1M token 上下文设置下,DeepSeek-V4-Pro 的单 token 推理 FLOPs 仅为 DeepSeek-V3.2 的 27%,KV Cache 仅为 V3.2 的 10%;V4-Flash 更激进——FLOPs 10%、KV Cache 7%。百万上下文从演示用 demo,变成了可以日常跑的工作负载。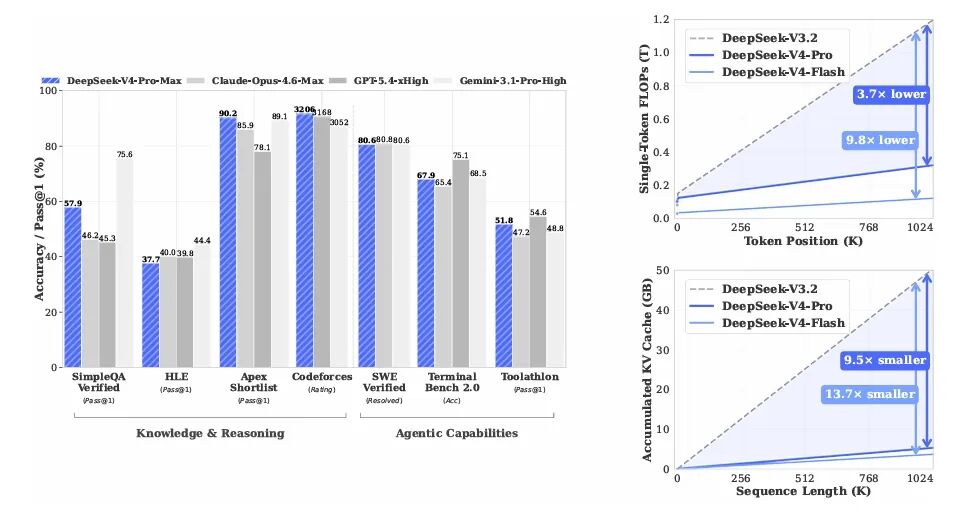
过去两年大模型的进步基本沿着两条主线:一条是 reasoning 模型靠更长的思考链做 test-time scaling 刷指标;另一条是 agentic 工作流——动辄要处理跨多文档、多工具调用的长 horizon 任务。这两条路都十分需要 context length,而 vanilla attention 是 O(n²) 的:上下文每翻一倍,attention 部分的算力和显存都要翻四倍。这就是为什么大多数开源模型号称 128K,但是到了真实 64K 已经卡顿。
DeepSeek-V4 想解决的正是这个问题,用混合稀疏注意力(CSA + HCA)把 KV Cache 沿序列维度狠压一刀,用 mHC(流形约束的超连接)顶住深层堆叠的数值不稳定,用 Muon 优化器加快收敛,再用 FP4 量化感知训练把 MoE 权重砍一半,这样1M 上下文的边际成本被压到能用的程度。
本文围绕三个问题:长上下文效率到底怎么破(架构);万亿 MoE 怎么稳定训练(基础设施 + trick);十几个领域专家如何合并成一个模型(后训练)。
https://avoid.overfit.cn/post/96c19e7a2337440ca6edeec7e36191b3