Zookeeper
初识
-
zookeeper是Apache项目下的子项目,是一个树形目录服务。
-
是一个分布式、开源的分布式应用程序的协调服务。
- 配置管理
- 分布式锁
- 集群管理
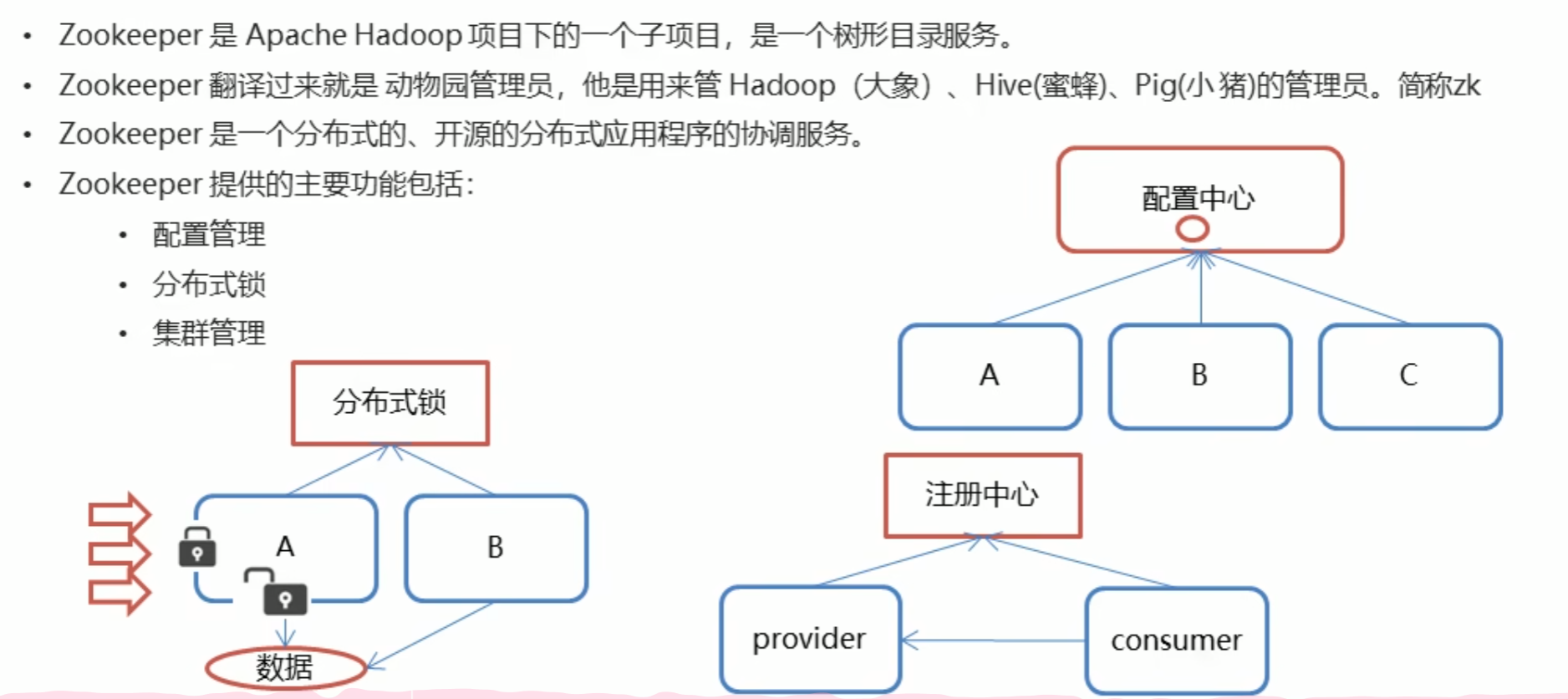
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。也就是说 Zookeeper = 文件系统 + 通知机制。
命令操作
数据模型
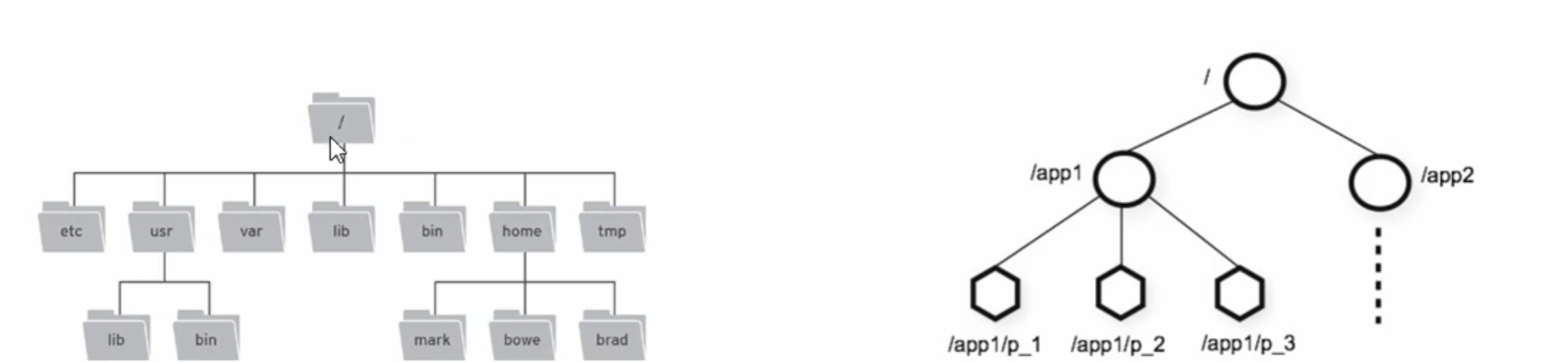
- zookeeper是一个树形目录服务,类unix文件系统目录树。
- 每一个节点被称为ZNode
- 每个节点可以 拥有子节点,同时允许少量数据存储在该节点
- 节点分为四大类
- PERSISTENT 持久化节点
- EPHEMERPOAL 临时节点:-e
- PERSISTENT_SEQUENTIAL 持久化顺序节点:-s
- EPHEMERAL_SEQUENTIAL 临时顺序节点:-es
服务端命令
- 启动 zkServer.sh start
- 关闭 zkServer.sh stop
- 重启 zkServer.sh restart
- 状态 zkServer.sh status
客户端命令
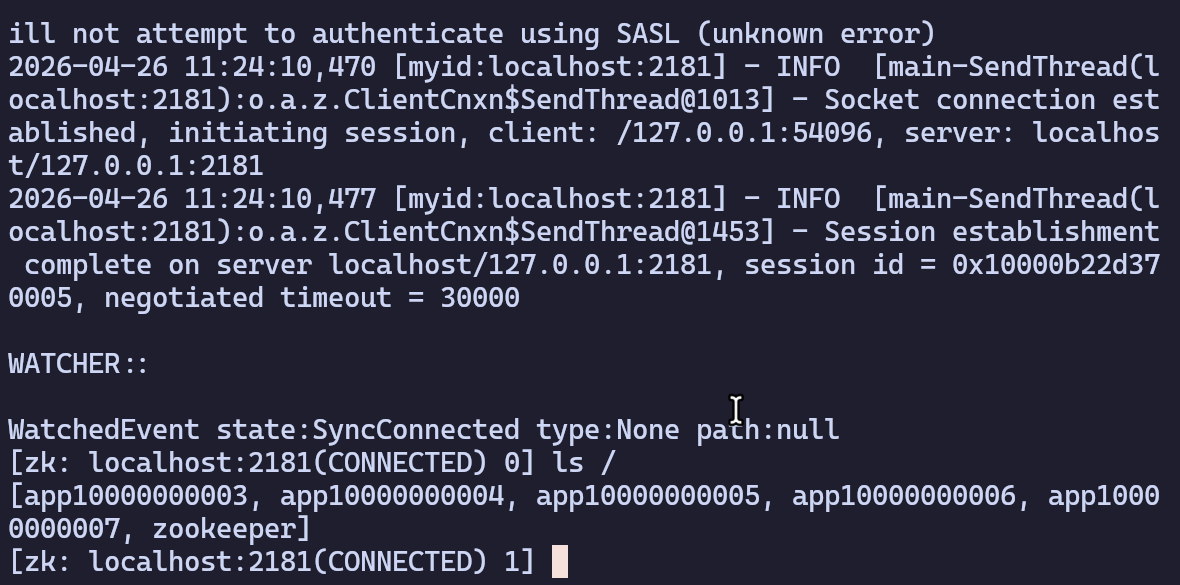
启动连接客户端 : zkCli.sh -server localhost:2181
使用过程中,按下 Tab键,终端会提示可用命令。
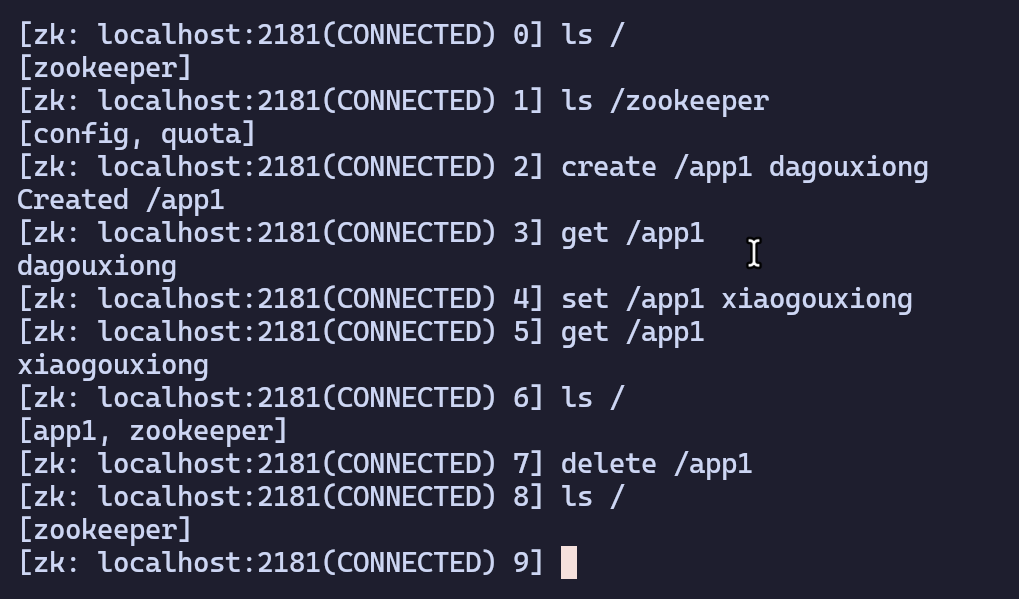
ls /:查看节点create /app1 [数据]:创建节点 [添加数据]get /app1:查看节点内容set /app1 [数据]:设置节点内容delete ./app1:删除节点stat /app1(ls -s):查看节点信息quit:退出
创建临时节点
create -e /app1:临时节点,重启后消失create -s /app1:创建多个持久化顺序节点
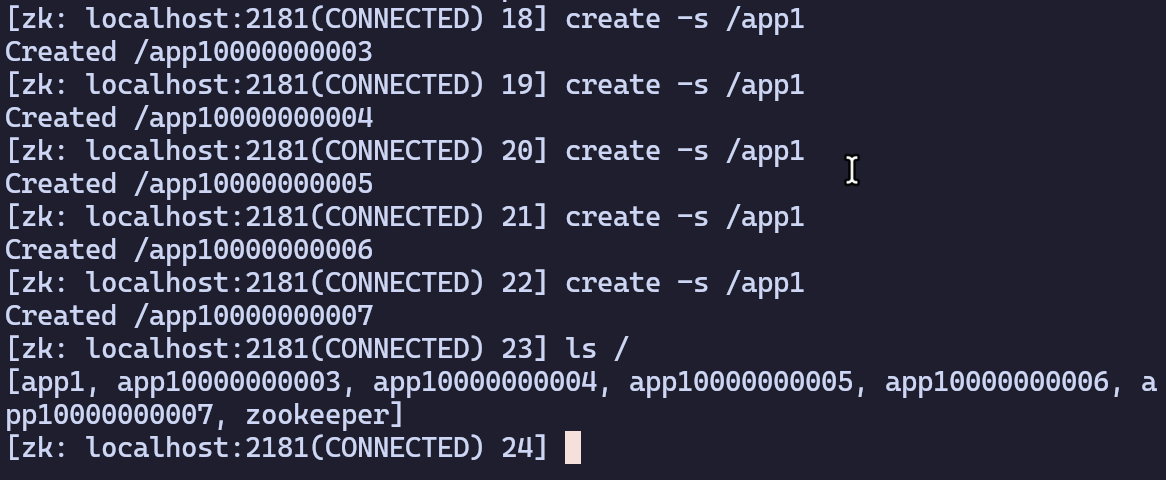
create -es /app2:创建多个临时顺序节点

重新启动后发现,临时节点已消失。
API使用
1. CMake配置
target_include_directories(mprpc PRIVATE /usr/local/include/zookeeper)target_link_libraries(mprpc PRIVATE/usr/local/lib/libzookeeper_mt.asasl2 # sasl2也要单独安装
)
2. 方法
- 首先定义一个全局的
watcher回调函数
void global_watcher(zhandle_t *zh, int type, int state, char const *path, void *watcherCtx) {if (type == ZOO_SESSION_EVENT) /* 会话类型 */{if (state == ZOO_CONNECTED_STATE) /* 已连接 */{/* 这里的信号量是注册全局的watcher的时候设置额定*/sem_t *sem = (sem_t *)zoo_get_context(zh);sem_post(sem);} else if (state == ZOO_EXPIRED_SESSION_STATE) /* 会话过期 */ {log_error("Session expired");// 1. 关闭旧会话zookeeper_close(zh);// 下面的步骤是可能需要做的,这里不予演示// 2. 重新创建链接// 3. 重新创建所有临时节点// 4. 重新注册所有watcher}}
}- 初始化(zookeeper_init)
/*connstr是特定格式的ip:port信息,比如127.0.0.1:9999global_watcher就是我们刚才定义的回调300000默认心跳时间30s
*/
_zhandle = zookeeper_init(connstr.c_str(), global_watcher, 30000, nullptr, nullptr, 0);
if (_zhandle == nullptr) {log_error("Zookeeper_init Error");exit(EXIT_FAILURE);
}/* 这里设置context指向信号量,就是我们在回调中使用的那个信号量。简单而言默认信号量时0,zookeeper_init的时候_zhandle返回值只是说明了函数进行了处理但是时候init成功还是不确定的,需要等待回调。因此我们在主程序设置信号量,然后wait阻塞等待回调完成设置信号量,这时候主程序继续。
*/
sem_t sem;
sem_init(&sem, 0, 0);
zoo_set_context(_zhandle, &sem);
sem_wait(&sem);log_info("zookeeper_init_success!");
- 创建节点(zoo_create)
/*第二个参数是指定的节点路径,第三个参数是节点的值,flags表明节点类型,可以是0(普通持久节点)、ZOO_EPHEMERAL(临时节点)、ZOO_SEQUENCE(顺序节点)第五个参数存放实际的地址,比如你传入/app/worker,实际节点路径可能为/app/worker-00000001
*/
char created_path[256];int ret = zoo_create(zkhandle, "/my_node", "data", 4,&ZOO_OPEN_ACL_UNSAFE, flags, created_path, sizeof(created_path));
if (ret == ZOK) printf("节点创建成功,路径: %s\n", created_path);
- 节点数据的读取(zoo_get)
char buffer[512];
struct Stat stat;
int ret = zoo_get(zkhandle, "/my_node", 0, buffer, &stat);
if (ret == ZOK) printf("获取数据成功: %s\n", buffer);
- 更新节点
char new_data[] = "new data";
int ret = zoo_set(zkhandle, "/my_node", new_data, strlen(new_data), -1);
if (ret == ZOK) printf("更新节点成功\n");
- 检查节点是否存在 (
zoo_exists):
struct Stat stat;
int ret = zoo_exists(zkhandle, "/my_node", 0, &stat);
if (ret == ZOK) printf("节点存在\n");
- 获取子节点列表(zoo_get_children)
struct String_vector children;
int ret = zoo_get_children(zkhandle, "/", 0, &children);
if (ret == ZOK) {for (int i = 0; i < children.count; i++)printf("子节点: %s\n", children.data[i]);deallocate_String_vector(&children); // 释放资源
}
- 删除节点(zoo_delete)
int ret = zoo_delete(zkhandle, "/my_node", -1);
- 关闭连接(zookeeper_close)
zookeeper_close(zkhandle);
3. 封装使用
- ZKClient.h
#pragma once#include <semaphore.h>
#include <string>
#include <vector>
#include <zookeeper/zookeeper.h>class ZKClient {
public:ZKClient();~ZKClient();void Start();void Create(char const *path, char const *data, int datalen, int state = 0);std::string GetData(char const *path, Stat *stat = nullptr);void SetData(char const *path, char const *data, int datalen, int version = 1);void Delete(char const *path, int version = 1);bool Exists(char const *path);std::vector<std::string> GetChildren(char const *path);void Close();void Reconnect();// 获取原始句柄zhandle_t *GetHandle() const {return _zhandle;}private:zhandle_t *_zhandle;int _timeout;std::string _host;
};
- ZKClient.cc
#include "include/ZKClient.h"
#include "Logger.h"
#include "MprpcApplication.h"
#include <cstdlib>
#include <semaphore.h>
#include <string>
#include <zookeeper.h>namespace {void global_watcher(zhandle_t *zh, int type, int state, char const *path, void *watcherCtx) {if (type == ZOO_SESSION_EVENT) {if (state == ZOO_CONNECTED_STATE) {sem_t *sem = (sem_t *)zoo_get_context(zh);sem_post(sem);} else if (state == ZOO_EXPIRED_SESSION_STATE) {log_error("Session expired");// 1. 关闭旧会话zookeeper_close(zh);// 下面的步骤是可能需要做的,这里不予演示// 2. 重新创建链接// 3. 重新创建所有临时节点// 4. 重新注册所有watcher}}
}} // namespaceZKClient::ZKClient() : _zhandle(nullptr), _timeout(30000) { }ZKClient::~ZKClient() {Close();
}void ZKClient::Start() {std::string host = MprpcApplication::GetInstance().GetConfig().Get("zookeeperip");std::string port = MprpcApplication::GetInstance().GetConfig().Get("zookeeperport");_host = host + ":" + port;log_info("Zookeeper Started in {}", _host);_zhandle = zookeeper_init(_host.c_str(), global_watcher, 30000, nullptr, nullptr, 0);if (_zhandle == nullptr) {log_error("Zookeeper_init Error");exit(EXIT_FAILURE);}sem_t sem;sem_init(&sem, 0, 0);zoo_set_context(_zhandle, &sem);sem_wait(&sem);sem_destroy(&sem);log_info("zookeeper_init_success!");
}void ZKClient::Close() {if (_zhandle) {zookeeper_close(_zhandle);_zhandle = nullptr;log_info("Zookeeper connection closed");}
}void ZKClient::Create(char const *path, char const *data, int datalen, int state) {char path_buf[128];int bufflen = sizeof path_buf;int flag;flag = zoo_exists(_zhandle, path, 0, nullptr);if (flag == ZNONODE) /* 节点不存在 */ {flag = zoo_create(_zhandle, path, data, datalen, &ZOO_OPEN_ACL_UNSAFE, state, path_buf, bufflen);if (flag == ZOK) {std::cout << "znode create success:" << path << std::endl;} else {log_error("znode create failed,with path {} ", path);exit(EXIT_FAILURE);}}
}void ZKClient::Reconnect() {log_info("Attempting to reconnect to ZooKeeper...");Close(); // 关闭旧的_zhandle = zookeeper_init(_host.c_str(), global_watcher, _timeout, nullptr, nullptr, 0);if (_zhandle == nullptr) {log_error("Reconnect failed: zookeeper_init error");exit(EXIT_FAILURE);}sem_t sem;sem_init(&sem, 0, 0);zoo_set_context(_zhandle, &sem);sem_wait(&sem);sem_destroy(&sem);log_info("Reconnected to ZooKeeper successfully");
}std::string ZKClient::GetData(char const *path, Stat *stat) {/*将stat作为传出参数,用户可以接受stat结构数据*/char buffer[1024];int buffer_len = sizeof buffer;int flag = zoo_get(_zhandle, path, 0, buffer, &buffer_len, stat);if (flag != ZOK) {log_error("GetData failed :{}", zerror(flag));return "";}return std::string(buffer, buffer_len);
}void ZKClient::SetData(char const *path, char const *data, int datalen, int version) {int flag = zoo_set(_zhandle, path, data, datalen, version);if (flag == ZOK) {log_info("SetData success for path: {}", path);} else {log_error("SetData failed for path {}: {}", path, zerror(flag));exit(EXIT_FAILURE);}
}void ZKClient::Delete(char const *path, int version) {int flag = zoo_delete(_zhandle, path, version);if (flag == ZOK) {log_info("Delete success for path: {}", path);} else if (flag == ZNONODE) {log_info("Delete: node does not exist, path: {}", path);} else {log_error("Delete failed for path {}: {}", path, zerror(flag));exit(EXIT_FAILURE);}
}bool ZKClient::Exists(char const *path) {int flag = zoo_exists(_zhandle, path, 0, nullptr);return (flag == ZOK);
}std::vector<std::string> ZKClient::GetChildren(char const *path) {std::vector<std::string> children;struct String_vector strings;int flag = zoo_get_children(_zhandle, path, 0, &strings);if (flag != ZOK) {log_error("GetChildren failed for path {}: {}", path, zerror(flag));return children;}for (int i = 0; i < strings.count; ++i) {children.emplace_back(strings.data[i]);}deallocate_String_vector(&strings);return children;
}
扩展知识
1.特点

- Zookeeper:一各领导者(Leader),多个跟随者(Follower)组成的集群
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务,所以zookeeper适合安装奇数台服务器
- 全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的
- 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
- 数据更新原子性,一次数据更新要么成功,要么失败
- 实时性,在一定时间范围内,client能读到最新数据
2.Zookeeper的选举机制(参考:完整教程:ZooKeeper详解)
ZooKeeper 的选举机制是它保证强一致性和高可用性的核心。它的主要目标是在集群中通过投票协商,快速选出一个唯一的 Leader 节点来负责处理写请求。
当集群初次启动或运行中Leader 宕机时,选举就会触发。整个过程基于 FastLeaderElection 算法,核心逻辑可以概括为“比较事务 ID 和服务器 ID,获得过半票数者当选”。
1.第一次启动选举机制
Zookeeper 的选举机制确保集群中的所有节点对外表现为一个统一的服务。选举机制分为两个阶段:Leader 选举 和 投票确认。
- 服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
- 服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
- 服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
- 服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态FOLLOWING;
- 服务器5启动,同4一样当小弟。
2.非第一次启动选举机制
-
当ZooKeeper 集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
1)服务器初始化启动。
2)服务器运行期间无法和Leader保持连接。 -
而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
1)集群中本来就已经存在一个Leader。
对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和 Leader机器建立连接,并进行状态同步即可。2)集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
选举Leader规则:
① EPOCH大的直接胜出 任期,Epoch大的获选
② EPOCH相同,事务id大的胜出 数据最接近leader的,事务id越大,ZXID大的获选
③ 事务id相同,服务器id大的胜出 myid大的获选
3.局限性
1.不适用于海量数据存储
ZooKeeper将所有数据(ZNode)完全加载在内存中,以保证高性能读操作。这直接决定了它不能作为数据库使用,只适合存储元数据、配置信息等小型关键数据。单个ZNode的数据大小官方建议不超过1MB。
2.写性能存在单点瓶颈
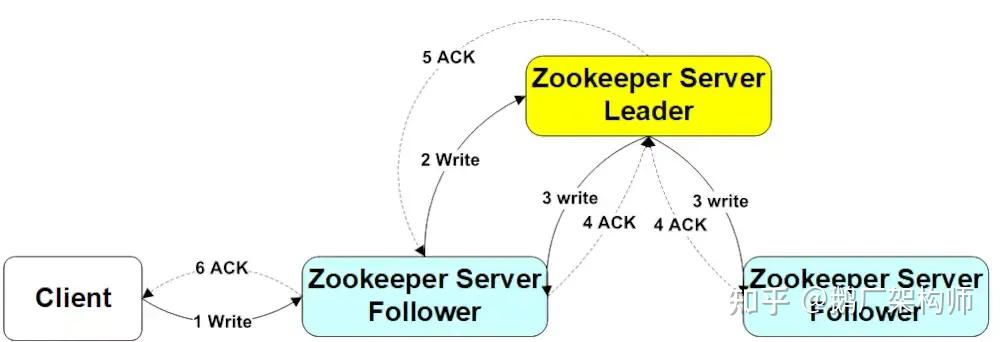
ZooKeeper的写性能单点瓶颈,这个问题的根源在于它作为强一致性(CP)系统的设计哲学,具体体现在原子广播协议(ZAB)的工作机制里。
在分布式系统中,保证数据一致性最直接的方式是指定一个唯一的决策者来给所有写操作排序。ZooKeeper集群中,只有一个Leader节点扮演这个角色。
一个写请求的耗时由多个串行步骤构成,每个环节都可能成为瓶颈。
最重要的一点:无法通过“增加节点”实现线性扩展。
- 法定人数的代价:集群中能容忍的故障节点数增加了,但代价是Leader必须等待更多Follower的响应。3节点集群只需等待最快的那一个Follower,而7节点集群必须等待(至少)最快的三个Follower。等待慢节点的概率急剧上升。
- 广播开销线性增长:Leader需要将事务广播给集群中的每一个节点(不仅仅是法定人数节点)。节点的增加意味着更多的网络I/O和CPU消耗,这些都是Leader的单机资源。
- Leader的压力只增不减:整个集群的写性能被锁定在Leader的单机处理能力上。这是一场Leader单挑整个集群的游戏,增加Follower只会给Leader增加负担,而不会分担任何写负载。
3. 不适合做消息队列.
ZooKeeper官方食谱曾提到可用于队列,但这是一个公认的糟糕实践。原因在于:
- 用为消息队列会快速创建海量子节点,而单个节点子节点过多会严重拖慢性能,甚至难以清理。
- 一旦数据量增长,启动和恢复时间会变得极长(Netflix分享过因滥用导致重启耗时10-15分钟的案例)。