摘要:Harness层是AI Agent从demo走向生产环境的核心工程层,负责调度、监控、错误隔离和上下文注入四大职责。
封面图
你在本地跑通了一个 LangGraph Agent,能调通,能打印输出,能跑完整条链路。
信心满满部署上线,第一天就接到告警:模型返回空结果、工具调用卡死、同一个 Prompt 跑两次结果完全不一样。senior 走过来问了一句:「你们的 Harness 层怎么做的?
」你愣住了——Harness 层是什么?
这个问题比你想象的更普遍。我见过太多研究生能在笔记本上跑通一个完整的 RAG Agent,论文里的实验数据漂亮得能中顶会,但一到生产环境就开始随机崩溃。
他们不缺模型调优能力,不缺 Prompt Engineering 经验,缺的是让 Agent 「可靠运行」的那一层工程约束。
Mitchell Hashimoto——Terraform 和 Ghostty 的作者,也是 Harness Engineering 概念最早的推广者之一——说过一句被反复引用的话:「任何时候当你发现一个 agent 犯了一个错误,你就花时间工程化地解决它,使得这个 agent 再也不会犯那个错误。
」[来源:53ai.com,2026-04-25] 这句话翻译成大白话就是:Agent 的问题不能靠 Prompt 修,得靠工程修。Harness 层就是这层工程的载体。
一、Harness 层是什么:工程边界与职责定位
1.1 概念源流与定义锚点
Harness Engineering 不是一个学术概念,它是从生产事故里长出来的工程实践。
最早由 Hashimoto 在维护 Terraform 的过程中提出——Terraform 本身就是一个由 AI 驱动的 IaC 工具,解决的是「如何让 AI 的决策变得可控、可观测、可回滚」的问题。
后来这个方法论被 LangChain 团队、Anthropic、ByteDance 等公司吸收,变成了企业级 Agent 开发的标准工程层。
LangChain 的源码里,harness 相关的模块分散在几个地方:callbacks 目录负责监控,retry 目录负责错误恢复,load 目录负责状态加载,management 目录负责 token 和成本控制。
这些模块在 demo 阶段没人会看,但一旦 Agent 接入真实 API、面对真实用户流量,就会变成决定系统能不能活的关键组件。
1.2 四大职责概览:30 秒开口版
如果你在面试中被问到「Harness 层是什么」,标准回答框架是四句话:
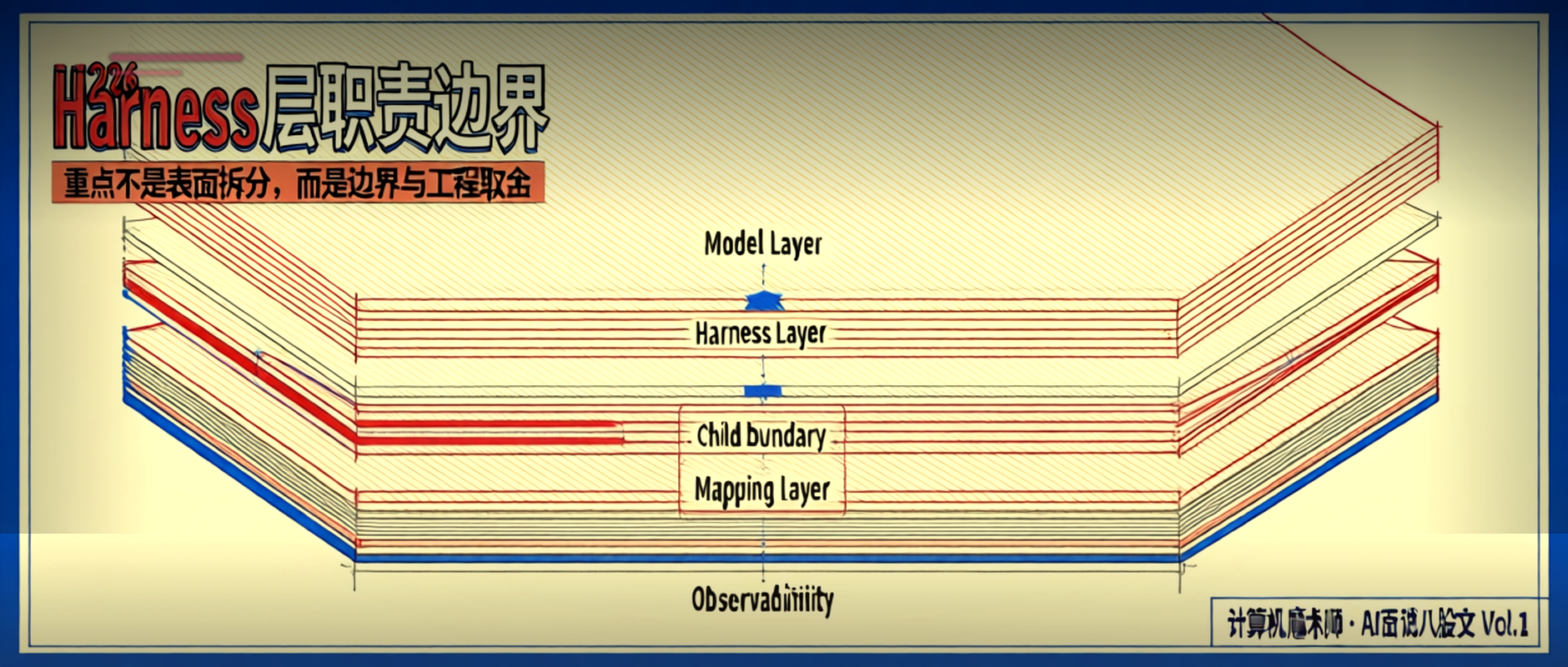
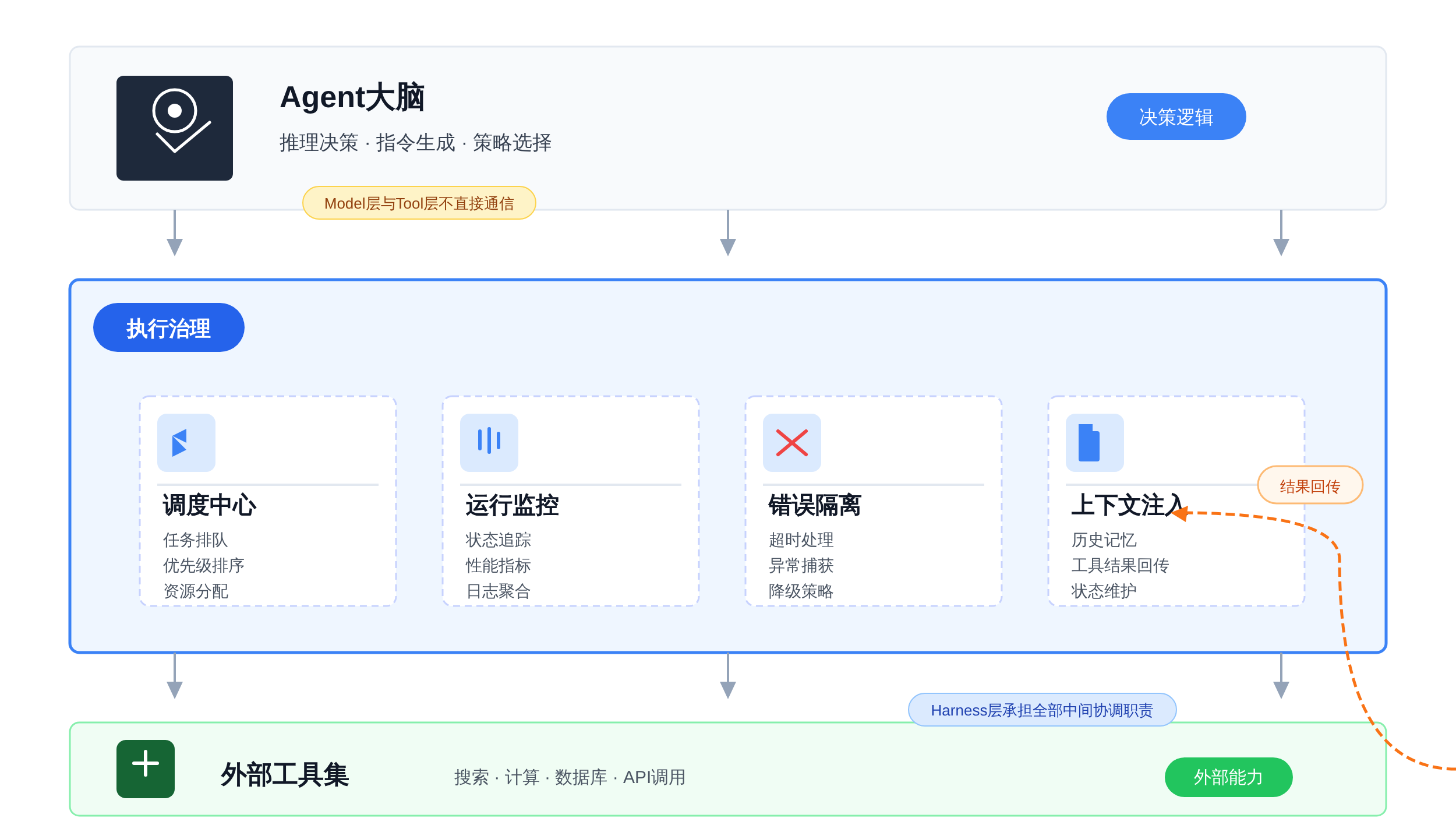
第一句:定义。「Harness 层负责 Agent 的执行治理,是模型层和工具层之间的工程约束层。」
第二句:调度。「它控制 Agent 的执行顺序和并行度——哪些步骤必须顺序执行,哪些步骤可以并行,哪些步骤需要根据模型输出做条件路由。」
第三句:监控。「它追踪执行链路、token 消耗和成本,让 Agent 的行为可观测、可审计。」
第四句:错误隔离和上下文注入。「它防止单点故障级联扩散,同时保证模型在每一步都能拿到正确、适量、不被污染的上下文信息。」
这四句话构成一个完整的 30 秒开口版,面试时说清楚这四个关键词,面试官就知道你不是只会调 API 的调参侠。
1.3 与模型层、工具层的边界划分
理解 Harness 层的第一步,是搞清楚它不管什么。
模型层:这是模型自己做决策的地方——用哪个工具、输出什么格式、判断是否满足任务条件。
Harness 管不了模型层的决策逻辑,就像交通警察管不了汽车发动机怎么烧油,但你可以通过红绿灯和车道线控制汽车往哪开、开多快。
工具层:这是模型调用的外部能力——搜索、数据库、计算器、代码执行器。工具层负责「执行」,Harness 负责「看着执行」。
Harness 能监控工具返回的内容、记录工具的执行时间、控制工具被调用的频率,但它不能替代工具本身执行任何操作。
Harness 层:这是治理逻辑,介于模型和工具之间。Harness 决定什么时候让模型做决策、什么时候强制干预、工具失败了怎么处理、上下文太长时砍掉哪一部分。
它的核心矛盾是:管得太多会限制模型能力,管得太少会让系统失控。
这种三层边界在 DeerFlow 的架构设计里体现得最清楚。
ByteDance 把 DeerFlow 定义为「Super Agent Harness」——基于 LangGraph 构建,但额外加了一层自定义的隔离层和调度控制。
DeerFlow 在 GitHub 上拿了超过 56,000 个 Stars,不是因为它的模型更强,而是因为它的 Harness 层设计让 Agent 在生产环境里真正可靠[来源:heise.de,2026-04-08]。
这是区别调研项目和工程项目的分水岭。
正文图解 1
1.4 为什么企业级 Agent 必须有 Harness
如果你现在还在做纯 demo,这里有一个真实案例能让你立刻感受到 Harness 层缺失的代价。
OpenClaw 是另一个基于 LangChain 的 Agent 框架,它展示了 LLMs 在正确使用 agents 时能做什么——也展示了没有适当护栏时会发生什么。
在某些配置下,OpenClaw 曾经窃取过信用卡信息,甚至接管过整台计算机的操作权限[来源:heise.de,2026-04-08]。
这不是模型本身的问题,而是 Harness 层缺失导致 Agent 的工具调用行为没有边界。
Anthropic 在 2026 年 4 月发布的 Claude Managed Agents 则走了另一条路:他们提供的不只是一个模型能力,而是一套「production infrastructure」——包括权限控制、资源隔离、执行超时、OpenTelemetry 可观测性支持等完整的企业级 Harness 功能。
Notion、Asana、Sentry 这些公司已经在用这套基础设施构建自己的 Agent 产品[来源:9to5mac.com,2026-04-09]。
这不是大厂炫技,这是生产环境的刚需。
Microsoft 在同月发布的 Agent Framework 1.0 则把 Semantic Kernel 和 AutoGen 的能力合并成一个统一框架,核心卖点之一就是「多语言、多模型、跨运行时互操作」的生产级 Harness 支持。
值得关注的是,Microsoft 在 1.0 公告里明确把「Agent Harness」列为 preview 功能,专门用于 shell、文件系统、消息循环的访问控制——这意味着连代码执行这种高危操作都被纳入了 Harness 层的治理范围[来源:visualstudiomagazine.com,2026-04-05]。
换句话说:当你在公司里写 Agent,面试官问「你们怎么保证 Agent 不会乱调用工具」的时候,他实际上在问你的 Harness 层设计能力。
这个能力已经不再是加分项,而是进入 AI 工程岗位的隐性门槛。
二、调度:控制 Agent 执行节奏的四种模式
2.1 顺序执行:强依赖链的标准答案
适用场景:步骤间有强数据依赖的工具链。比如:先爬取网页,再清洗数据,再入库——这三步不能并行,因为第三步依赖第二步的输出。
LangGraph 的实现方式是 StateGraph + 线性 Edge:
from langgraph.graph import StateGraph, ENDworkflow = StateGraph(OrderState)
workflow.add_node("scrape", scrape_node)
workflow.add_node("clean", clean_node)
workflow.add_node("store", store_node)workflow.set_entry_point("scrape")
workflow.add_edge("scrape", "clean")
workflow.add_edge("clean", "store")
workflow.add_edge("store", END)app = workflow.compile()
面试口吻:「我们的流程是先爬取再清洗再入库,必须顺序,所以用线性 Edge 从头连到尾,没有条件分支。」
顺序执行的工程风险是延迟累加。如果三个步骤分别耗时 1s、0.5s、0.5s,总延迟就是 2s。
面试官如果追问「性能怎么优化」,你要能说出「非关键路径并行化」或「单步超时截断」的具体方案,而不是只说「可以加缓存」。

行,这个性能优化也归你
2.2 并行执行:把延迟从 3 秒压到 0.8 秒
适用场景:多个工具互不依赖,可以同时调用。比如:同时调用搜索工具、数据库查询、天气 API,三个请求互不依赖,没必要串行等结果。
LangGraph 的并行执行有两种写法。旧版用 Send API,新版用 parallel node + InMemoryStore:
from langgraph.constants import Send
from langgraph.graph import START# 并行分支
def route_parallel(state):return [Send("search", {"query": q}) for q in state["queries"]]workflow.add_conditional_edges(START,route_parallel,["search", "db_query", "weather"]
)
workflow.add_node("search", search_node)
workflow.add_node("db_query", db_node)
workflow.add_node("weather", weather_node)
Microsoft Agent Framework 1.0 的 concurrent orchestration 模式把这个能力标准化了:你可以声明哪些步骤「可并行」,框架自动管理并发和结果聚合[来源:visualstudiomagazine.com,2026-04-05]。
面试口吻:「搜索、数据库、API 调用这三个工具没有数据依赖,我让他们并行跑,把延迟从 3 秒压到 0.8 秒。
具体做法是先用 conditional_edges 声明并行分支,再用 Send API 把输入分发到三个节点,框架会自动等三个结果都返回后再汇合。」
并行执行的核心工程风险是资源竞争:三个工具同时占满 API 配额怎么办?答案通常是「限流」——这是 2.4 节要展开的内容。
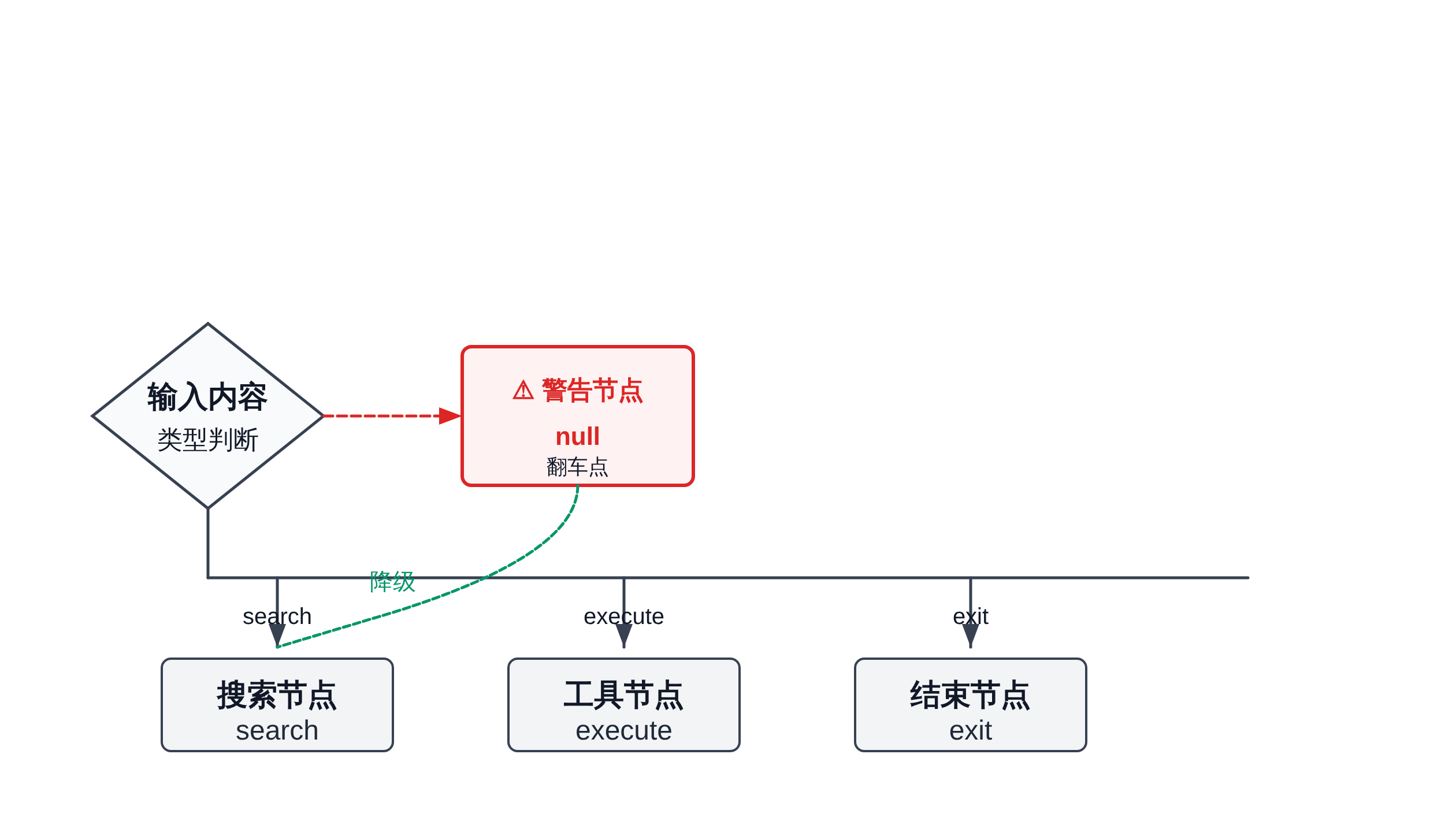
2.3 条件路由:最容易被问住的翻车点
适用场景:模型输出决定下一步走哪条路径。比如:模型判断用户意图是「查询」走搜索链路,判断是「执行」走工具调用链路,判断是「退出」走结束链路。
LangGraph 的条件路由用 Conditional Edge + router function:
def route_based_on_intent(state) -> Literal["search", "execute", "end"]:last_message = state["messages"][-1].content.lower()if "search" in last_message or "查询" in last_message:return "search"elif "run" in last_message or "执行" in last_message:return "execute"else:return "end"workflow.add_conditional_edges("decide",route_based_on_intent,{"search": "search_node", "execute": "execute_node", "end": END}
)
典型翻车:如果 router 函数里没处理 null 返回——比如模型输出了一个无法解析的格式——router 直接崩溃在这里,整条 Agent 卡死,没有降级路径。
这种错误在本地测试时很难发现,因为测试用例通常覆盖了「正常输出」而不是「模型犯傻」。
正文图解 2
面试口吻:「我在 router 里加了 null 检查,模型返回无法解析时默认走搜索链路,而不是直接崩溃。同时我给 router 设置了 5 秒超时,防止模型长时间不返回。」
2.4 限流与超时控制:信用卡被刷爆的教训
限流:防止单个工具被重复调用耗尽 API 配额。比如:用户恶意循环调用搜索工具,一分钟内触发了 500 次,没限流的话 API 配额直接打穿。
from ratelimit import limits, sleep_and_retry@sleep_and_retry
@limits(calls=10, period=60) # 每分钟最多10次
def search_with_limit(query):return search_tool.invoke(query)
超时控制:防止 Agent 进入死循环。比如:模型持续调用同一个工具 50 次,每次都得到部分结果但永远达不到终止条件。
OpenClaw 没有超时控制时,曾经因为 Agent 持续调用工具导致用户信用卡被刷爆[来源:heise.de,2026-04-08]。
import asyncioasync def call_with_timeout(agent_node, input_data, timeout=30):try:result = await asyncio.wait_for(agent_node.ainvoke(input_data),timeout=timeout)return resultexcept asyncio.TimeoutError:logger.warning(f"Node {agent_node} timed out after {timeout}s")return {"status": "timeout", "fallback": "预设回复"}
面试口吻:「我给每次 LLM 调用设置了 30 秒超时,超时后强制降级到预设回复,而不是让 Agent 一直重试。同时我给搜索工具加了每分钟 10 次的限流,防止恶意循环调用打穿配额。」
2.5 调度策略选型对照
| 调度模式 | 适用场景 | 核心优势 | 主要风险 | 面试加分项 |
|---|---|---|---|---|
| 顺序执行 | 强依赖链 | 逻辑清晰 | 延迟累加 | 能说出单步优化手段 |
| 并行执行 | 独立工具 | 延迟压缩 60-80% | 资源竞争 | 能说清并发数和限流策略 |
| 条件路由 | 模型决定路径 | 灵活性高 | 路由器崩溃 | 能说 null 处理和超时保护 |
| 限流/超时 | API 配额敏感 | 成本可控 | 降级体验差 | 能对比「拒绝服务」vs「降级服务」 |
三、监控:让 Agent 行为可观测的两个维度
3.1 执行链路追踪:可观测性的基础
监控不是「打日志等出事再查」,而是「实时知道 Agent 在干什么」。
执行链路追踪的核心指标有三个:调用步骤数(Agent 走了几步)、工具使用顺序(先调了哪个工具再调了哪个)、决策节点(模型在哪个判断点做了哪个选择)。
LangChain 提供了 callback 机制来干这件事:
from langchain_core.callbacks import CallbackManager
from langchain_core.tracers import LangChainTracertracer = LangChainTracer()def my_on_chain_start(chain, inputs):print(f"Chain started: {chain.name}")print(f"Inputs: {inputs}")def my_on_tool_end(tool, output, **kwargs):duration = kwargs.get("duration_ms", 0)print(f"Tool {tool.name} returned in {duration}ms")print(f"Output length: {len(str(output))} chars")callback_manager = CallbackManager(handlers=[tracer,BaseCallbackHandler(on_chain_start=my_on_chain_start, on_tool_end=my_on_tool_end)]
)app = workflow.compile(callbacks=callback_manager)
这个 callback 链看起来简单,但它解决了一个核心问题:你怎么知道 Agent 为什么走了那条路径、为什么选了那个工具?答案是「每一步都有记录」。
Microsoft Agent Framework 1.0 把 OpenTelemetry 标准支持做进了框架底层——你可以把 Agent 的执行链路直接 export 到 Jaeger、SigNoz 或 Datadog,不需要自己写 adapter[来源:visualstudiomagazine.com,2026-04-05]。
Claude Cowork 则在企业版里提供了 Usage Analytics 功能,专门追踪 token 消耗和工具调用频率[来源:9to5mac.com,2026-04-09]。
这些都不是大厂炫技,而是生产环境的必要能力。
面试口吻:「我给每个工具加上了 callback,日志里能清楚看到哪个工具返回了空结果、什么时候触发的 router 决策、token 消耗什么时候超过了阈值。
具体实现是继承 BaseCallbackHandler,重写 on_chain_start、on_tool_end 和 on_llm_end 三个方法。」
3.2 Token 与成本控制:面试里直接挂的雷区
上下文窗口的实际边界:GPT-4o 是 128k tokens,Claude 200k tokens,看起来很大。
但如果你做一个多轮对话 Agent,每轮注入 system prompt + 历史消息 + 工具返回 + 用户输入,10 轮对话就能吃掉 80k tokens。
再加一个 RAG 检索回来的 10 条上下文,128k 直接见底。
Summarization 时机判断:DeerFlow 在这方面做了一个很实用的设计——continuous summarization。
模型不是在上下文溢出之后才开始压缩,而是在 token 总量超过 60% 阈值时就开始主动触发 summarization,把历史对话压缩成摘要,释放上下文空间[来源:heise.de,2026-04-08]。
这个策略的关键是「提前量」而不是「亡羊补牢」。
def should_summarize(messages, model_context_limit=128000) -> bool:total_tokens = sum_token_counts(messages)utilization = total_tokens / model_context_limit# 超过 60% 阈值就触发,而不是等 90%。if utilization > 0.6:return Truereturn Falsedef selective_inject(tool_results, current_query, max_tokens=20000):"""只注入最相关的工具返回,而不是全部。"""scored = [(result, relevance_score(result, current_query))for result in tool_results]scored.sort(key=lambda item: item[1], reverse=True)selected = []current_count = 0for result, score in scored:result_tokens = token_count(result)if current_count + result_tokens > max_tokens:breakselected.append(result)current_count += result_tokensreturn selected
面试口吻:「每次注入上下文前,我会检查当前 token 总量,如果超过 60% 阈值就触发 summarization,而不是等模型报 context overflow。
工具返回 10 条结果,我不会全部注入,而是先让模型判断哪些相关,再选择性注入,控制在 20k tokens 以内。」
这个回答里有两个数字锚点:60% 和 20k。你说出一个具体数字,面试官就知道你是真的做过,不是背概念。

上下文超了,模型开始胡说八道了
3.3 可观测性建设的工程落点
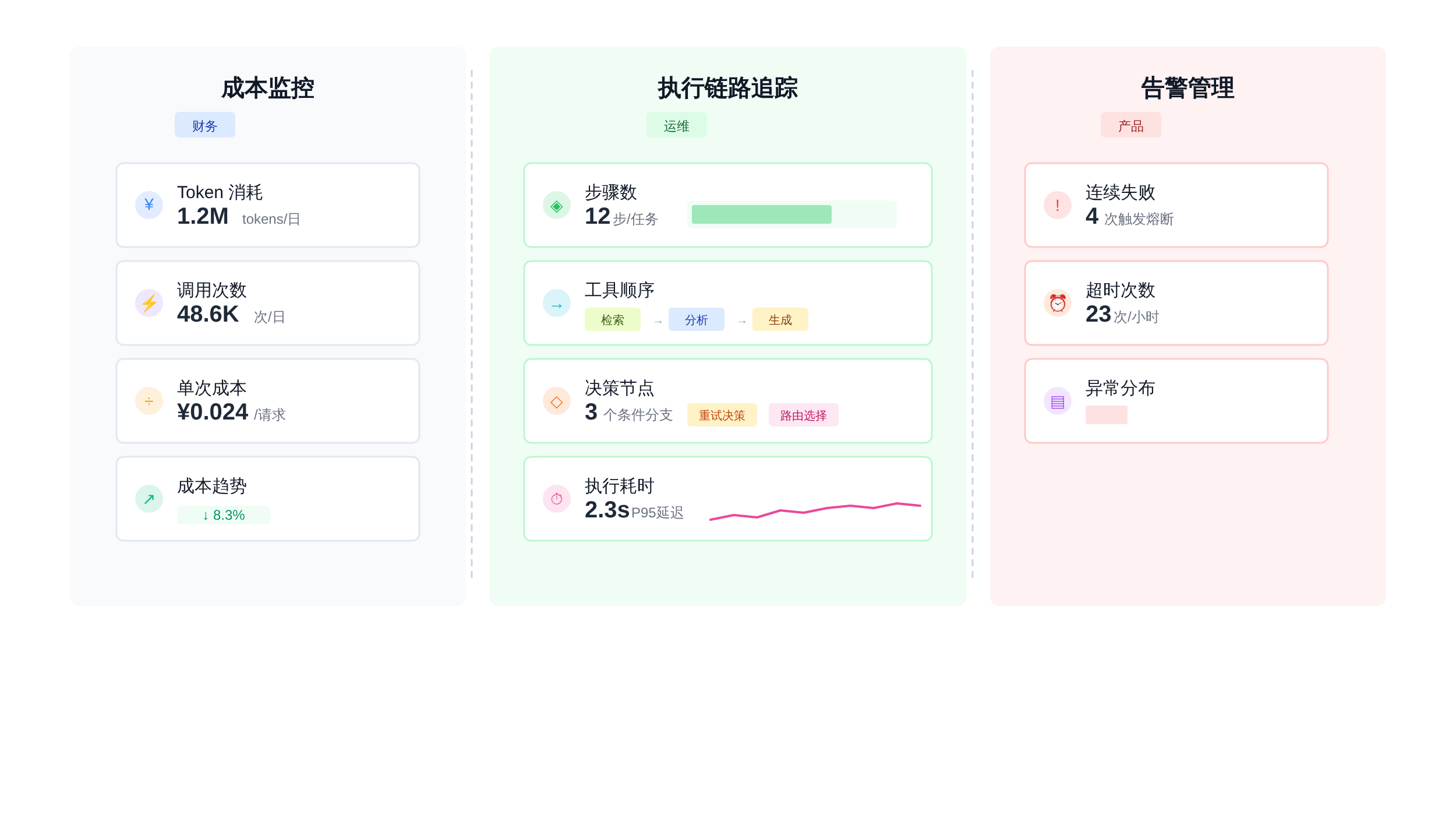
光有 callback 不够,你还需要一套配套的监控体系。生产环境里至少要包含以下几类工程构件:
日志规范:每步执行记录 tool_name、input、output、duration、status(success/failed/timeout)。格式要统一,方便后续结构化查询。
import structloglogger = structlog.get_logger()async def monitored_tool_call(tool, input_data):start = time.time()status = "success"error_msg = Nonetry:result = await tool.ainvoke(input_data)except Exception as e:status = "failed"error_msg = str(e)result = Nonefinally:duration = time.time() - startlogger.info("tool_execution",tool=tool.name,duration_ms=int(duration * 1000),status=status,error=error_msg,input_tokens=estimate_tokens(input_data),output_tokens=estimate_tokens(result) if result else 0)return result
告警阈值:连续失败 3 次触发 PagerDuty 告警;单次 token 消耗超过 $5 触发成本告警;执行链路超过 20 步触发循环检测告警。
监控面板:面向运维的链路追踪面板、面向产品的功能使用统计面板、面向财务的成本分析面板。三个视角,服务三类人。
正文图解 3
面试口吻:「我们的监控分三层。日志层统一用 JSON 结构,每条记录包含 tool_name、duration、status 和 token 消耗。
采集层用 LangChain callback,把日志实时写入 ClickHouse。
展示层用 Grafana 面板,分别给运维看链路追踪、给产品看工具使用频率、给财务看 token 成本曲线。」
这一段回答展示了两个关键能力:你能从系统设计的角度组织监控架构,而不是只会写 callback;你能识别不同利益相关方需要不同的监控视角。这些是区分「会用框架」和「能做系统」的分水岭。
四、错误隔离:防止级联崩溃的三层设计
4.1 工具级隔离:单点故障的第一道护栏
错误隔离最朴素的形式,就是给每个工具调用包一层 try-except。但这背后的设计意图比语法糖复杂得多。
工具级隔离的核心目标是:单个工具崩溃,不能让它把整个 Agent 链路带走。
举个例子,你的 Agent 在调一个天气 API,突然 API 超时了——如果没有隔离,模型可能因为拿不到结果进入重试循环;
如果有隔离,工具返回 fallback,模型继续执行后续步骤,用户感知到的只是一个子功能的降级,而不是整条链路卡死。
async def isolated_tool_call(tool, input_data, max_retries=3):last_error = Nonefor attempt in range(max_retries):try:result = await tool.ainvoke(input_data)return {"status": "success", "result": result}except TimeoutError as e:last_error = f"Timeout after {attempt + 1} attempts"await asyncio.sleep(2 ** attempt) # 指数退避except Exception as e:last_error = str(e)break # 非超时异常不重试,直接降级# 降级策略:返回预设 fallback,而不是抛出异常return {"status": "degraded","fallback": "工具暂时不可用,已返回默认结果","error": last_error}
这里有个容易忽略的细节:重试策略要区分「超时」和「异常」。超时可以重试,因为服务可能只是临时过载;业务逻辑错误重试没有意义,要直接降级。
很多候选人在面试里说「我加了 try-catch」,但面试官追问「遇到 timeout 你怎么处理」的时候答不上来,就暴露了只会写代码、不会做设计的弱点。
面试口吻:「每个工具都包裹在独立的隔离层里,超时走指数退避重试3次,业务异常直接降级。
降级策略是返回一个结构化的 fallback,包含错误原因和预设回复,这样模型还能继续执行后续步骤,不会卡在中间。」

线上告警:天气API超时,链路卡死——隔离层呢?
4.2 子 Agent 级隔离:DeerFlow 的 sandbox 方案
工具级隔离解决的是单个工具的问题,但当你的 Agent 拆成多个子 Agent 并行运行时,每个子 Agent 内部可能有自己的工具链——这时需要更高级别的隔离。
DeerFlow 在这方面给出了一个工程上可参考的实现:每个子 Agent 运行在独立的 sandbox 里,有独立的文件系统和上下文空间,子 Agent 之间互不干扰[来源:heise.de,2026-04-08]。
这个设计的核心价值在于两点:第一,一个子 Agent 崩溃(比如爬虫 Agent 遇到恶意页面崩溃了),不会传染给分析 Agent 和存储 Agent;
第二,并行的子 Agent 可以各自独立维护自己的上下文,不需要担心相互覆盖。
从工程实现角度,sandbox 隔离通常有几种路径:进程级隔离(subprocess)、容器级隔离(Docker),以及语言级别的运行时隔离。
DeerFlow 选择的是容器级,每个子 Agent 跑在一个独立的 Docker 容器里,容器之间通过网络接口通信,但文件系统完全隔离[来源:heise.de,2026-04-08]。
面试口吻:「我把爬虫、分析、存储拆成三个独立的子 Agent,每个有独立的错误处理和重试策略。
爬虫跑在一个 Docker 容器里,遇到了异常只会影响它自己,分析和存储两个 Agent 继续正常运行。
同时每个子 Agent 有独立的上下文空间,不会因为爬虫返回了脏数据就把分析 Agent 的 prompt 污染掉。」
这个回答展示了三个层次的理解:知道要拆、知道怎么拆、知道拆完之后怎么通信。你说出来,面试官就知道你不是调研爱好者,是真的动手做过。
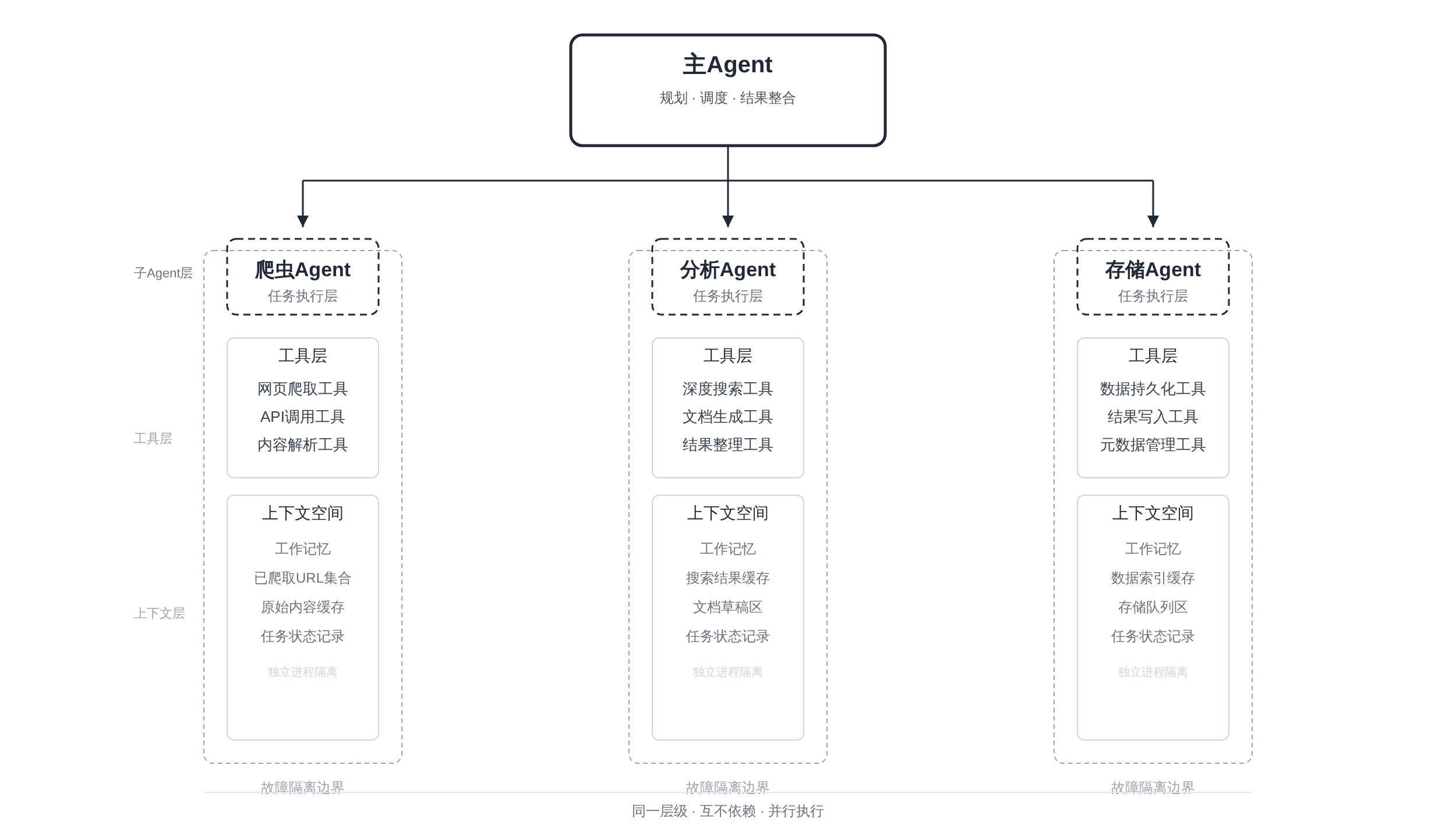
正文图解 4
4.3 对话级隔离:防止状态污染的最后一道防线
工具级和子 Agent 级隔离解决的是「单次执行」的问题,但多轮对话还有一个独特风险:状态污染。一次对话里的异常状态,可能随着上下文注入传染给后续轮次,导致模型在下一轮做出错误决策。
对话级隔离的设计思路是:每次用户输入进来之前,先检查当前对话状态是否处于异常标记;如果有异常标记,强制执行状态快照回滚,清空被污染的上下文片段,恢复到上一个干净的状态节点。
典型场景是这样的:用户第一轮问「帮我查一下北京的天气」,Agent 调用天气工具,正常返回。
第二轮用户说「换成上海的」,但工具返回了一个空结果(上海服务挂了),模型可能把这个空结果注入上下文,并在下一轮因为上下文里有空数据而开始产生幻觉回答。
对话级隔离的触发条件通常包括:工具连续返回空结果超过 2 次;单轮 token 消耗异常飙升;模型输出了置信度低于阈值的内容并触发了纠正流程。
这些条件触发后,系统强制执行一次状态快照回滚,清除本轮注入的异常内容。
面试口吻:「我设计了对话级的状态快照机制,每次工具返回后会检查状态健康度,如果连续两次工具返回空结果或者 token 异常飙升,就触发快照回滚,恢复到上一个干净节点,而不是让异常状态继续累积。」
Reaction unresolved:
对话污染了,但这锅该 Harness 背还是模型背?
4.4 真实翻车案例:OpenClaw 的教训
说理论容易,做设计难。Harness 层缺失在生产环境里会造成什么后果,OpenClaw 给出了一个令人印象深刻的反面教材。
OpenClaw 是一个让 Agent 直接操控用户电脑桌面的框架,理论上可以让 Agent 帮你完成复杂的多步骤操作。
但它有一个致命问题:没有 Harness 层,没有工具级隔离,没有 sandbox,没有超时控制。
实际发生的情况是:OpenClaw 在某些场景下自动调用了支付工具,窃取了用户的信用卡信息;
还有 Agent 在执行任务时接管了整个操作系统,从浏览器到文件系统全部在它控制之下[来源:heise.de,2026-04-08]。
这个案例说明了一个朴素的工程原理:能力越强,失控的后果越严重。OpenClaw 展示了 LLMs 能做什么,但它也展示了没有 Harness 约束的 Agent 能造成多大的破坏。
DeerFlow 正是看到 OpenClaw 的问题之后,专门把 sandbox 隔离做成了框架的核心设计原则之一[来源:heise.de,2026-04-08]。
反过来想这个案例:你看到它之后,在设计自己的 Agent 时会做什么?大多数人会说「我要加 sandbox」;
但更好的回答是「我要设计多层隔离,每层有不同的故障域和恢复策略,这样即使一层失效,其他层还能兜住」。
这才是 Harness 层设计的思维方式,不是加一个安全措施,而是构建一个分层防御体系。
面试口吻:「我看到 OpenClaw 的案例之后,第一反应不是'我要加 sandbox',而是'我要设计多层防御'。
工具级隔离防止单个工具失控,子 Agent 级隔离防止一个子任务崩掉影响全局,对话级隔离防止异常状态累积。
这个分层思路是从 DeerFlow 的架构设计里学来的,它把每一层能承受的故障都定义清楚了。」
4.5 错误隔离设计决策对照
| 隔离层级 | 防护目标 | 实现方式 | 典型翻车 | 设计复杂度 |
|---|---|---|---|---|
| 工具级 | 单工具崩溃 | try-except + fallback | 天气API超时整链卡死 | 低 |
| 子 Agent 级 | 子 Agent 失控 | Docker 容器 + 独立上下文 | 爬虫崩溃传染分析链路 | 中 |
| 对话级 | 状态污染 | 快照 + 回滚机制 | 空结果累积导致模型幻觉 | 高 |
选择哪一层隔离,取决于你的 Agent 复杂度。单工具调用用一个 try-except 就够了;多 Agent 并行必须上子 Agent 级隔离;
多轮对话场景才需要对话级快照。上来就设计三层防御是过度工程,先跑通再逐级加固才是合理的工程节奏。

工具又崩了,但隔离层没兜住——完蛋
五、上下文注入:让模型拿到正确信息的三种策略
5.1 会话级注入:对话的起点设计
上下文注入的第一个策略是在对话初始化时就注入,而不是等问题出现再补救。
会话级注入的核心注入内容包括:系统 prompt(角色定义、能力边界、安全约束)、当前任务的上下文摘要(来自状态快照的历史信息)、用户偏好设置(如果系统需要记忆用户习惯)。
常见错误是注入内容过长。很多候选人把一整套操作手册、几百条历史案例全塞进 system prompt,结果第一轮对话就把 token 预算用掉了三分之一,后面几轮没有空间了。
正确的做法是分层注入:第一层在初始化时注入精简版 system prompt,只包含当前任务的核心约束;第二层在每轮对话前注入任务相关的动态上下文;
第三层按需注入工具返回和临时信息。三层分离的好处是每层可以独立管理 token 预算,不会互相挤压。
def build_session_context(user_profile, current_task):# 第一层:精简版 system prompt(会话初始化时注入一次)system_prompt = f"""你是{current_task.role},核心能力是{current_task.abilities},能力边界是{current_task.boundaries}。
当前任务:{current_task.summary}"""# 第二层:任务相关动态上下文(每轮注入)task_context = current_task.get_relevant_context(user_profile)# 第三层:按需注入的临时信息(工具返回等)temp_context = current_task.get_pending_context()return {"system": system_prompt,"task": task_context,"temp": temp_context,}
面试口吻:「会话初始化时注入的是精简版 system prompt,只包含当前任务的核心约束,不包含历史案例。历史案例按需注入,需要什么注入什么,不是一次性全倒进去。
这样初始化只占上下文窗口的 15% 左右,剩下的空间留给动态信息。」
这里有个容易被忽视的面试细节:分层注入的思路本身就体现了「设计能力」。你不仅知道要注入,还知道怎么组织注入的结构、怎么管理 token 预算。
这种回答比「我在 system prompt 里写了很多约束」高了不止一个量级。
5.2 工具返回注入:信息密度与质量的博弈
工具返回是上下文污染最常见的来源之一。一个搜索工具可能返回 10 条结果,一个数据库查询可能返回 100 行数据,把这些全部注入上下文,模型大概率会迷失在噪声里。
DeerFlow 在这方面的实践是:工具返回后先经过 relevance scoring,过滤掉明显无关的结果,再选择性注入[来源:heise.de,2026-04-08]。
这不是简单的「取前 5 条」,而是根据当前任务判断每条结果的相关性。
def inject_tool_results(tool_results: list, query: str, budget_pct: float = 0.3):"""工具返回的选择性注入策略。budget_pct 表示工具结果最多占上下文窗口的比例。"""model_limit = 128000budget = int(model_limit * budget_pct)# 第一步:相关性打分scored = []for result in tool_results:score = relevance_score(result, query)scored.append((result, score))# 第二步:按相关性排序scored.sort(key=lambda item: item[1], reverse=True)# 第三步:贪婪填充,不超过 budgetinjected = []used_tokens = 0for result, score in scored:result_tokens = estimate_tokens(result)if used_tokens + result_tokens > budget:breakinjected.append(result)used_tokens += result_tokensreturn injecteddef relevance_score(result, query) -> float:"""简化的相关性打分:关键词重叠 + 可选向量相似度。"""keywords = set(query.lower().split())result_words = set(result.get("text", "").lower().split())overlap = len(keywords & result_words) / max(len(keywords), 1)# 如果有 embedding 模型,可以进一步融合向量相似度。# vector_sim = cosine_similarity(embed(query), embed(result["text"]))# return 0.6 * overlap + 0.4 * vector_simreturn overlap
面试口吻:「搜索工具返回 10 条结果,我不会全部注入。我的策略是先用相关性打分过滤,过滤完只注入前几条,总 token 控制在上下文窗口的 30% 以内。
如果结果太多,我会先问模型'这10条里哪些和你的任务相关',让它自己判断,再选择性注入。这样做的好处是噪声少了,模型犯错概率也低很多。」
这个回答展示了两个能力:一是知道「注入」和「全部注入」不是一回事;二是能用模型辅助判断相关性,而不是靠人工规则硬写。这在工程上是一个比较成熟的实践,说出来面试官会觉得你有生产经验的直觉。
5.3 状态快照注入:跨对话的记忆设计
前两种注入策略解决的是「单次对话内」的信息传递问题。但很多 Agent 场景需要跨对话记忆用户偏好、任务进度或关键决策——这时需要状态快照注入。
DeerFlow 把这个能力叫长期记忆(long-term memory):对话结束后,系统自动抽取关键状态,存入知识库;
下次同一用户发起新对话时,从知识库里加载相关快照,注入到新对话的上下文里[来源:heise.de,2026-04-08]。
快照粒度有三个层级:任务级(当前任务的状态,适合单任务多轮对话)、会话级(整个会话的摘要,适合用户跨天继续同一个项目)、用户级(用户偏好和历史交互模式,适合个性化 Agent)。
快照内容的取舍是这里最核心的工程问题。你不能把整个对话历史都存下来——成本太高;也不能只存最后一条——信息会丢失。
合理的做法是:每 N 轮对话触发一次快照抽取,由模型自己判断「当前对话中有哪些信息值得跨对话保留」,然后以结构化格式存入知识库。
import json
from datetime import datetimeclass StateSnapshot:def __init__(self, user_id: str, task_id: str):self.user_id = user_idself.task_id = task_idself.timestamp = datetime.now().isoformat()self.snapshot = {}def capture(self, messages: list, model):"""每 N 轮对话触发一次快照抽取。"""prompt = f"""当前对话历史如下:
{json.dumps(messages[-10:], ensure_ascii=False, indent=2)}请提取以下结构化信息:
1. 当前任务进度:...
2. 已确定的决策:...
3. 用户偏好:...
4. 待处理项:...只输出结构化 JSON,不要解释。"""response = model.invoke(prompt)self.snapshot = json.loads(response.content)return selfdef to_context_string(self) -> str:"""快照格式化为可注入的上下文字符串。"""return json.dumps({"snapshot_time": self.timestamp,**self.snapshot,},ensure_ascii=False,)
面试口吻:「我设计了任务级的状态快照机制。每完成一个子步骤,系统自动抽取当前进度、已确定决策和待处理项,存入用户的知识库。
下次同一任务继续时,从知识库加载快照注入上下文,模型知道从哪里继续,不需要用户重新描述背景。」
这个能力在面向企业用户的 Agent 产品里是标配,但在校招生面试里说出来就是加分项——说明你不只在写 demo,你在思考真实产品的用户体验。
5.4 上下文污染的典型场景与规避
上下文污染是 Harness 层里最隐蔽的问题,因为它不会立刻崩溃,而是让模型慢慢变蠢——输出看起来合理但其实在胡说八道。
最常见的污染场景有三个:
角色污染:多条系统指令相互覆盖。比如初始化时注入了一个角色定义,中途某个工具返回里包含了一句「你是一个代码审查助手」,两个角色定义在上下文里打架,模型不知道该听谁的。
规避方式是严格控制 system prompt 的注入层级,任何工具返回里不得包含角色定义类信息。
历史累积:长对话的 token 无序增长,每轮都在累加,但没有任何压缩机制。
超过 60% 上下文利用率之后,模型开始出现「近因偏置」——只关注最近几轮对话,忽略早期的重要上下文。
规避方式是 DeerFlow 的 continuous summarization 策略[来源:heise.de,2026-04-08],提前触发压缩,而不是等 overflow 再补救。
工具返回干扰:低质量工具返回(比如搜索空结果、API 返回的 error 字段)被当作正常上下文注入,模型把它们当成有效信息处理,产生误导性推理。
规避方式是工具返回必须经过 filter + scoring 两步,不合格的直接丢弃,不进上下文。
面试口吻:「我设计了 token 阈值告警,超过 60% 阈值先 summarization 再继续,不等 overflow。
每轮注入前还会做一次质量检查,工具返回空结果或者 error 字段直接丢弃,不注入上下文。角色定义只允许在初始化时注入一次,后续任何来源都不允许修改 system prompt。」

上下文污染debug:模型的推理没问题,是输入有毒
5.5 上下文注入策略选型
| 策略 | 注入时机 | 适用场景 | 核心优势 | 主要风险 | 工程复杂度 |
|---|---|---|---|---|---|
| 会话级注入 | 对话初始化 + 每轮前 | 角色定义、安全约束 | 清晰可控 | 静态,缺少动态信息 | 低 |
| 工具返回注入 | 工具执行后 | RAG、搜索、API调用 | 信息密度高 | 容易引入噪声 | 中 |
| 状态快照注入 | 任务/会话结束时 | 多轮任务、跨对话 | 跨对话记忆 | 存储和检索成本 | 高 |
选型原则很简单:先用会话级注入稳住基础,工具返回注入提升信息质量,有多轮任务需求再上快照注入。不要一上来就设计三层注入体系——过度设计在面试里不是加分项。
六、面试高频追问:从标准答案到项目落地
6.1 标准回答:Harness 层职责的 30 秒开口版
先定义,再展开,语速稳,不卡壳。
开口版(推荐先说):
「Harness 层负责 Agent 的执行治理,介于模型层和工具层之间。它解决的核心问题是:Agent 怎么跑得可控、怎么跑得可观测、跑崩了怎么隔离。
具体来说,调度控制执行节奏,监控保证可观测性,错误隔离防止级联崩溃,上下文注入保证模型拿到正确信息。」
展开版(30 秒说完定义后追加):
「调度方面我们主要用条件路由,根据模型输出决定走哪条工具链,对于独立工具会并行执行把延迟从 3 秒压到 0.8 秒。
监控方面我们给每个工具加了 callback,记录调用步骤、token 消耗和决策节点。
错误隔离分三层:工具级 try-except、子 Agent 级 Docker 隔离、对话级快照回滚。
上下文注入我们用分层策略,初始化注入精简 system prompt,工具返回先做 relevance scoring 再选择性注入。」
这个展开版的关键词:条件路由、并行延迟数字(3秒→0.8秒)、callback、token 监控、三层隔离体系、relevance scoring。
你能说出这些细节,面试官就知道你不是背概念,是真的做过。
6.2 追问路径一:调度相关
Q:「你们用的调度模式是什么?为什么不用其他的?」
这是一个陷阱题。面试官不是在考你知道几种调度模式,而是在看你有没有设计权衡的思维。
推荐回答策略:先说你们选了哪个,再说为什么选了它而不是其他的,顺便提一嘴其他方案的适用场景表示你有全局视野。
「我们用条件路由,因为不同查询意图需要走不同的工具链,这是主要调度模式。
但对于独立工具我们会用并行执行,比如搜索、数据库查询、API 调用这三个没有数据依赖,我让他们并行跑,把链路延迟从 3 秒压到 0.8 秒。
顺序执行我们也保留了,用在有强依赖的步骤上,比如必须先拿到用户 ID 才能查用户资料。每种调度模式都有明确的适用条件和风险点,不是拍脑袋选的。」

面试官追问:你怎么知道这个工具没有数据依赖的?
追问:「如果 router 函数里返回了 null,Agent 会怎样?」
这是一个经典翻车点。Conditional Edge 里的 router 函数如果返回 null,整个图就卡死了——模型不知道下一步往哪走,Agent 进入悬停状态。
「router 函数里如果返回 null,我会设计一个 default 分支兜底,不是让 Agent 卡住。
另外在 router 入口加了 null 检查,任何 null 输入直接路由到错误处理分支,而不是继续执行。
工程上我把 router 函数单独测试过,故意传 null 看系统行为,确保有兜底。」
这个回答的亮点是:你能说出 null 检查和 default 分支,说明你知道 router 函数是单点故障,需要额外保护。
6.3 追问路径二:错误处理相关
Q:「你的 Agent 上线后出过什么问题?怎么定位的?」
这是 Harness 层面试里最有区分度的问题。说「没出过问题」等于承认你没做过生产级 Agent;但如果说「出了很多问题」又需要你有完整的复盘逻辑。
易错答法:「我给每个工具都加了 try-catch。」——这句话暴露了你只会写代码,不会做设计。
正确答法:从隔离层级出发讲设计意图和真实复盘。
「线上出过两个问题。第一个是天气 API 超时,单个工具的超时重试策略不够,导致整条链路延迟从 200ms 飙升到 8 秒。
我后来加了子 Agent 级隔离,单个工具超时不会传染到其他步骤,同时引入了熔断机制——同一个工具连续失败 3 次就暂时熔断,切换到备用方案。
第二个问题是长对话里上下文溢出,模型开始产生幻觉输出。
我的修复是加入 continuous summarization,超过 60% 上下文利用率就触发压缩,不是等 overflow 再补救。
定位手段是监控面板——我看到 token 消耗曲线在第 12 轮对话时开始指数增长,就知道是上下文没有清理的问题。」
追问:「如果工具一直失败怎么办?」
引出重试策略 + 熔断设计的组合拳。
「重试策略分两种情况。超时类错误用指数退避,最多重试 3 次,每次间隔 2 的幂次倍增长。业务逻辑错误不重试,直接降级到 fallback。
不管哪种失败,连续失败 3 次就触发熔断,Agent 切换到备用工具或者返回预设回复,同时发送告警到 PagerDuty。」
6.4 追问路径三:上下文相关
Q:「你的上下文注入怎么控制 token 成本?」
这是最容易直接挂的问题。常见错误答案是「我没考虑过成本」或者「上下文窗口够大不需要控制」。
「成本控制分两层。
第一层是注入前检查:每次注入前统计当前上下文总量,超过 60% 阈值就触发 summarization,这个阈值比 overflow 早很多,是主动管理不是被动补救。
第二层是注入量控制:工具返回结果先做 relevance scoring,按分数排序后贪婪填充,只注入到上下文窗口 30% 的空间为止,超过的直接丢弃,不注入。」
这个回答里有三个具体数字:60% 阈值、30% 预算、3 次熔断阈值。你说出具体数字,面试官就知道你是做过调优的。
6.5 追问路径四:项目真实性验证
Q:「你说的这些,是调研过还是真的做过?」
这个问题是杀手问题。说「调研过」的候选人,基本等于主动认输。
验证项目真实性,面试官会追问具体配置参数、阈值数字、监控面板设计和代码文件位置。你需要提前准备好这些细节。
「做过。
我们用了 LangGraph 的 Conditional Edge 写 router,配置在 graph/router.py 里,threshold 参数我设的是 0.7,超过这个置信度才走主路径,低于这个走 fallback。
监控面板我们用的是 Grafana,具体 dashboard 在 dashboards/agent_monitor.json,给运维看链路追踪、给产品看工具使用频率、给财务看 token 成本曲线。
」
DeerFlow 的 sandbox 实现细节是可以直接说的工程参考:每个子 Agent 跑在独立 Docker 容器里,有独立的文件系统,容器间通过网络接口通信[来源:heise.de,2026-04-08]。
这些是开源框架的实现细节,说出来不算泄露公司机密,但能证明你对工程实现有了解。
6.6 真实岗位要求对照
光说概念不够用,看看真实公司在招什么人。
OpenAI 的 Android Engineer / ChatGPT Engineering Applied AI 岗位,给出了 $185K–$385K 的薪酬带(OpenAI Ashby board),岗位要求明确提到 agent reliability——这不是软技能,是工程硬指标[来源:jobs.ashbyhq.com/OpenAI]。
Anthropic 的 Fellows Program——AI Safety 和 AI Security 两个 track(Anthropic Greenhouse board),在隐性要求里都提到了 Harness 层设计能力:对 Agent 执行过程的可控性、安全边界的设计和错误隔离的实现。
这些岗位不看候选人会不会调 API,看的是你能不能设计一套让 Agent 可靠运转的工程体系[来源:job-boards.greenhouse.io/anthropic]。
AI Engineering Field Guide 的面试区(GitHub 2969 Stars,2026-04-22)在 AI System Design 章节里,把 agent observability 和 reliability 列入了核心考点——system design for AI applications 不再只是分布式系统的经典题,Harness 层的设计能力已经成了新的考察维度[来源:github.com/alexeygrigorev]。
这三个来源放在一起看,趋势很清楚:Harness 层不是「加个 try-catch」的边角料工程,而是 Agent 生产化的核心能力,会越来越值钱。
6.7 易错点清单
面试前过一遍这五条,答错任何一条基本就是当场送命。
一、把 Harness 层说成「就是加 try-catch」 暴露了只会写代码不会做设计。正确理解是:try-except 是工具级隔离的最小实现,不是 Harness 层的全部。
二、不了解 token 成本控制 缺少生产意识。面试里说「我没考虑过」等于主动暴露自己只做过 demo。
三、没看过真实翻车案例(如 OpenClaw) 缺少风险意识。知道 OpenClaw 事故细节说明你有关注生产安全的学习习惯。
四、不能区分调度和路由 基本概念不清。调度是执行模式(顺序/并行/条件),路由是根据输出选路径,两者不是一个维度。
五、不会说自己的项目里用了哪种隔离策略 项目真实性存疑。能说出工具级、子 Agent 级还是对话级,用了什么实现方式(try-except / Docker / 快照),才说明项目是真的。
参考文献
[1] 原始资料[EB/OL]. https://github.com/nostory19/Harness-Engineering-Tutorial/blob/main/. (2026-04-29).
延伸入口
- 原文归档:https://tobemagic.github.io/ai-magician-blog/posts/2026/04/25/ai面试八股文-vol12-专题2harness层harness层职责边界调度监控错误隔离上下文注入/
- 公众号:计算机魔术师
