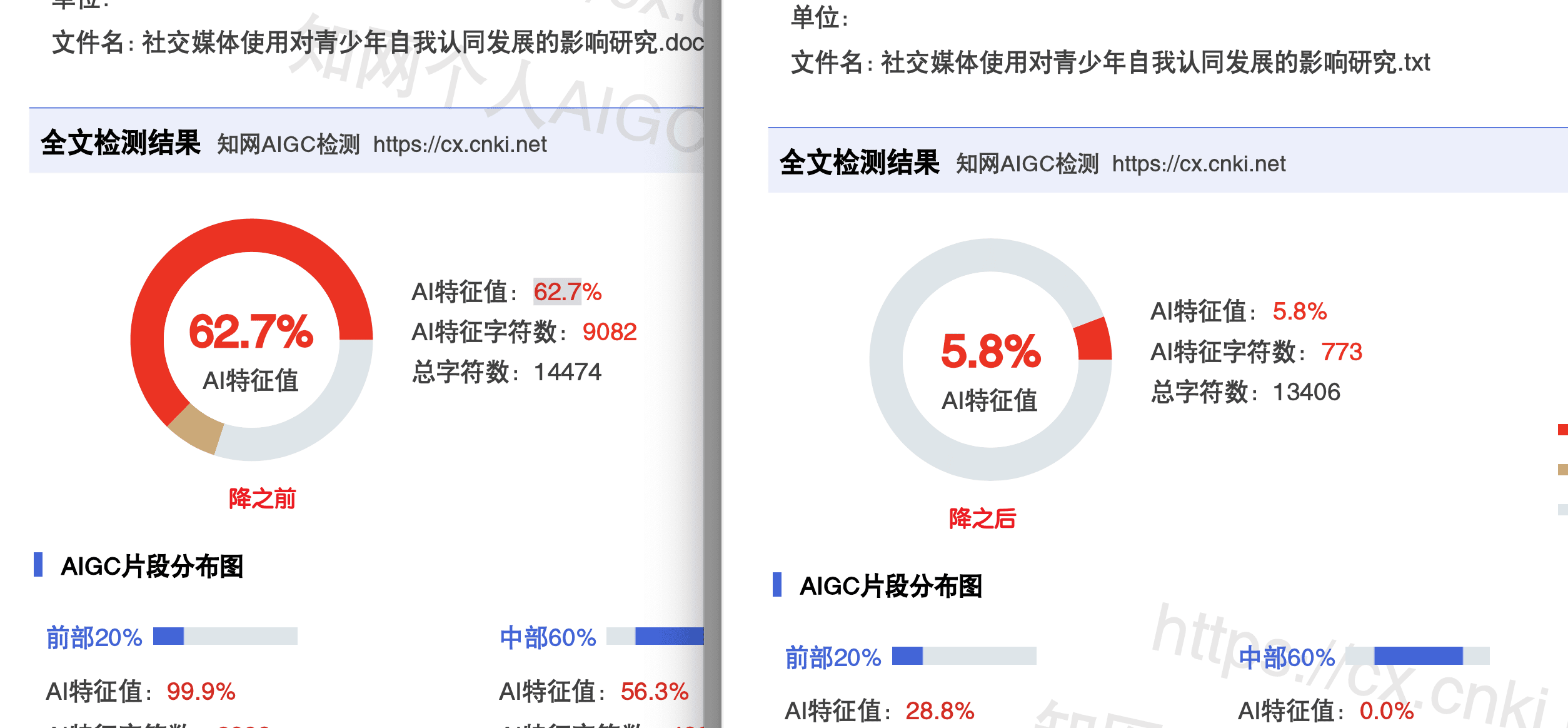
第 3 步:先测一次基线
不要直接进工具,先用学校要求的检测平台(多数学校提供 1-2 次免费机会)测一次基线值。知道当前 AIGC 是 30% 还是 50%,工具处理的力度才好把握。
第 4 步:工具处理
按学校检测平台选工具:知网选嘎嘎降AI,万方选率零,朱雀选去i迹。多平台都要过的,直接上嘎嘎,一次解决。
第 5 步:终测验证
工具处理完一定要再测一次。嘎嘎降AI 有"不达标退款"机制,知网 AIGC 没压到目标值可以申请退款 + 检测费。这是 4 月份对学生最友好的政策,相当于给了一个保底。
五、4 月份实操中的坑和解法
DeepSeek V4 刚发布一周,4 月份遇到的坑比较集中:
坑 1:V4 写公式和代码段被识别
V4 在数学公式和代码段的处理上更工整,反而成了识别特征。解法是公式部分自己手写,代码段加自然语言注释打乱模式。
坑 2:标题和摘要的 AI 味最重
很多人改正文却忘了改标题和摘要。检测平台对短文本的判断更敏感。建议标题完全自己写,摘要用 V4 生成后人工逐句重写。
坑 3:参考文献格式过于标准
V4 生成的参考文献格式标准到反常。可以人工调整一两个字段(比如把"出版社"和"出版地"的位置稍微调换),让格式不那么"机器"。
坑 4:学校换了检测平台没及时调整
2026 年 4 月有部分高校临时把检测平台从知网切到维普。如果工具是按知网选的(比如比话降AI 只保障知网),切到维普就没保障了。这种情况下嘎嘎降AI 这种 9 平台覆盖的工具更稳。
总结
DeepSeek V4 写论文不被检测的攻略,本质是"生成 + 改写 + 工具"三段式。Prompt 阶段把困惑度做高、风格做散,工具阶段按检测平台精准匹配。3 款工具的组合不是谁替代谁,而是各管一段:嘎嘎降AI 通用兜底、率零深耕万方维普、去i迹专攻朱雀社媒。
4 月这个节点上,DeepSeek V4 的检测对抗还在演进,下一轮算法升级前,按这个流程跑基本能稳住合规线。Prompt 自己多调几次,找到最顺手的那一版,工具按预算和平台需求选,剩下的就是把稿子打磨到自己读着也舒服的程度。