PubMed批量文献下载全攻略:后端架构视角下的自动化实现
在生物医学研究中,PubMed是文献检索的核心数据库,但批量下载全文、提取元数据往往耗费大量时间。本文从后端架构视角出发,设计了一套基于NCBI公开API的自动化工具,通过服务端请求调度、数据库元数据管理、中间件请求限流等思路,实现文献信息的智能提取与批量下载。你将获得一个可直接运行的HTML工具,无需任何依赖,轻松搞定文献调研。
理解PubMed文献获取的底层逻辑
PubMed上的文章并非全部开放获取,但通过PMC(PubMed Central)可访问部分全文。对于无法直接查看的文献,我们可以利用NCBI提供的两个公开API:esummary和efetch。这两个接口类似于后端架构中的服务端API,支持批量查询,前者每次最多50个PMID,后者每次最多25个。它们返回标准XML格式数据,相当于后端服务返回的JSON或XML响应,便于我们解析和存储。
核心思路:通过API获取文献元数据(标题、作者、期刊、DOI等),生成Sci-Hub等第三方下载链接,再借助批量下载工具(如IDM、Downie)完成全文下载。这类似于后端架构中通过中间件聚合多个数据源,最终对外提供统一接口。
| API | 用途 | 频率限制 |
| NCBI eutils (efetch) | 获取标题、摘要、作者、机构、DOI、期刊、年份 | 建议 ≤3 次/秒 |
| Europe PMC REST API | 获取被引用次数 (citedByCount) | 无严格限制,建议适当延迟 |
⚙️ PMID智能提取:兼容多种输入格式
PubMed导出的文件格式多样,常见的有:每行一个PMID的纯文本、PubMed格式TXT(PMID行格式为 PMID- 12345678)、逗号分隔的PMID列表。为了兼容所有格式,我们采用正则表达式+字符串分割双管齐下的策略,并用 Set 自动去重,确保后端处理的数据干净无冗余。
⚠️ 注意事项:在实际开发中,类似的需求常出现在后端服务中,比如从用户上传的CSV或Excel中提取ID列表。这里的实现思路可以作为服务端数据清洗的参考。
function extractPMIDs(text) {const pmids = new Set();// 匹配 "PMID- 12345678" 或 "PMID: 12345678" 格式(PubMed 导出文件)const re = /PMID[:\-\s]+(\d{5,9})/gi;let m;while ((m = re.exec(text)) !== null) pmids.add(m[1]);// 匹配按行/逗号/空格分隔的纯数字(5-9位)text.split(/[\n\r,;\s]+/).forEach(t => {t = t.trim();if (/^\d{5,9}$/.test(t)) pmids.add(t);});return [...pmids];
}️ 调用NCBI eutils:仿后端API请求架构
NCBI提供的 esummary 接口支持一次请求多个PMID,返回标准XML格式。解析时,我们使用浏览器原生的 DOMParser,无需引入任何第三方库——这类似于后端架构中直接使用内置解析器处理XML响应,避免额外依赖。
性能优化:NCBI对未注册用户限制每秒最多3次请求。代码中批次间设置了600ms延迟,相当于在后端架构中通过中间件实现请求限流,避免触发频率限制。这保证了工具在批量处理时的稳定性。
const NCBI_BASE = 'https://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi';
async function fetchDetails(pmids) {const result = new Map();const url = NCBI_BASE + '?db=pubmed&id=' + pmids.join(',') + '&rettype=xml&retmode=xml';const resp = await fetch(url);const doc = new DOMParser().parseFromString(await resp.text(), 'text/xml');doc.querySelectorAll('PubmedArticle').forEach(function(art) {const pmid = art.querySelector('PMID').textContent.trim();const d = {};// 标题d.title = art.querySelector('ArticleTitle').textContent.trim();// 摘要(支持结构化摘要,如 Background/Methods/Results/Conclusion)const absEls = art.querySelectorAll('Abstract AbstractText');d.abstract = Array.from(absEls).map(function(t) {const lbl = t.getAttribute('Label');return lbl ? lbl + ': ' + t.textContent.trim() : t.textContent.trim();}).join('\n\n');// 作者列表 + 机构d.authors = Array.from(art.querySelectorAll('AuthorList Author')).map(function(au) {const last = au.querySelector('LastName').textContent;const ini = au.querySelector('Initials').textContent;const affiliations = Array.from(au.querySelectorAll('AffiliationInfo Affiliation')).map(function(a) { return a.textContent.trim(); });return { displayName: last + ' ' + ini, affiliations: affiliations };});// 发表年份(优先取 Year,备用 MedlineDate)const yearEl = art.querySelector('PubDate Year') || art.querySelector('PubDate MedlineDate');d.year = yearEl ? yearEl.textContent.slice(0, 4) : '';// 期刊名称d.journal = (art.querySelector('Journal Title') || art.querySelector('MedlineTA')).textContent.trim();// DOIart.querySelectorAll('ArticleId').forEach(function(id) {if (id.getAttribute('IdType') === 'doi') d.doi = id.textContent.trim();});result.set(pmid, d);});return result;
}if (i + 50 < pmids.length) await delay(600);完整使用流程:从检索到下载
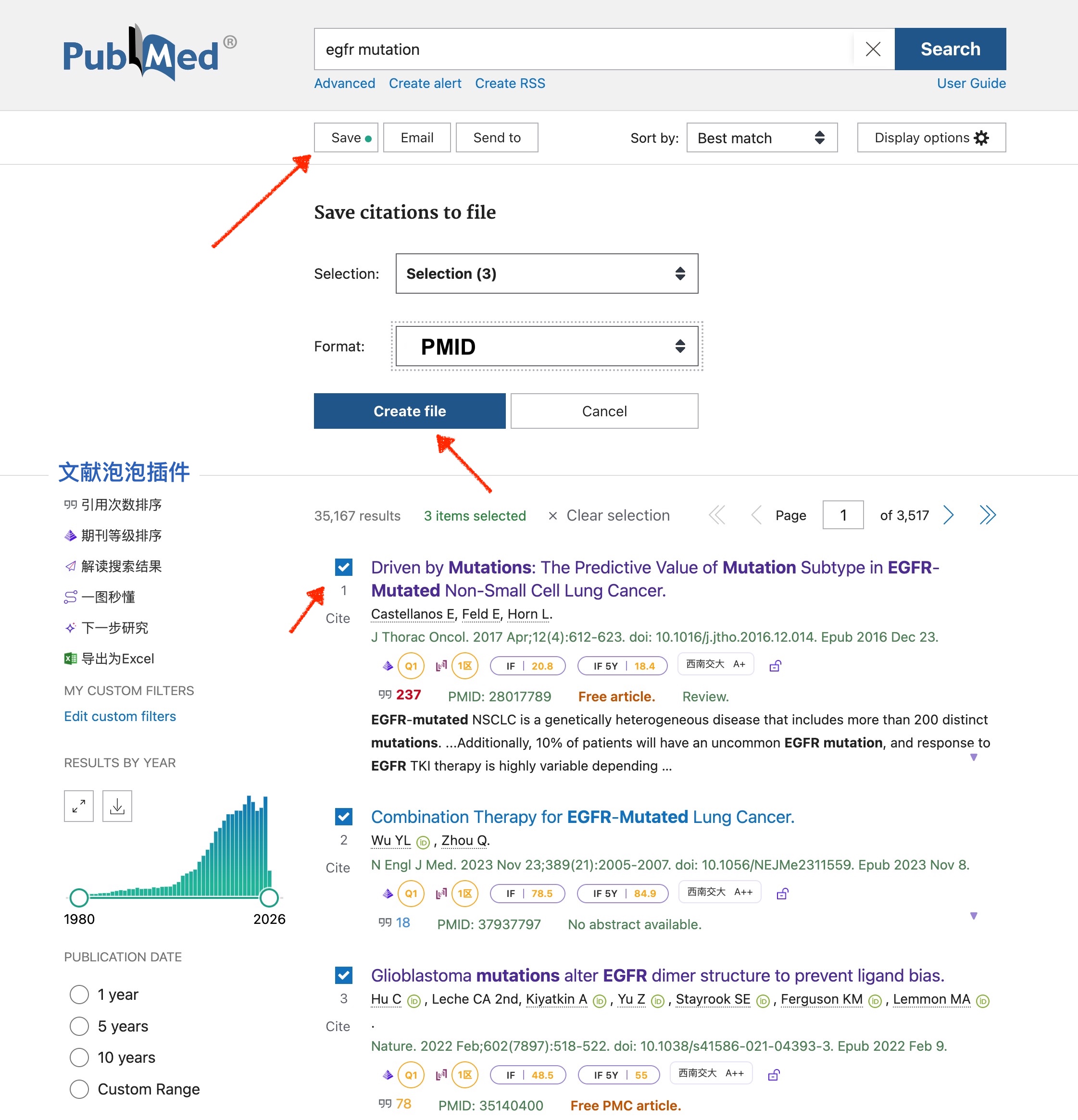
- 获取PMID列表:在PubMed检索后,点击 Send to → 选择 File 或 Clipboard 格式导出。
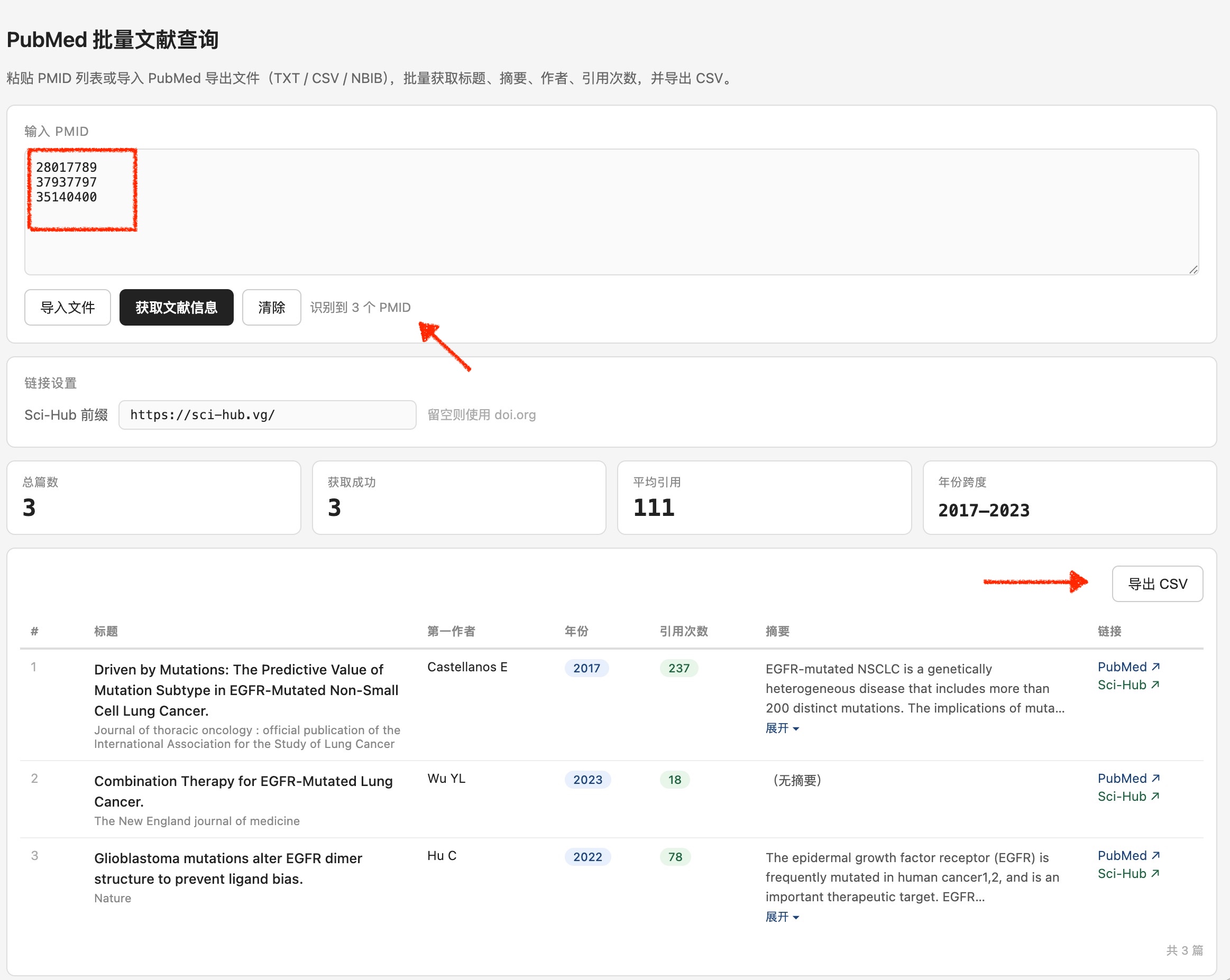
- 粘贴或导入文件:将导出内容粘贴到文本框,或点击「导入文件」直接读取
.txt、.csv、.tsv文件。 - 点击「获取文献信息」:工具自动分批请求,进度条实时显示状态,类似后端架构中的异步任务进度反馈。
- 配置Sci-Hub前缀(可选):默认为
https://sci-hub.se/,可自行修改为其他可用镜像。 - 导出CSV:点击「导出CSV」,文件名自动带上日期,用Excel打开即可筛选和整理。
导出的CSV包含以下字段:序号、PMID、标题、期刊、年份、第一作者、全部作者、引用次数、DOI、摘要全文、机构、PubMed链接、Sci-Hub链接。你可以打开CSV文件,复制下载链接到下载工具,批量下载全文。
进阶应用:后端架构中的数据库与中间件设计
上述工具虽然是一个单文件HTML,但其设计思想可迁移到更复杂的后端架构中。例如,可以将PMID列表存储在数据库中(如SQLite或PostgreSQL),通过服务端API定期拉取文献信息,更新元数据。中间件层负责请求限流、缓存结果,避免重复调用NCBI接口。
实践建议:如果你需要频繁处理大量文献,可以考虑将工具升级为后端服务,使用Redis缓存API响应,用Celery或类似工具管理异步任务。这样,前端只需提交PMID列表,后端自动完成所有请求和CSV生成,大幅提升效率。
[AFFILIATE_SLOT_1]
推荐搭配:文献泡泡(PaperPop)浏览器扩展
上面的工具解决的是已有PMID列表后的批量处理问题。但在此之前,还有一个同样耗时的环节:如何在PubMed/Google Scholar的搜索结果页快速判断哪些文献值得精读?
文献泡泡(PaperPop)是一款浏览器扩展(支持Chrome和Edge),专门解决这个问题。它能在搜索结果页直接显示期刊等级、影响因子、AI综述研究热点等信息,帮助你快速筛选高质量文献。结合本文工具,你可以实现从检索到下载的全流程自动化。
完整代码与扩展
完整工具代码约370行,是一个单文件HTML,无需安装任何依赖,下载后用浏览器直接打开即可使用。文件已上传,欢迎在评论区留言获取。现在AI写代码很厉害,你可以利用这部分代码作为提示,让AI帮你修改出想要的功能——比如增加数据库存储、添加用户认证等后端特性。
[AFFILIATE_SLOT_2]
小结
本文从后端架构视角,实现了PubMed文献的批量查询与下载工具。通过API请求调度、数据清洗、请求限流等思路,将重复的文献调研工作自动化。搭配文献泡泡扩展,你可以覆盖从检索到整理的全流程,把时间留给真正需要思考的部分。立即尝试,体验效率提升的乐趣!