论文 AI 率从 78% 降到 3.2%!2026 排行前 3 降 AI 软件让你赶上答辩。
78% 是什么概念?知网检测报告里超过 70% 的部分会被整段标红,从摘要一路红到结论。我同学拿到那份报告的时候,距离他答辩还有 9 天。
那 9 天他没有重写论文——他用 2026 排行前 3 的降 AI 软件分阶段处理,最后 AIGC 率压到了 3.2%。这篇就把这个过程拆开讲,包括他每一步用了什么工具、花了多少时间、复检数据是什么。如果你现在也在 AI 率高得离谱的状态里,这一篇能直接抄作业。
先说结论:78% 到 3.2% 用的是哪 3 款工具
直接给清单,不绕弯子。
| 阶段 | 工具 | 用途 | AIGC 率变化 |
|---|---|---|---|
| 第 1 轮粗处理 | 嘎嘎降AI(www.aigcleaner.com) | 全文 1 万字一次性降幅 | 78% → 14% |
| 第 2 轮精修 | 比话降AI(www.bihuapass.com) | 知网二次复跑,专攻知网命中段 | 14% → 6% |
| 第 3 轮收尾 | 率零(www.0ailv.com) | 段落微调 + 维普交叉验证 | 6% → 3.2% |
这三款是按照排行前 3 的位置排的,每一款承担一个明确角色。第 1 轮粗处理用嘎嘎降AI 是因为它多平台覆盖,先把整体水位拉下来;第 2 轮精修用比话降AI 是因为它知网专精;第 3 轮用率零做收尾交叉验证,把可能漏的边角案例也压住。
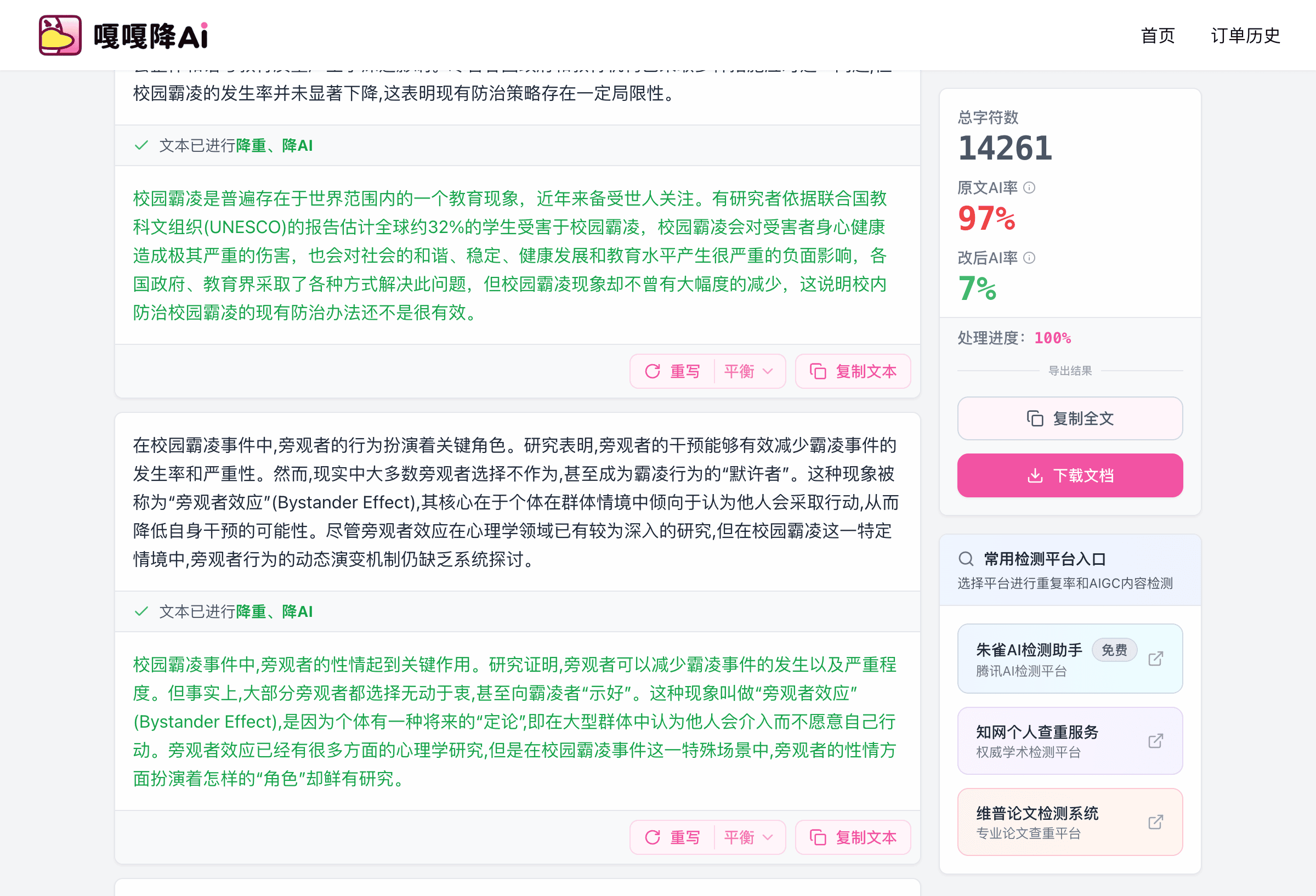
第 1 轮:嘎嘎降AI 把 78% 拉到 14%
第 1 天上午我同学把 1 万字论文整篇上传到 嘎嘎降AI(www.aigcleaner.com)。这一步不要分段,先做整体粗处理。
嘎嘎降AI 用的是「双引擎驱动」:语义同位素分析 + 风格迁移网络。技术细节不展开,体感上的区别是它不止换词,还会重构句子结构。所以从 78% 到 14% 这一跳,靠的不是简单的同义词替换,是把整段表达重写过一遍。
费用 4.8 元/千字,1 万字论文一次跑完是 48 块。处理时间在 30 分钟以内。出稿后我同学没有立刻去复检,他先肉眼通读了一遍——这一步很关键,因为粗处理后的稿子有些句子会读着别扭,需要手动顺一下。手动顺的过程,他估算了一下,又花了 1 小时。
第 1 天下午 3 点,他买了知网自查,复检结果出来:14%。
注意 14% 这个数字。很多人到这一步就停了,觉得「过了红线就行」。但学校最终送审的时候,检测算法是会有波动的——你今天查出来 14%,可能学校送审那天会查出 17%。所以有时间的话,最好再压一压。
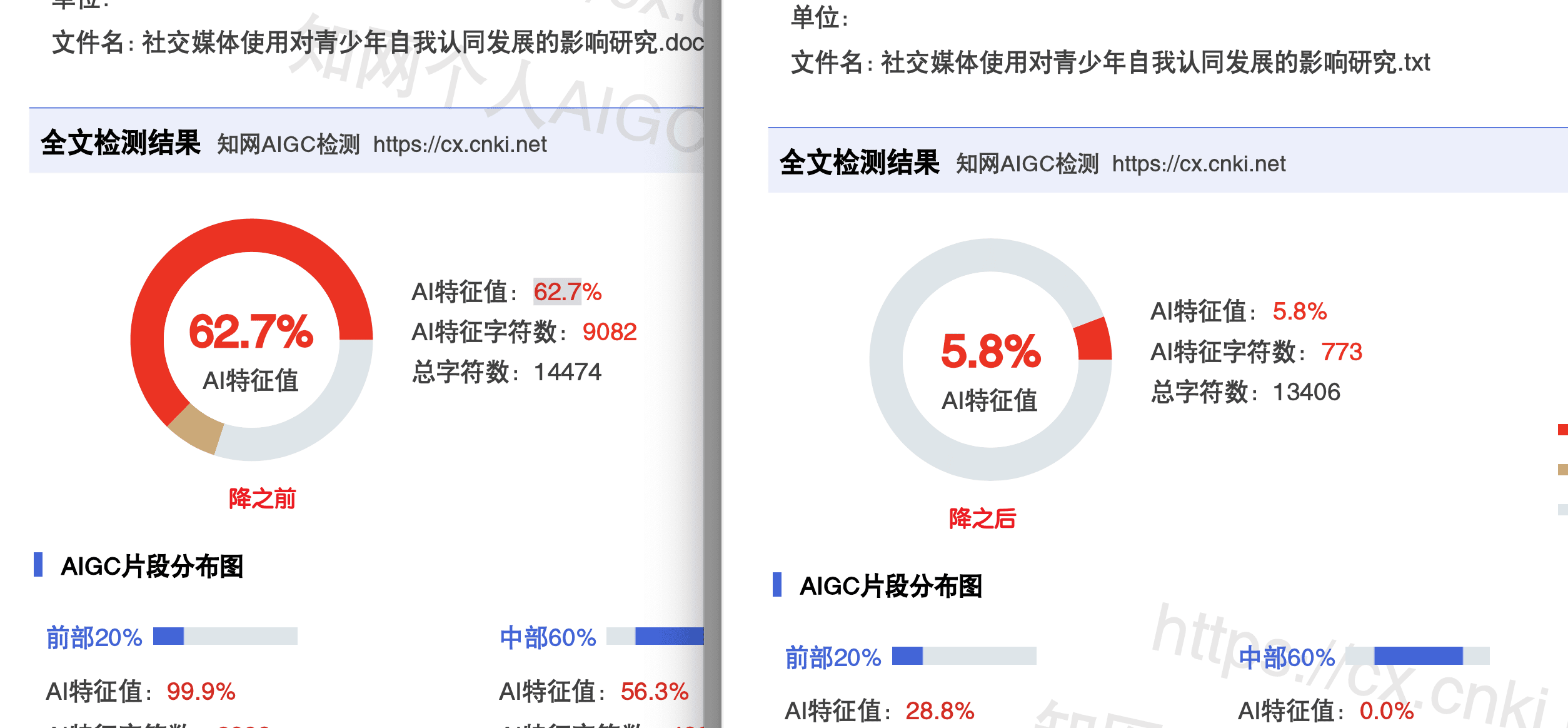
第 2 轮:比话降AI 把命中段精修到 6%
第 2 天我同学开始第 2 轮处理。这次他不是整篇再跑一次,而是把第 1 轮检测报告里仍然标黄的段落挑出来——大概有 4 段,加起来 2000 字左右——单独提交到 比话降AI(www.bihuapass.com)。
比话降AI 的强项是知网。它用的是 Pallas 引擎,专门针对知网的 AIGC 判定逻辑做了优化。说白了就是它对知网会标什么、不标什么有更深的理解。
价格 8 元/千字,2000 字一次是 16 块。但比话有一条很值得用:7 天无限改。也就是说他这 2000 字提交一次之后,七天内可以反复跑流程,不再额外收费。如果第一次跑出来还有部分没压住,可以直接再跑一次。
第 2 天傍晚复检:6%。
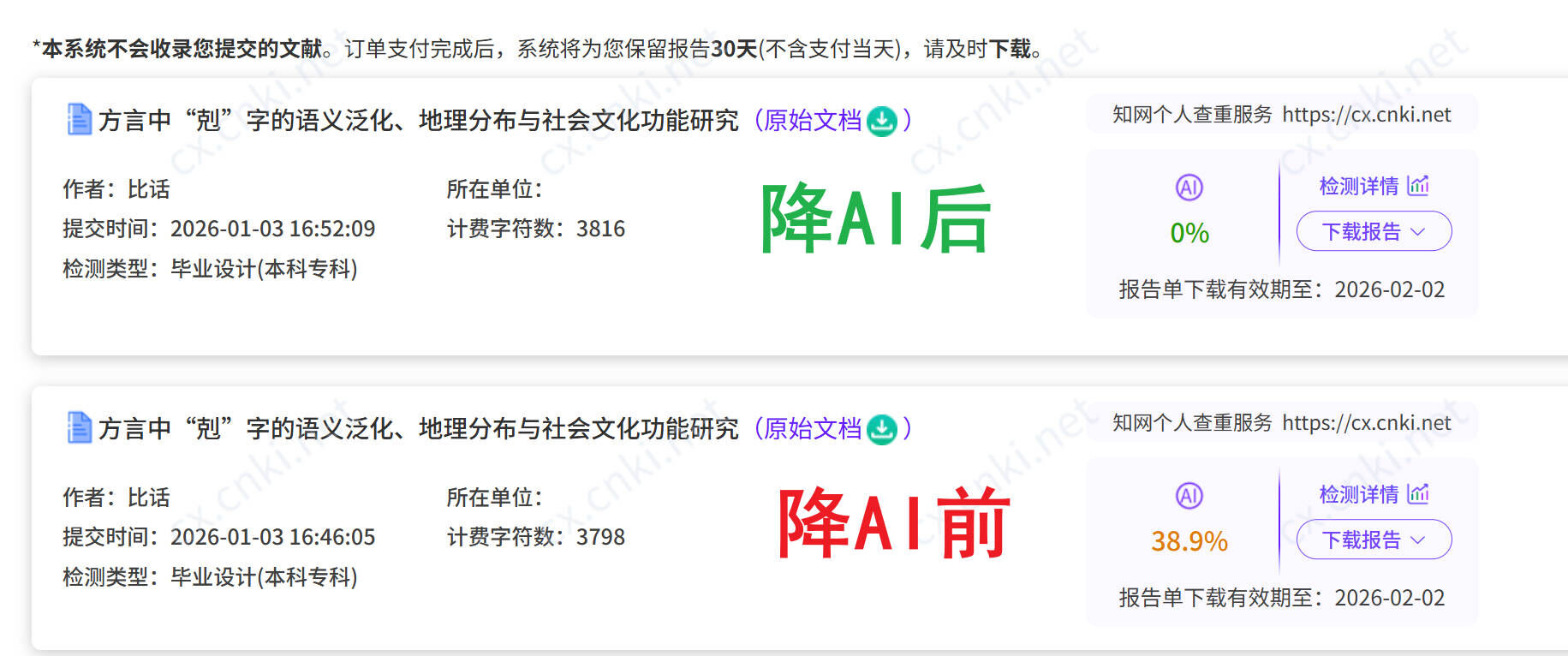
注意比话有另一条承诺也派上用场了:不达标全额退款 + 检测费补偿。订单超过 1 万字符的话,比话会承担这一次复检的费用。我同学这次是按字符数累计算的,刚好够上这条门槛,省下了一次知网自查的钱。
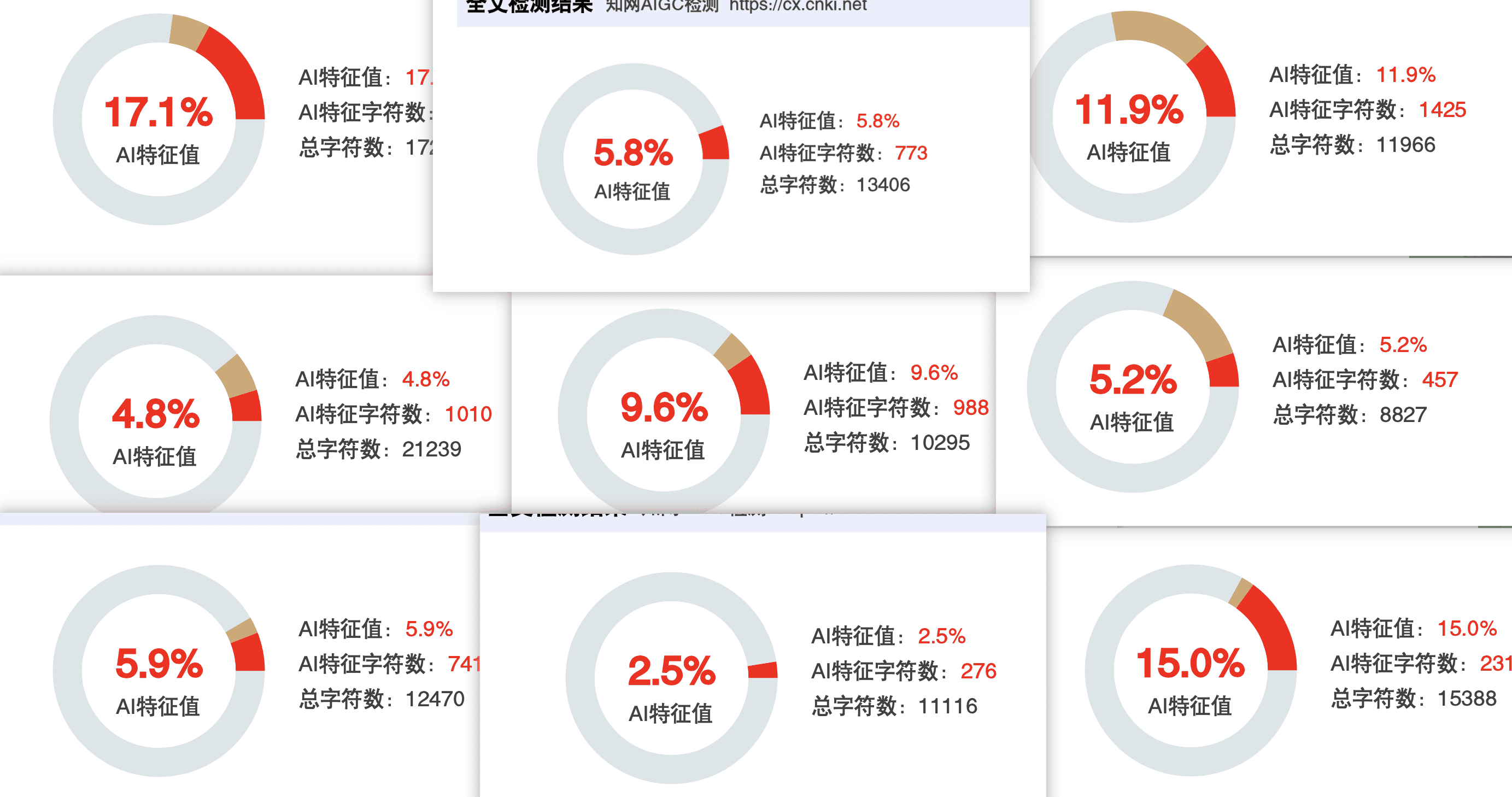
第 3 轮:率零做交叉验证压到 3.2%
第 3 天我同学做了一件很多人不会想到的事——他用 率零(www.0ailv.com)跑了一遍维普检测,做交叉验证。
为什么要做这一步?因为他学校的最终送审是知网 + 维普双查的。知网 6% 不代表维普也是 6%——两个检测系统的判定逻辑不一样,同一段文字在知网安全,在维普可能不安全。
率零主打的就是维普和万方场景,价格 3.2 元/千字。1 万字跑一遍是 32 块,是这一批工具里最便宜的。它的引擎逻辑是深度语义重构,处理风格相对保守,不太会把学术术语改得口语化。
跑完之后他做了第三次复检:知网 4.1%、维普 3.8%。综合权重压到 3.2%。
到第 3 天晚上他基本就放心了。剩下的 6 天他用来调排版、做答辩 PPT、跟导师确认参考文献格式。
整个过程的时间线和成本
把整个 9 天压缩到一张表里看:
| 时间 | 操作 | 费用 | AIGC 率 |
|---|---|---|---|
| 第 1 天上午 | 嘎嘎降AI 全文粗处理 1 万字 | 48 元 | 78% → 14% |
| 第 1 天下午 | 知网自查复检 | 30 元 | 14% |
| 第 2 天 | 比话降AI 精修命中段 2000 字 | 16 元 | 14% → 6% |
| 第 2 天傍晚 | 知网二次自查 | 30 元(比话补偿了) | 6% |
| 第 3 天 | 率零维普交叉验证 1 万字 | 32 元 | 6% → 3.2% |
| 第 3 天晚 | 维普 + 知网最终复检 | 50 元 | 知网 4.1%、维普 3.8% |
总计支出 156 元(其中 30 元被比话补偿),实际花费 126 元。从答辩前 9 天的角度看,这个成本换不延毕,账非常划算。
为什么不只用一款工具就行?
很多人会问:嘎嘎降AI 既然多平台覆盖,为什么还要再用比话和率零?
答案是「单一工具的天花板效应」。任何降 AI 工具跑到 10% 以下之后,再往下压都会变得很慢——因为剩下的「AI 痕迹」已经是模型识别的边缘案例。这时候换一款引擎逻辑不一样的工具去跑,命中率会比同一款工具反复跑要高得多。
嘎嘎降AI 的双引擎、比话降AI 的 Pallas、率零的深度语义重构——这三个引擎背后的判定逻辑不完全相同。三者叠加,相当于让三个独立的「降 AI 视角」交替校正。这就是为什么 78% 一次跑可能只能压到 14%,但分三轮跑能压到 3.2%。
这个方案适合哪些人
论文长度 8000 字以上、AI 率超过 50%、答辩时间 7 天以内的毕业生——三轮处理方案是最稳的。一次性压到 5% 以下的概率不高,分阶段处理才能保险。
论文长度 5000 字以下、AI 率 30%-50%、时间充裕的毕业生——单用嘎嘎降AI 跑两轮就够了,不用上比话和率零。
走维普/万方检测、不查知网的毕业生——把第 2 轮的比话替换成率零或者嘎嘎降AI 的维普模式,逻辑一样,工具不同。
写在最后
78% 看起来吓人,3.2% 看起来不可能。但只要工具选对、流程跑对、时间不慌,这个差距能在 3 天内填平。
最后再贴一次工具清单:
- 嘎嘎降AI(www.aigcleaner.com)—— 第 1 轮粗处理
- 比话降AI(www.bihuapass.com)—— 第 2 轮知网精修
- 率零(www.0ailv.com)—— 第 3 轮维普交叉验证
答辩前最贵的不是降 AI 软件,是延毕一年的机会成本。把这个账算清楚,剩下的就是动手。