这两年,不管你刷朋友圈、刷视频、看新闻还是逛B站,"AI"两个字无处不在。
ChatGPT能写文章,Midjourney能画画,Sora能做视频,Claude Code、OpenCode可以写代码,还有各种AI能做PPT、陪孩子练英语……
听起来很高大上对吧?
但也有很多人心里发慌:"AI这么厉害,我会不会被淘汰?""这些玩意儿到底是怎么运作的?""我一点技术都不懂,是不是注定要被甩在后面?"
如果你也有这些担忧,这篇文章就是专门写给你的。
晓凡不会扔一堆晦涩的术语,也不会制造焦虑告诉你"不学AI就完了"。
我想用最通俗的方式,帮你把这几个天天听到的概念彻底搞懂:
- AI的两大类型:生成式AI和判别式AI
- 大语言模型
- Token
- 提示词工程与上下文工程
- 开源模型与闭源模型
- 隐私安全与使用边界
读完你会发现:AI没有你想象的那么神秘,你也没有自己想象的那么落后。
一、AI早就存在了
很多人以为AI是2023年才突然冒出来的新事物,并不是。
你每天都在用AI,只是没意识到而已。
- 打开高德地图,它给你推荐最优路线——这是AI
- 微信输入法自动猜你想打什么字——这是AI
- 刷抖音,它总推你爱看的内容——这是AI
- 美颜相机自动帮你P图——这也是AI
- 手机人脸解锁、银行识别可疑交易、音乐App推荐歌单——全都是AI
那为什么ChatGPT一出,大家突然感觉"不一样了"?
以前的AI是"藏在背后的",你不知不觉就用上了;
ChatGPT是"直接跟你对话的",你一句它一句,像跟真人聊天一样。这种"像人"的感觉,一下子把距离拉近了。
但拉近归拉近,很多人反而更懵了:
"它怎么能听懂我的话?"
"它到底是真的'懂',还是在瞎编?"
"我问它问题,为什么有时候答案好,有时候又胡说八道?"
别急,我们从最基础的开始,一层一层剥开。
二、AI的两大门派
在深入之前,先理清楚一个最基础的概念:AI不只有聊天机器人。
如果把AI比作一座冰山,ChatGPT只是浮在水面上的那一小块。水面之下,AI的技术家族远比想象中庞大。按功能来分,主要有两大门派:
| 类型 | 功能 | 生活例子 |
|---|---|---|
| 生成式AI | 创造新内容 | ChatGPT写文章、Midjourney画画、Sora做视频 |
| 判别式AI | 识别和判断 | 当您上传一张图片,AI告诉您"这是一只猫";人脸识别、垃圾邮件过滤、医学影像诊断 |
你手机的人脸解锁,是判别式AI在判断"这张脸是不是主人";
而ChatGPT、Midjourney这些之所以让人感到震撼,是因为它们是"生成式AI"——不是做判断,而是从无到有地"创造"内容。
写一段你没见过的文字、画一幅全新的画、生成一段从未拍摄过的视频,这在过去只有人类能做到。
理解了这一点,你就明白:AI不是在"模仿人类思考",而是在"模仿人类的产出"。这个区别很关键,我们接着往下说。
三、AI到底是什么?
要讲清楚AI,得先破除一个最大的误解。
AI不是人,没有意识、不思考、无情感。它只会做一件事——基于概率,预测下一个词。
那它为什么能回答你的问题?
- 它读过互联网上几乎所有公开文字(小说、论文、代码、问答……)
- 它不"理解"内容,只记住文字之间的规律
- 你给上半句,它猜最可能的下一个词,再猜下一个,直到凑成回答
所以核心事实是:
AI不是在"思考",而是在"模仿思考的样子"。
它说起来像懂你,只是因为训练时见过太多"问题→答案"的组合,知道"什么词接在这里最像正确答案"。像一个背熟了台词的演员,演得很像,但不是真的在对话。
这样又引出了两个词:训练 vs 推理
| 阶段 | 类比 | 说明 |
|---|---|---|
| 训练 | 实习生在大学读书 | 消耗海量算力,大公司花费数千万美元 |
| 推理 | 实习生毕业来上班 | 你每次提问就是在调用"推理" |
你每次和AI聊天,它并没有在"学习"。 你的对话不会实时改变它的"大脑"(除非用了"记忆"或"微调"功能)。
也正因为它本质是"猜",才有了后面要说的致命短板。不过在那之前,先看它这两年补上了什么——多模态。
早期的AI只会读文字,像个只会读书的实习生。现在不一样了:GPT-4o、Claude 3.5等模型已能同时看懂图片、听懂语音。你扔一张菜单照片,它能推荐菜品;你发一段语音,它能文字回复。
从"只会读书"升级到"能看、能听、能说"。
(致命短板是什么?下一节讲"幻觉"和"偏见"。)
四、大语言模型
"大语言模型"(LLM,Large Language Model)这个词听起来很吓人,拆开看就懂了:
- 大:看过天文数字般的文字
- 语言:处理的是文字
- 模型:一套数学规律(不是机器)
就是刚才说的那个"读过全世界书的实习生"。

优点:知识面广
你问它唐诗,它能背;你问它Python代码,它能写;
你问它怎么做红烧肉,它能给你步骤。
它什么都"看过一点",所以什么都能聊。
缺点:两个致命短板
- 幻觉
①会"一本正经地胡说八道"(幻觉)。
它不是查数据库,而是在"猜下一个词"。没看过正确答案也不会说"不知道",而是硬编一个最像的。像个考试没复习的学生,不会空着,会蒙一个答案。
②不知道自己不知道什么。
你问它"晓凡家门口的树龄",它不知道你家在哪,但照样给你编个数字。
铁律:把它当"知识渊博但缺乏判断力的实习生",别当"全知全能的老师"。
- 偏见
训练数据来自互联网,而互联网充满性别、文化、地域等偏见。AI不会纠正,只会原样学习甚至放大。
问"程序员是什么样的人",它可能答"男性、戴眼镜、穿格子衬衫"——这是刻板印象,不是事实。
涉及医疗、法律、招聘、投资等敏感话题,AI的回答必须人工核实,只作参考。
说完模型本身的问题(幻觉、偏见),再来说一个跟你直接相关的选择:你用的AI,是开源还是闭源?
开源模型 vs 闭源模型:你用的是哪一种?
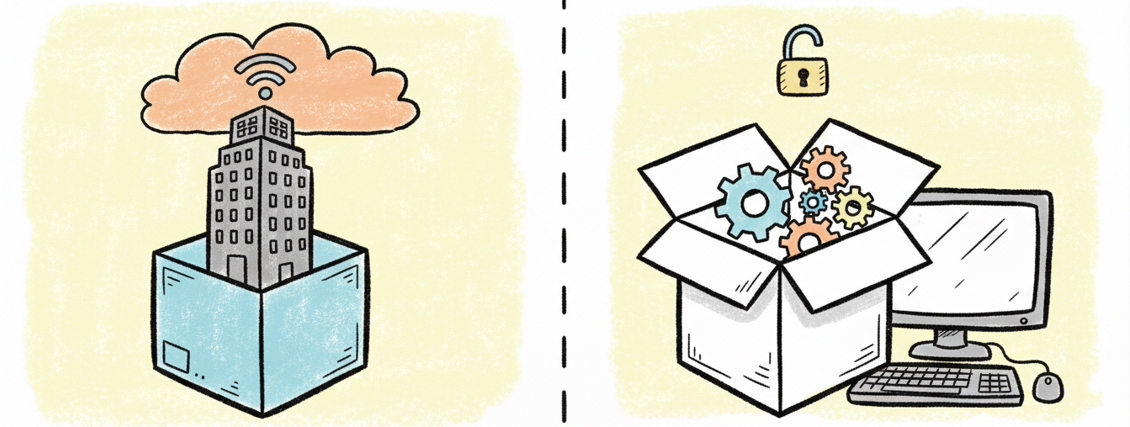
文章里我提到了ChatGPT、Claude等,但你可能不知道,AI模型还分为开源和闭源两大类:
| 类型 | 代表 | 特点 |
|---|---|---|
| 闭源模型 | GPT-4、Claude、Gemini |
大公司控制,API调用收费,通常功能最强,使用最方便 |
| 开源模型 | Llama(Meta)、Qwen(阿里)、DeepSeek-R1 |
代码和参数公开,可以下载到自己的电脑上运行 |
对普通用户来说,两者的区别主要在于:
- 闭源模型:开箱即用,不用折腾,但你的对话数据会发送到对方服务器
- 开源模型:可以自己本地部署,数据完全留在自己电脑上,隐私性最好,但需要一定的技术门槛
如果你处理的是公司机密文件、个人隐私资料,或者对数据安全要求很高,本地部署开源模型是一个值得考虑的选项。
五、Token
很多人第一次听说"Token",是在看到某个AI产品的定价页面上——"0.002美元/千Token"。
Token到底是什么?
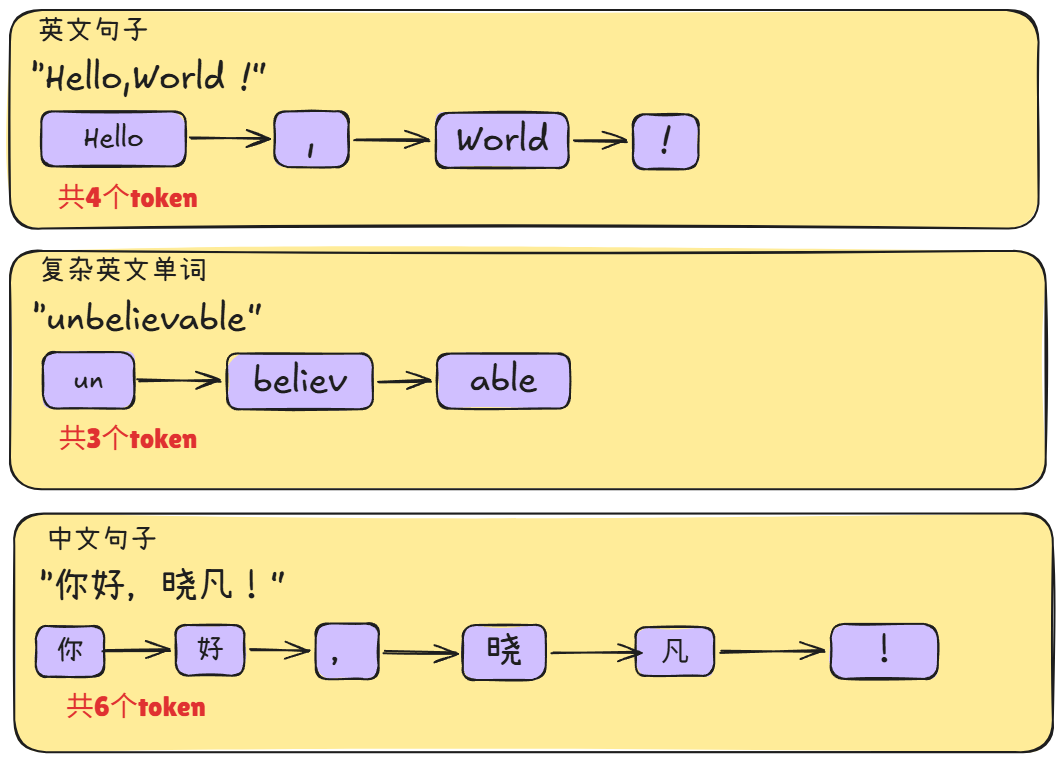
Token就是AI处理信息的最小单位,中文名叫词元。你可以理解为AI世界里的文字碎片,或者AI世界的燃料。
就像人类阅读时以词语为单位来理解意思,AI也不会逐个字母地处理文字——它会先把文本切割成一块一块的碎片,每一块就叫做一个Token。
很多人会以为Token = 单词,其实并不完全是。对AI来说:
| 文本 | token数 | 说明 |
|---|---|---|
dog |
1 | 常见词,直接一个Token |
unbelievable |
3 | un + believ + able |
ChatGPT |
3 | Chat + G + PT |
| 你好 | 约2~3 | 中文通常比英文消耗更多Token |
Token小常识
- Token比单词更细,比字母更粗,是一种灵活的中间单位。
- 1,000个Token ≈ 750个英文单词,是一个常用的估算比例。
- 中文、日文、韩文等亚洲语言通常比英文消耗更多Token。
- 空格和标点也算Token!不要以为只有文字才计数。
- 代码的Token消耗一般比自然语言少,因为编程语言结构紧凑。
所以当你看到某款模型说"支持200万Token上下文"时,换算过来大约是150万到300万汉字。
这意味着,现在的顶级AI可以一次性读完《红楼梦》+《三国演义》,还能在回答你问题时,准确引用其中任何一段对话。
Token为什么重要?因为它决定了三件事:
1. AI能读多长
老款AI只能装几千Token,像小鸟胃,读半本小说就撑了。2026年新模型能装几百万Token,进化成了大胃王。
2. AI能记住多少对话
聊一下午你会发现AI开始"失忆"——忘了半小时前的要求。不是它捣乱,是Token容量到上限了。
3. 你要花多少钱
你写的和它回的,每个字都算Token。对话越长,越贵越慢。
说到跟钱有关的,当然是我们最关心的。
就因为token如此烧钱,这里曾经就有了个小插曲
有网友基于"文言文言简意赅"的特点,推断用文言文与AI交流可减少字数,从而节省token和API调用成本。
实验证明,这个推论是错误的——token不是按字数计算,而是模型内部算法确定的最小处理单位。
中文消耗Token通常比英文多1.3-2倍,文言文由于模型对其"压缩率"不如现代白话,反而可能消耗更多Token。
所以,给普通人的实用建议:
- 长文档优先选支持大上下文的模型(如
Claude、DeepSeek、Gemini),别拿老模型硬塞一本小说进去。 - 发现AI开始"失忆",就开启新对话,或者把之前的要点总结成一段精简的话发给它。
- 与其刻意使用文言文,不如优化提问方式,使用清晰简洁的白话文,避免冗余表达。
- 不需要被Token计费吓到,日常对话其实很便宜,但对于企业级应用,这确实是成本大头。
六、怎么跟AI说话?
理解了AI的本质和它的限制("Token容量"),下一个问题就是:我怎么才能让它给我最好的回答?
这就涉及到两个概念:提示词工程和上下文工程。
1. 提示词工程:学会"说清楚"
提示词(Prompt)就是你发给AI的那段话。提示词工程,就是研究"怎么说,AI才能听明白"。
前几年,网上流传着各种"魔法咒语":
- "你是一个资深专家……"
- "请你一步步思考……"
- "如果回答得好,我会给你小费……"
这些技巧有用吗?确实有用。因为它们本质上是在给AI更明确的"上下文线索",帮它更好地"接龙"。
但到了2026年,模型越来越聪明了,你不需要那么"哄"它了。你说"帮我写个文案",它已经能给出不错的结果。
那提示词工程还有用吗?当然有用。
只是它从"玄学咒语"升级成了"结构化表达"。一个高质量的提示,现在通常长这样:
角色:你是一位有5年经验的技术公众号博主。
背景:我要写一篇《Spring Boot 3.0新特性》的推文。
任务:帮我想5个让人忍不住点开的标题。
要求:口语化、带点自嘲、拒绝"震惊体",每个标题15字以内。
示例:"升级Spring Boot 3.0后,我的代码居然变懒了"
你看,这不是"话术技巧",这是"写需求文档"。你把需求说清楚了,AI自然给得好。
2. 上下文工程:学会"给足材料"
如果提示词工程是"你怎么跟实习生说话,他才能明白",那上下文工程就是"你给实习生准备资料"。
举个例子:
你对实习生说:"帮我写一份市场分析报告。"
这是提示词工程——你在研究"怎么说"。
但如果直接给实习生公司的过往报告、行业数据、竞争对手资料——这时候他写出来的报告,肯定比空口说一句要好得多。
这就是上下文工程:不只是说话,而是给AI搭建一个"信息环境"。
现在的AI,已经能读文件、查资料、调用工具了。现在的重点不再是"我怎么说得好",而是"我给AI准备了什么材料"。
具体怎么做?
- 上传参考资料:别只给一句话,把相关文档传上去
- 设定系统指令:给AI一个长期有效的"身份卡"和"行为守则"
- 使用工作区/知识库:把常用背景信息固定下来
- 连接外部工具:让AI能查你的日程、读你的邮件、访问你的数据库
七、隐私与安全

在继续之前,有一个话题必须认真聊聊——隐私与安全。
很多新手使用AI时,完全没意识到自己在"泄露"什么。请记住以下几条铁律:
🚫 这些信息,永远不要输入给AI
- 身份证号、银行卡号、密码
- 公司机密文件、未公开的合同、商业计划
- 他人的隐私信息(比如客户的个人资料)
⚠️ 使用免费AI产品时请注意
大多数免费版AI产品(包括ChatGPT免费版、Claude免费版等),可能会用你的对话来改进模型。
这意味着你说的话,理论上可能被人工审核团队看到。虽然大公司都有隐私保护措施,但"可能被人看到"这个风险客观存在。
🔒 如何保护自己的隐私?
| 场景 | 建议做法 |
|---|---|
| 处理日常问题、公开知识 | 使用任意在线AI即可 |
| 处理公司内部文件 | 选择企业版(有保密协议)或本地部署开源模型 |
| 处理高度敏感信息 | 务必本地部署,数据不出自己的电脑 |
| 不确定时 | 把敏感信息替换成"某公司""某客户"等代称 |
八、国内用户怎么选?
我前面提到ChatGPT、Claude比较多,但很多朋友可能根本访问不了这些国外服务。别担心,国内的AI工具已经非常好用了。
以下是2026年国内用户可以直接访问的主流AI工具:
| 工具 | 开发商 | 特点 | 适合场景 |
|---|---|---|---|
| DeepSeek | 深度求索 | 推理能力极强,数学和代码突出,免费 | 编程、逻辑推理、深度问题 |
| Kimi | 月之暗面 | 长文档处理能力突出 | 读论文、总结报告、处理长文本 |
| 豆包 | 字节跳动 | 日常对话自然,集成搜索 | 日常问答、写作、信息查询 |
| 通义千问 | 阿里巴巴 | 办公场景集成好,有企业版 | 办公文档、表格处理、企业应用 |
| 文心一言 | 百度 | 中文理解扎实 | 中文写作、知识问答 |
| 智谱清言 | 智谱AI | 学术风格,开源模型能力强 | 学术研究、技术问题 |
给新手的建议:
- 先选一个主用:不需要每个都试,推荐从DeepSeek(推理强)或豆包(日常好用)开始
- 准备一个备用:不同模型各有擅长,一个搞不定就换另一个试试
- 能上传文档的优先:上下文工程时代,"能读文件"比"会说话"更重要
九、破除AI焦虑
聊完这些概念,我想专门花一段,聊聊很多人的真实焦虑。
Q1 焦虑一:"AI这么厉害,我会不会被取代?"
答案是:短期内不会完全取代,但它正在改变很多岗位的工作内容。
AI取代的不是"会使用AI的人",而是"重复性劳动"和"拒绝使用AI的人"。
它写得了周报模板,但写不出你独特的洞察;它画得了商品图,但给不出你独特的审美判断。
未来的竞争力不是"你比AI强",而是"你比不会用AI的人强"。
Q2 焦虑二:"我一点技术都不懂,学AI是不是很难?"
答案是:比你想的简单一百倍。
使用AI不需要学编程,不需要懂数学,不需要看论文。你只需要学会一件事:把需求说清楚。
就像你不会修汽车,但你照样能开车。你不需要知道发动机怎么运作,你只需要知道油门、刹车、方向盘怎么用。
Q3 焦虑三:"AI会不会失控?会不会自己决定干坏事?"
答案是:今天的AI本身没有意识,不会"主动"干坏事。
但需要注意两个风险:
- 使用AI的人可能用它做坏事(如诈骗、造谣、深度伪造)
- 当AI被赋予过多自主权(如自动操作电脑、转账)时,即使无恶意也可能因理解偏差造成损失
所以关键不是"AI会不会失控",而是我们怎么设计安全边界、怎么监管使用它的人。
就像刀可以用来做菜,也可以用来伤人——关键在于拿刀的人。
十、这样和AI"打招呼"
读完这篇文章,如果你跃跃欲试,这里有三个零门槛的第一次尝试:
尝试一:用"结构化提问"代替"一句话提问"
不要只问:"帮我写个文案"
试试这样问:"你是一位有经验的技术公众号博主,请为一款程序员防脱发洗发水写一段产品介绍,目标用户是25-35岁程序员,突出'代码写不完,头发要保住',语气自嘲幽默,300字以内。"
感受一下,输出质量的区别。
尝试二:上传一份文档,让AI基于材料回答
找一篇你最近看过的技术文档,或者一份工作报告,上传到AI对话框里(DeepSeek、Kimi、豆包都支持),然后问它:"这篇文章的核心观点是什么?有哪些地方我可以直接用到项目里?"
你会发现,AI"有材料可依"时的回答,比凭空回答靠谱得多。
尝试三:建立一个你专属的工作区
如果你用DeepSeek、豆包、Kimi或其他AI助手,花5分钟建立一个"自定义指令"或"项目工作区",把你的常用需求写进去。
以后每次打开,AI都知道你是谁、你要什么风格,不用每次都从头交代。
写在最后
写这篇文章的目的,不是让你立刻变成AI专家,而是想告诉你:
AI没有那么神秘,你也没有那么落后。
它就是一个"读过全世界书的实习生"——知识面广,但需要你给方向;模仿力强,但需要你给边界;反应快,但需要你给材料。
你不需要被它吓到,你只需要学会怎么"使唤"它。
下一篇文章,我会继续讲几个你可能听过但一知半解的概念:RAG(给AI装上专业资料库)、AI Agent(让AI能自己干活)、MCP(AI与外部世界的标准接口)。
它们是给这个AI装上记忆、执行能力和外部协作能力的关键技术。
本期内容到这儿就结束了 (●'◡'●)
我们下期再见 ヾ(•ω•`)o